BertWithPretrained
1.0.0
[中文 | الإنجليزية]
هذا المشروع هو تطبيق لنموذج BERT والمهام المرتبطة به على أساس إطار Pytorch. ويتضمن أيضًا شرحًا مفصلاً لنموذج BERT ومبادئ كل مهمة أساسية.
بيرت: ما قبل التدريب من محولات ثنائية الاتجاه العميقة لفهم اللغة
قبل تعلم استخدام هذا المشروع ، تحتاج إلى معرفة المبادئ ذات الصلة للمحول من خلال هذه الأمثلة الثلاثة: الترجمة ، التصنيف ، توليد الاقتران.
يحتوي bert_base_chinese على ملفات وملفات التدريب قبل التدريب Bert_Base_Chinese
يحتوي bert_base_uncased_english
تحتوي data على جميع مجموعات البيانات المستخدمة من قبل كل مهمة المصب.
SingleSentenceClassification هي مجموعة بيانات تصنيف صينية من 15 فئة من Toutiao.PairSentenceClassification هي مجموعة بيانات MNLI (مجموعة الاستدلال الطبيعية متعددة الأجيال).MultipeChoice هي مجموعة بيانات غنيمة.SQuAD هي مجموعة بيانات Squad-V1.1.WikiText هي مجموعة ويكيبيديا الإنجليزية للتدريب المسبق.SongCi هي بيانات Songci للنموذج الصيني قبل التدريبChineseNER هي مجموعة بيانات تستخدم لتدريب التعرف على الكيان الصيني. model هو تنفيذ كل وحدة
BasicBert يحتوي على تنفيذ Bert الأساسيMyTransformer.py تنفيذ الاكتتاب الذاتي.BertEmbedding.py إدخال تضمين تنفيذ.BertConfig.py المستخدمة لاستيراد تكوين config.json .Bert.py تنفيذ Bert.DownstreamTasks على جميع تنفيذ مهام المصبBertForSentenceClassification.py تنفيذ تصنيف الجملة (S).BertForMultipleChoice.py تنفيذ الاختيار من متعدد.BertForQuestionAnswering.py سؤال سؤال (نص تمتد).BertForNSPAndMLM.py NSP وتنفيذ MLM.BertForTokenClassification.py تنفيذ تصنيف الرمز المميز. تنفيذ Task للتدريب والاستدلال لكل مهمة في اتجاه مجرى النهر
TaskForSingleSentenceClassification.py taks من تنفيذ تصنيف الجملة الفردية مثل تصنيف الجملة.TaskForPairSentence.py مهمة تنفيذ تصنيف الجملة للزوج مثل MNLI.TaskForMultipleChoice.py مهمة تنفيذ الاختيار من متعدد مثل SWAG.TaskForSQuADQuestionAnswering.py Task OS سؤال الإجابة على (SPAN SPAN) مثل SQUAD.TaskForPretraining.py لتنفيذ NSP Ans MLM.TaskForChineseNER.py مهمة تنفيذ التعرف على الكيان الصيني. test حالات اختبار كل مهمة المصب.
utils
data_helpers.py هي وحدة بناء مجموعة البيانات وبيانات البيانات لكل مهمة المصب ؛log_helper.py هي وحدة طباعة السجل.creat_pretraining_data.py المستخدمة لبناء مجموعة بيانات مهمة التدريب قبل Bert. بيثون 3.6 ونسخة الحزم
torch == 1.5 . 0
torchtext == 0.6 . 0
torchvision == 0.6 . 0
transformers == 4.5 . 1
numpy == 1.19 . 5
pandas == 1.1 . 5
scikit - learn == 0.24 . 0
tqdm == 4.61 . 0 تنزيل كل مجموعة بيانات ونموذج Bert PretRained المقابل (إذا كان فارغًا) ووضعه في الدليل المقابل. للحصول على التفاصيل ، راجع ملف README.md في كل دليل بيانات ( data ).
الذهاب إلى دليل Tasks وتشغيل النموذج.
بنية النموذج ومعالجة البيانات:
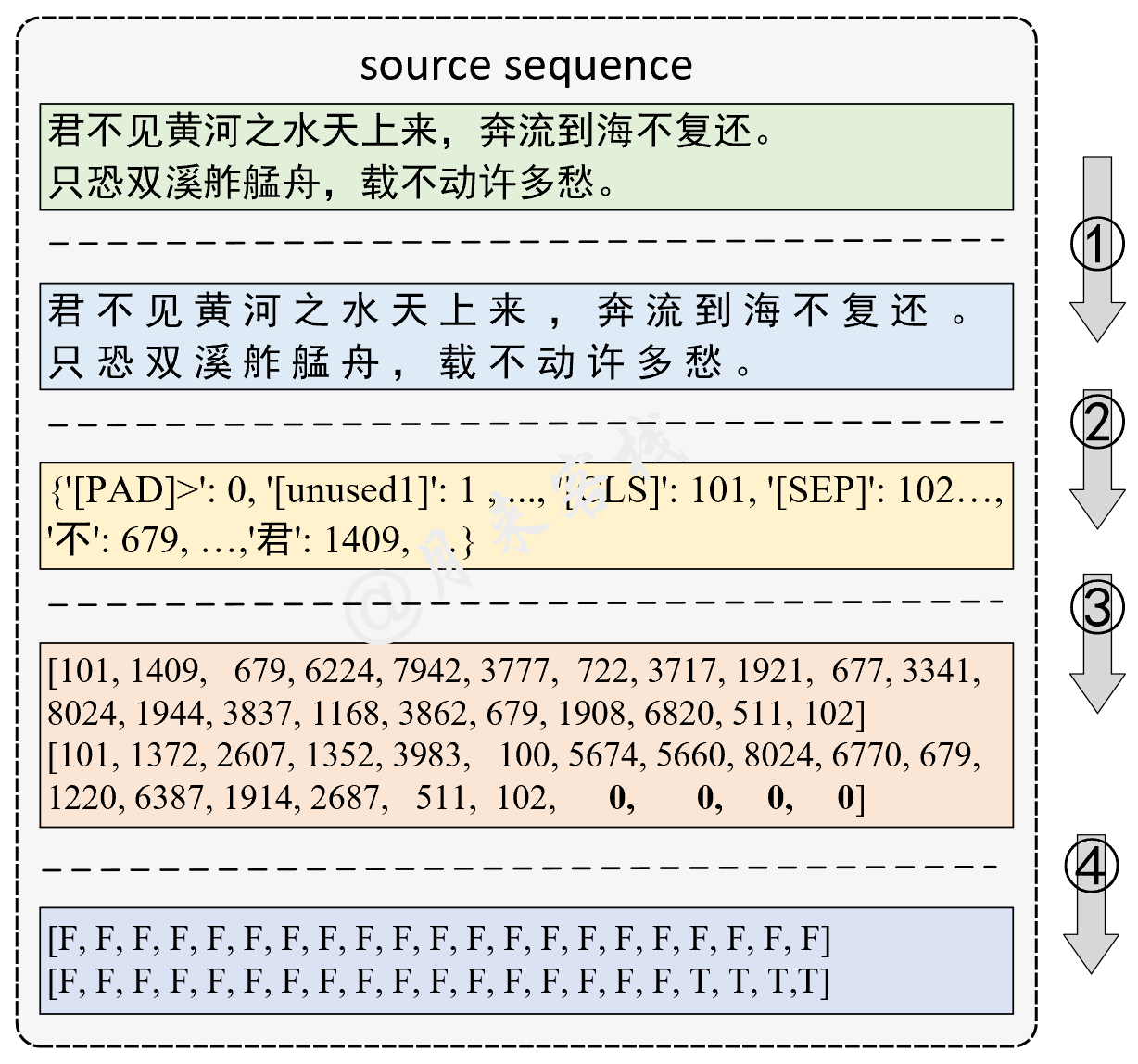
python TaskForSingleSentenceClassification . pyنتيجة:
- - INFO : Epoch : 0 , Batch [ 0 / 4186 ], Train loss : 2.862 , Train acc : 0.125
- - INFO : Epoch : 0 , Batch [ 10 / 4186 ], Train loss : 2.084 , Train acc : 0.562
- - INFO : Epoch : 0 , Batch [ 20 / 4186 ], Train loss : 1.136 , Train acc : 0.812
- - INFO : Epoch : 0 , Batch [ 30 / 4186 ], Train loss : 1.000 , Train acc : 0.734
...
- - INFO : Epoch : 0 , Batch [ 4180 / 4186 ], Train loss : 0.418 , Train acc : 0.875
- - INFO : Epoch : 0 , Train loss : 0.481 , Epoch time = 1123.244 s
...
- - INFO : Epoch : 9 , Batch [ 4180 / 4186 ], Train loss : 0.102 , Train acc : 0.984
- - INFO : Epoch : 9 , Train loss : 0.100 , Epoch time = 1130.071 s
- - INFO : Accurcay on val 0.884
- - INFO : Accurcay on val 0.888بنية النموذج ومعالجة البيانات:

python TaskForPairSentenceClassification . pyنتيجة:
- - INFO : Epoch : 0 , Batch [ 0 / 17181 ], Train loss : 1.082 , Train acc : 0.438
- - INFO : Epoch : 0 , Batch [ 10 / 17181 ], Train loss : 1.104 , Train acc : 0.438
- - INFO : Epoch : 0 , Batch [ 20 / 17181 ], Train loss : 1.129 , Train acc : 0.250
- - INFO : Epoch : 0 , Batch [ 30 / 17181 ], Train loss : 1.063 , Train acc : 0.375
...
- - INFO : Epoch : 0 , Batch [ 17180 / 17181 ], Train loss : 0.367 , Train acc : 0.909
- - INFO : Epoch : 0 , Train loss : 0.589 , Epoch time = 2610.604 s
...
- - INFO : Epoch : 9 , Batch [ 0 / 17181 ], Train loss : 0.064 , Train acc : 1.000
- - INFO : Epoch : 9 , Train loss : 0.142 , Epoch time = 2542.781 s
- - INFO : Accurcay on val 0.827
- - INFO : Accurcay on val 0.830بنية النموذج ومعالجة البيانات:
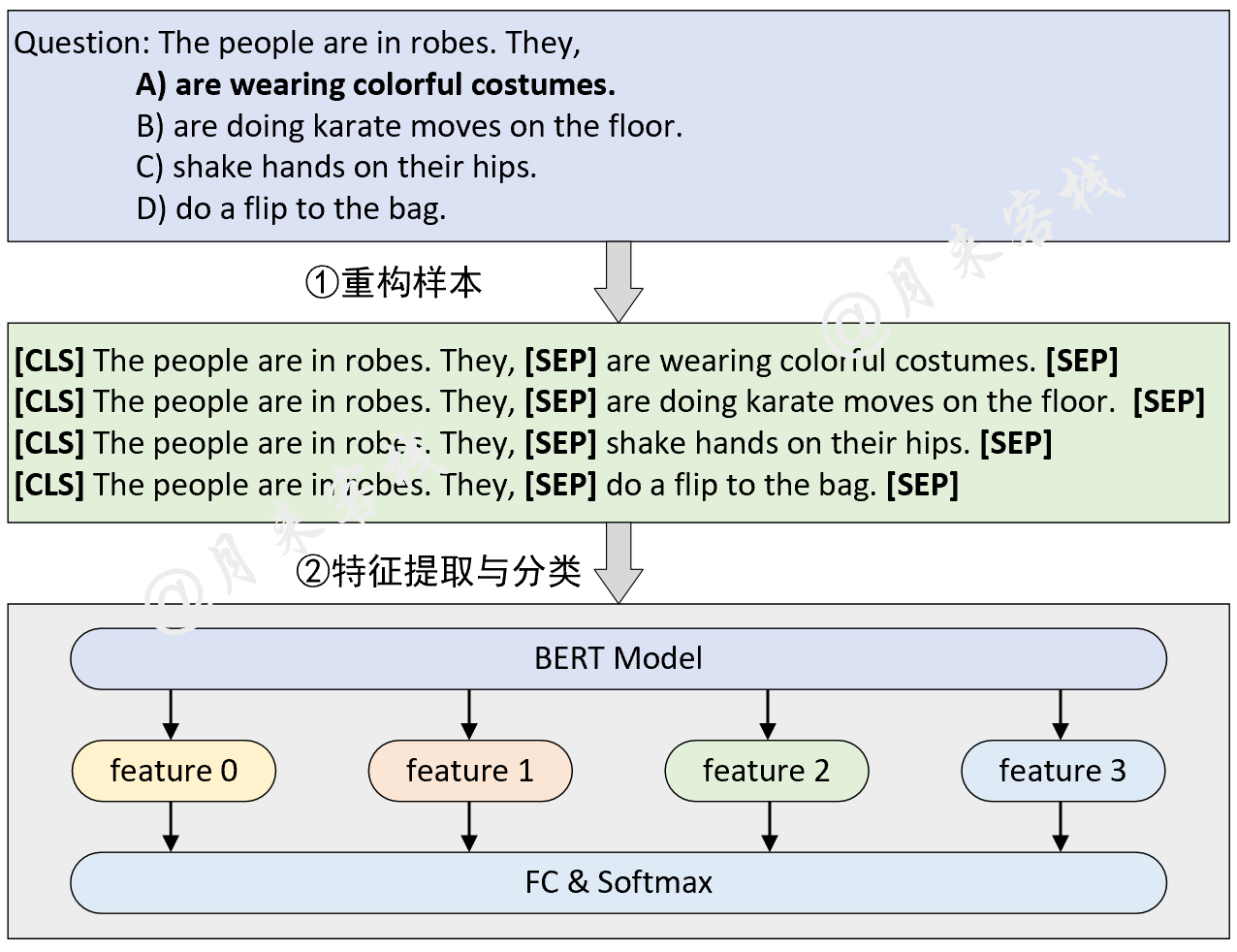
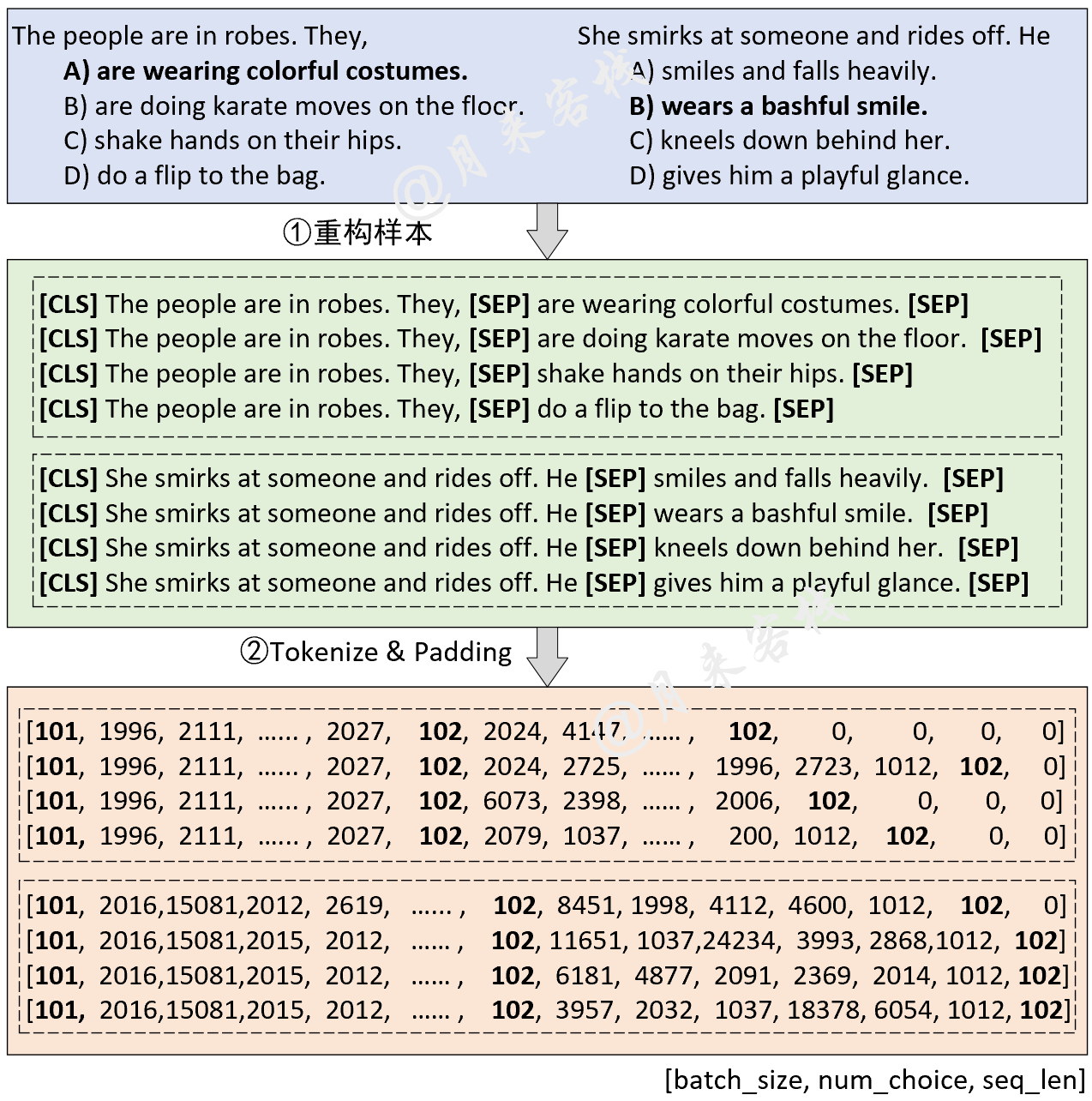
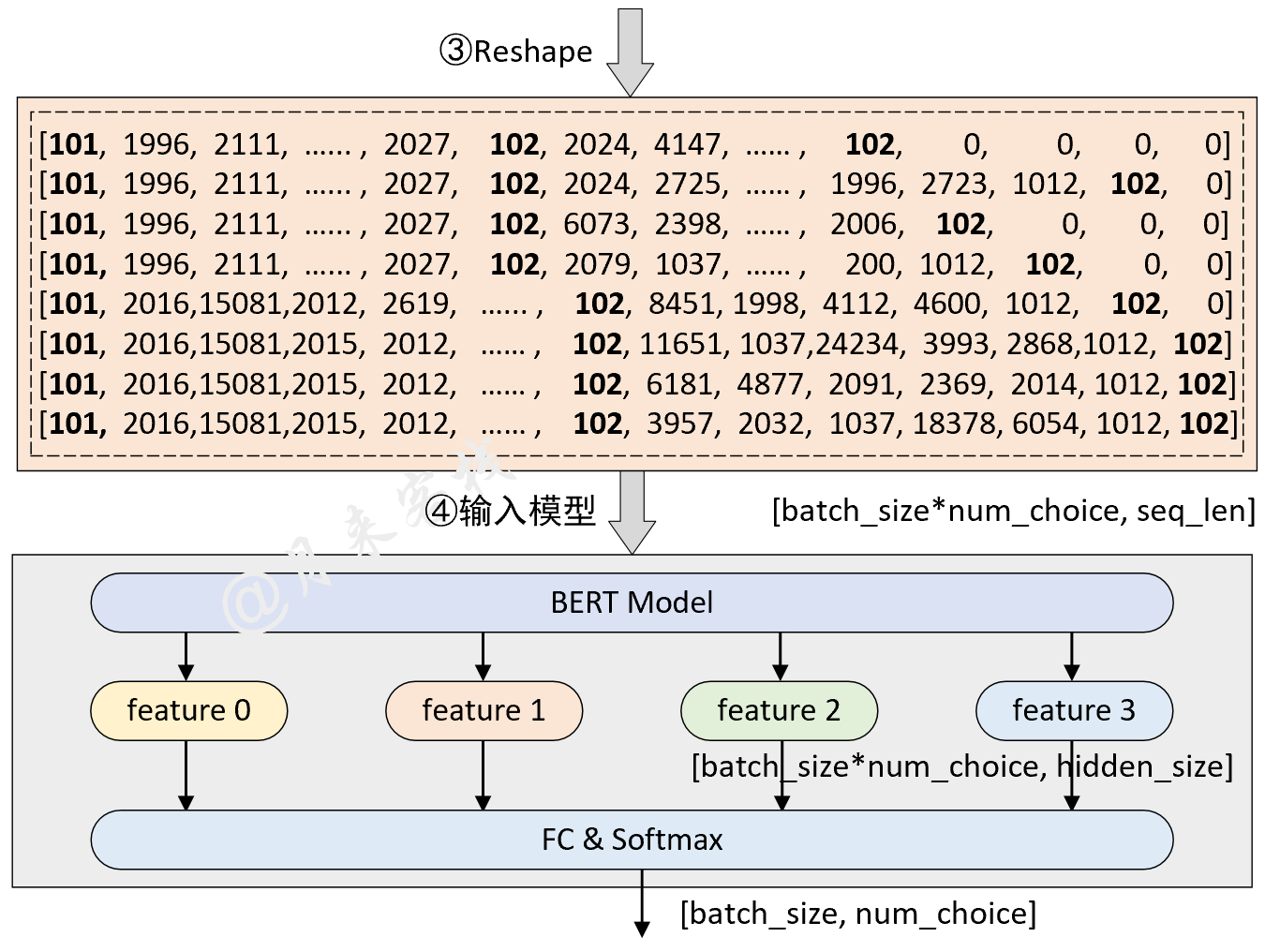
python TaskForMultipleChoice . pyنتيجة:
[ 2021 - 11 - 11 21 : 32 : 50 ] - INFO : Epoch : 0 , Batch [ 0 / 4597 ], Train loss : 1.433 , Train acc : 0.250
[ 2021 - 11 - 11 21 : 32 : 58 ] - INFO : Epoch : 0 , Batch [ 10 / 4597 ], Train loss : 1.277 , Train acc : 0.438
[ 2021 - 11 - 11 21 : 33 : 01 ] - INFO : Epoch : 0 , Batch [ 20 / 4597 ], Train loss : 1.249 , Train acc : 0.438
......
[ 2021 - 11 - 11 21 : 58 : 34 ] - INFO : Epoch : 0 , Batch [ 4590 / 4597 ], Train loss : 0.489 , Train acc : 0.875
[ 2021 - 11 - 11 21 : 58 : 36 ] - INFO : Epoch : 0 , Batch loss : 0.786 , Epoch time = 1546.173 s
[ 2021 - 11 - 11 21 : 28 : 55 ] - INFO : Epoch : 0 , Batch [ 0 / 4597 ], Train loss : 1.433 , Train acc : 0.250
[ 2021 - 11 - 11 21 : 30 : 52 ] - INFO : He is throwing darts at a wall . A woman , squats alongside flies side to side with his gun . ## False
[ 2021 - 11 - 11 21 : 30 : 52 ] - INFO : He is throwing darts at a wall . A woman , throws a dart at a dartboard . ## False
[ 2021 - 11 - 11 21 : 30 : 52 ] - INFO : He is throwing darts at a wall . A woman , collapses and falls to the floor . ## False
[ 2021 - 11 - 11 21 : 30 : 52 ] - INFO : He is throwing darts at a wall . A woman , is standing next to him . ## True
[ 2021 - 11 - 11 21 : 30 : 52 ] - INFO : Accuracy on val 0.794بنية النموذج ومعالجة البيانات:
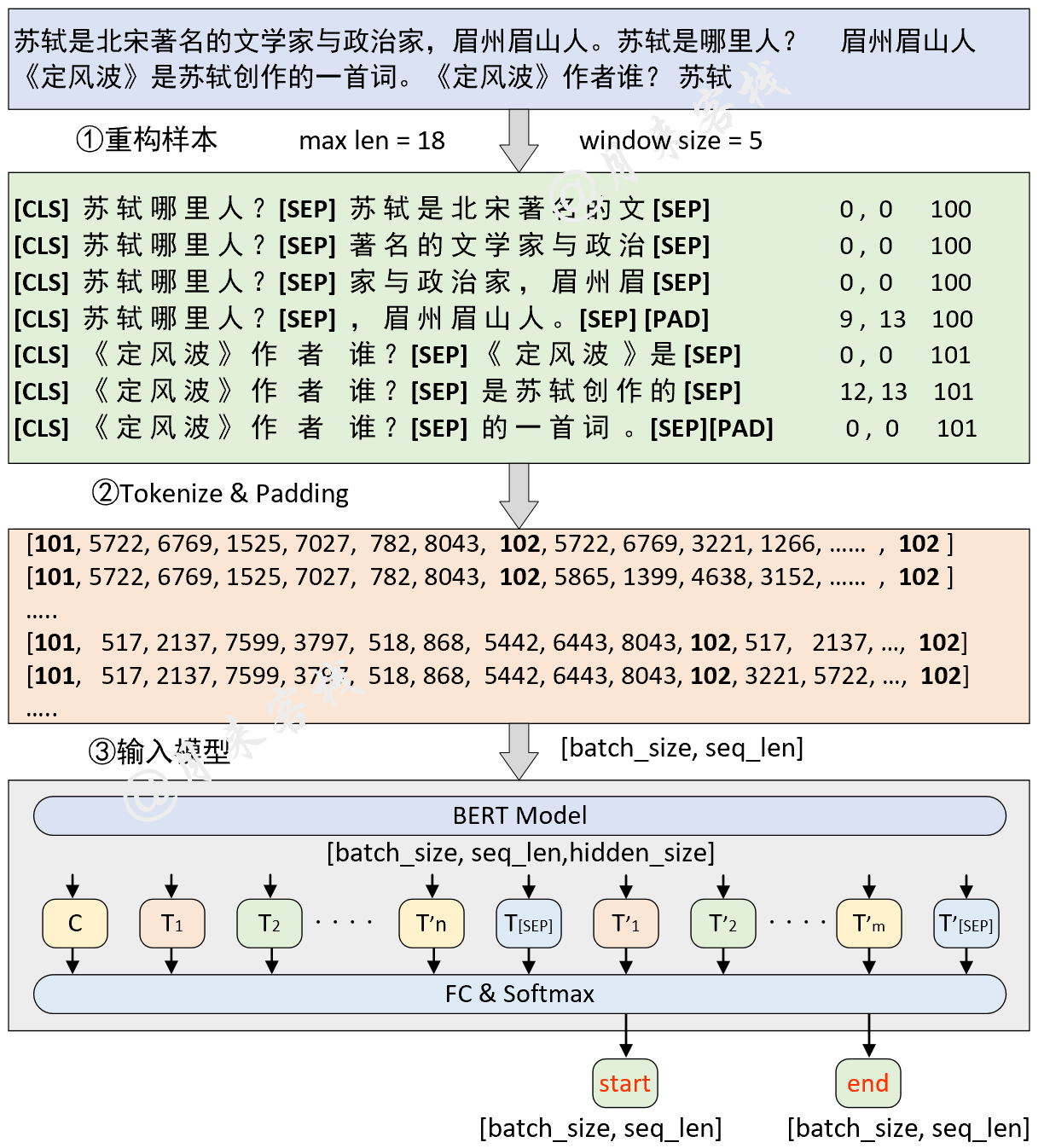
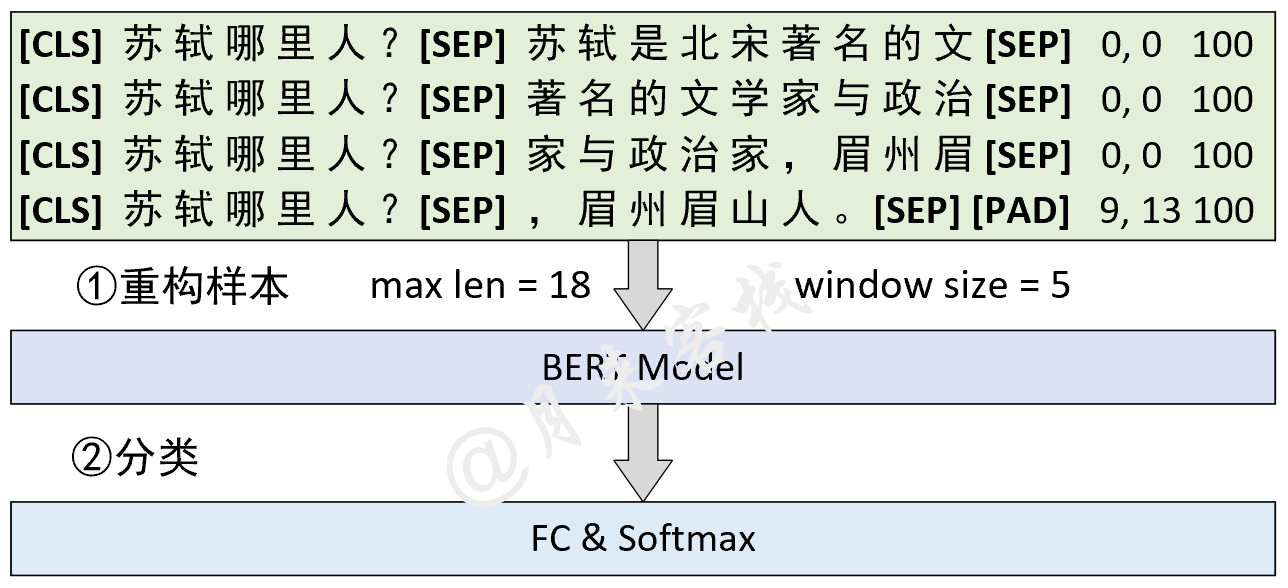
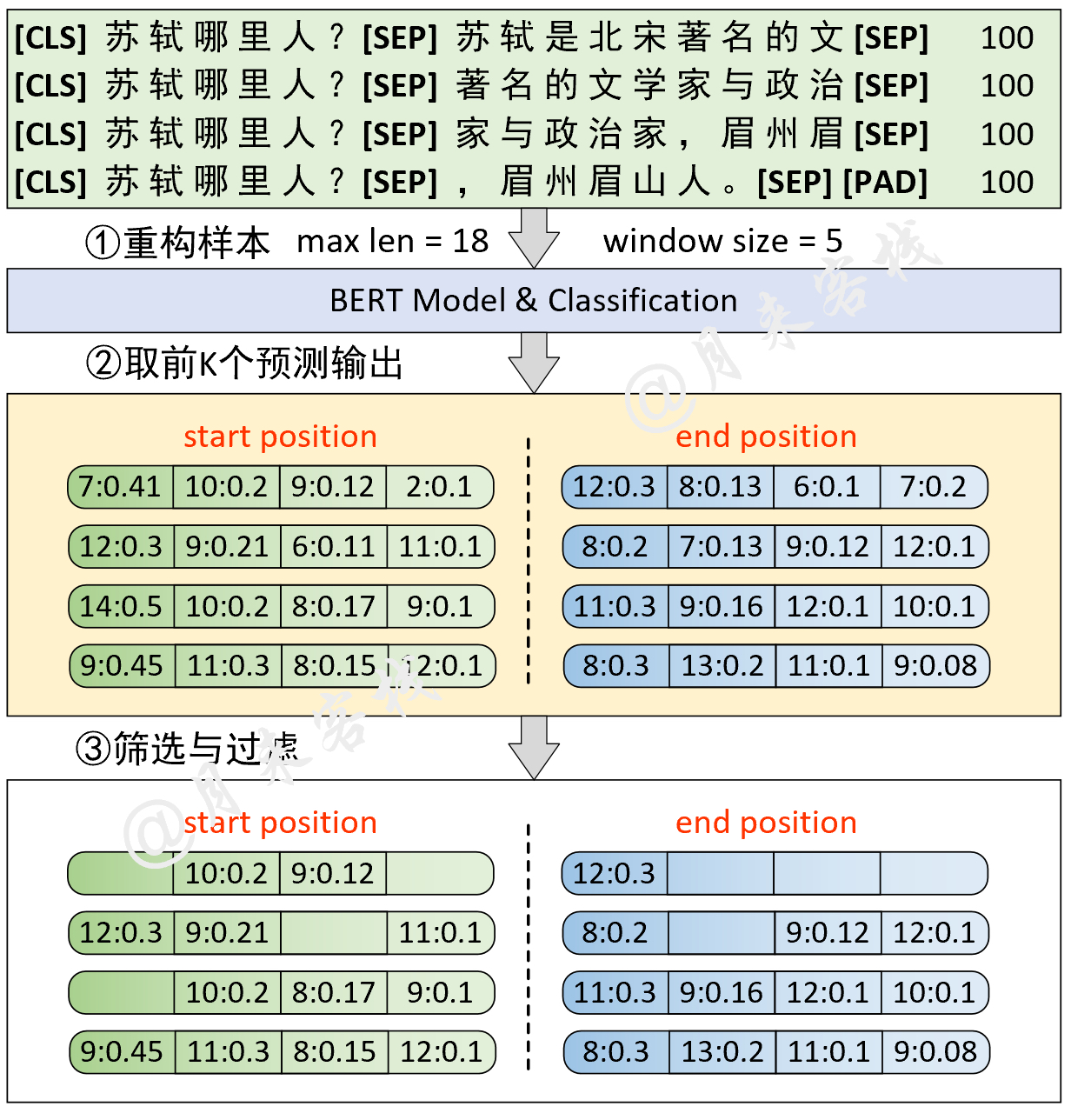
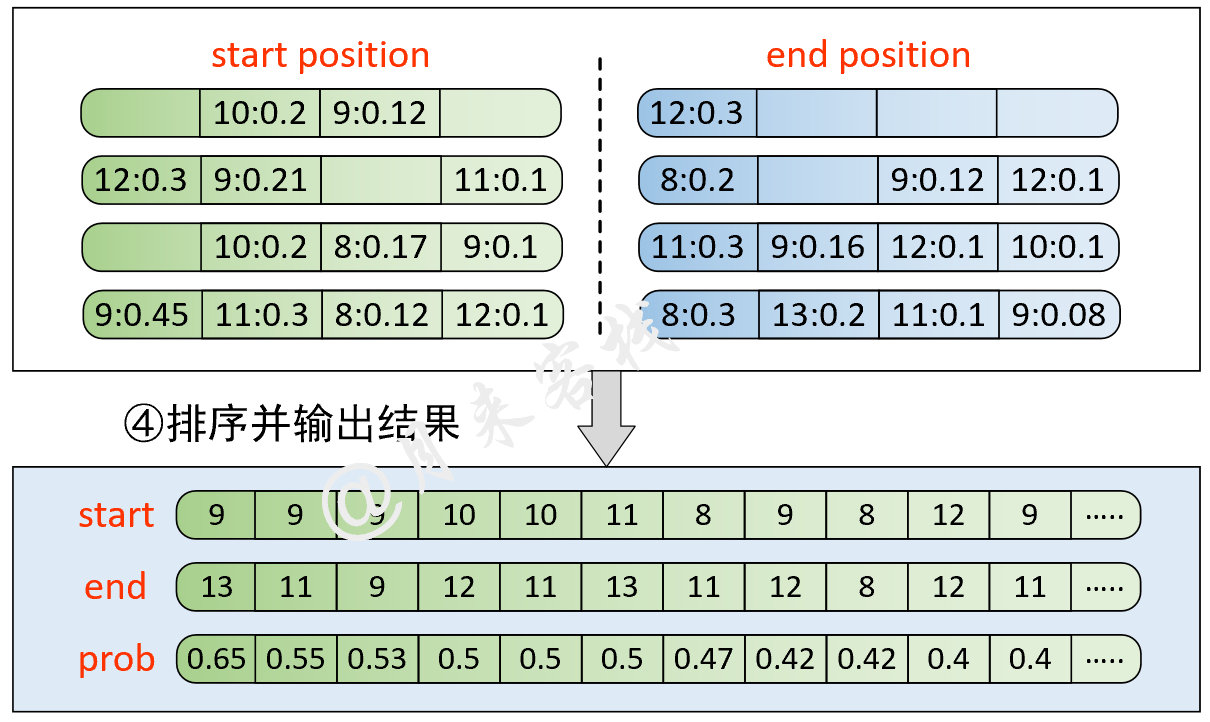
python TaskForSQuADQuestionAnswering . pyنتيجة:
[ 2022 - 01 - 02 14 : 42 : 17 ]缓存文件 ~ / BertWithPretrained / data / SQuAD / dev - v1_128_384_64 . pt 不存在,重新处理并缓存!
[ 2022 - 01 - 02 14 : 42 : 17 ] - DEBUG : << << << << 进入新的example >> > >> >> >>
[ 2022 - 01 - 02 14 : 42 : 17 ] - DEBUG : ## 正在预处理数据 utils.data_helpers is_training = False
[ 2022 - 01 - 02 14 : 42 : 17 ] - DEBUG : ## 问题 id: 56be5333acb8001400a5030d
[ 2022 - 01 - 02 14 : 42 : 17 ] - DEBUG : ## 原始问题 text: Which performers joined the headliner during the Super Bowl 50 halftime show?
[ 2022 - 01 - 02 14 : 42 : 17 ] - DEBUG : ## 原始描述 text: CBS broadcast Super Bowl 50 in the U.S., and charged an average of $5 million for a ....
[ 2022 - 01 - 02 14 : 42 : 17 ] - DEBUG : ## 上下文长度为:87, 剩余长度 rest_len 为 : 367
[ 2022 - 01 - 02 14 : 42 : 17 ] - DEBUG : ## input_tokens: ['[CLS]', 'which', 'performers', 'joined', 'the', 'headline', '##r', 'during', 'the', ...]
[ 2022 - 01 - 02 14 : 42 : 17 ] - DEBUG : ## input_ids:[101, 2029, 9567, 2587, 1996, 17653, 2099, 2076, 1996, 3565, 4605, 2753, 22589, 2265, 1029, 102, 6568, ....]
[ 2022 - 01 - 02 14 : 42 : 17 ] - DEBUG : ## segment ids:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...]
[ 2022 - 01 - 02 14 : 42 : 17 ] - DEBUG : ## orig_map:{16: 0, 17: 1, 18: 2, 19: 3, 20: 4, 21: 5, 22: 6, 23: 7, 24: 7, 25: 7, 26: 7, 27: 7, 28: 8, 29: 9, 30: 10,....}
[ 2022 - 01 - 02 14 : 42 : 17 ] - DEBUG : == == == == == == == == == == ==
....
[ 2022 - 01 - 02 15 : 13 : 50 ] - INFO : Epoch : 0 , Batch [ 810 / 7387 ] Train loss : 0.998 , Train acc : 0.708
[ 2022 - 01 - 02 15 : 13 : 55 ] - INFO : Epoch : 0 , Batch [ 820 / 7387 ] Train loss : 1.130 , Train acc : 0.708
[ 2022 - 01 - 02 15 : 13 : 59 ] - INFO : Epoch : 0 , Batch [ 830 / 7387 ] Train loss : 1.960 , Train acc : 0.375
[ 2022 - 01 - 02 15 : 14 : 04 ] - INFO : Epoch : 0 , Batch [ 840 / 7387 ] Train loss : 1.933 , Train acc : 0.542
......
[ 2022 - 01 - 02 15 : 15 : 27 ] - INFO : ### Quesiotn: [CLS] when was the first university in switzerland founded..
[ 2022 - 01 - 02 15 : 15 : 27 ] - INFO : ## Predicted answer: 1460
[ 2022 - 01 - 02 15 : 15 : 27 ] - INFO : ## True answer: 1460
[ 2022 - 01 - 02 15 : 15 : 27 ] - INFO : ## True answer idx: (tensor(46, tensor(47))
[ 2022 - 01 - 02 15 : 15 : 27 ] - INFO : ### Quesiotn: [CLS] how many wards in plymouth elect two councillors?
[ 2022 - 01 - 02 15 : 15 : 27 ] - INFO : ## Predicted answer: 17 of which elect three .....
[ 2022 - 01 - 02 15 : 15 : 27 ] - INFO : ## True answer: three
[ 2022 - 01 - 02 15 : 15 : 27 ] - INFO : ## True answer idx: (tensor(25, tensor(25))运行结束后 , data/SQuAD目录中会生成一个名为best_result.json的预测文件 , 此时只需要切换到该目录下 , 并运行以下代码即可得到在dev-v1.1.json的测试结果 :
python evaluate - v1 . 1. py dev - v1 . 1.j son best_result . json
"exact_match" : 80.879848628193 , "f1" : 88.338575234135بنية النموذج ومعالجة البيانات:
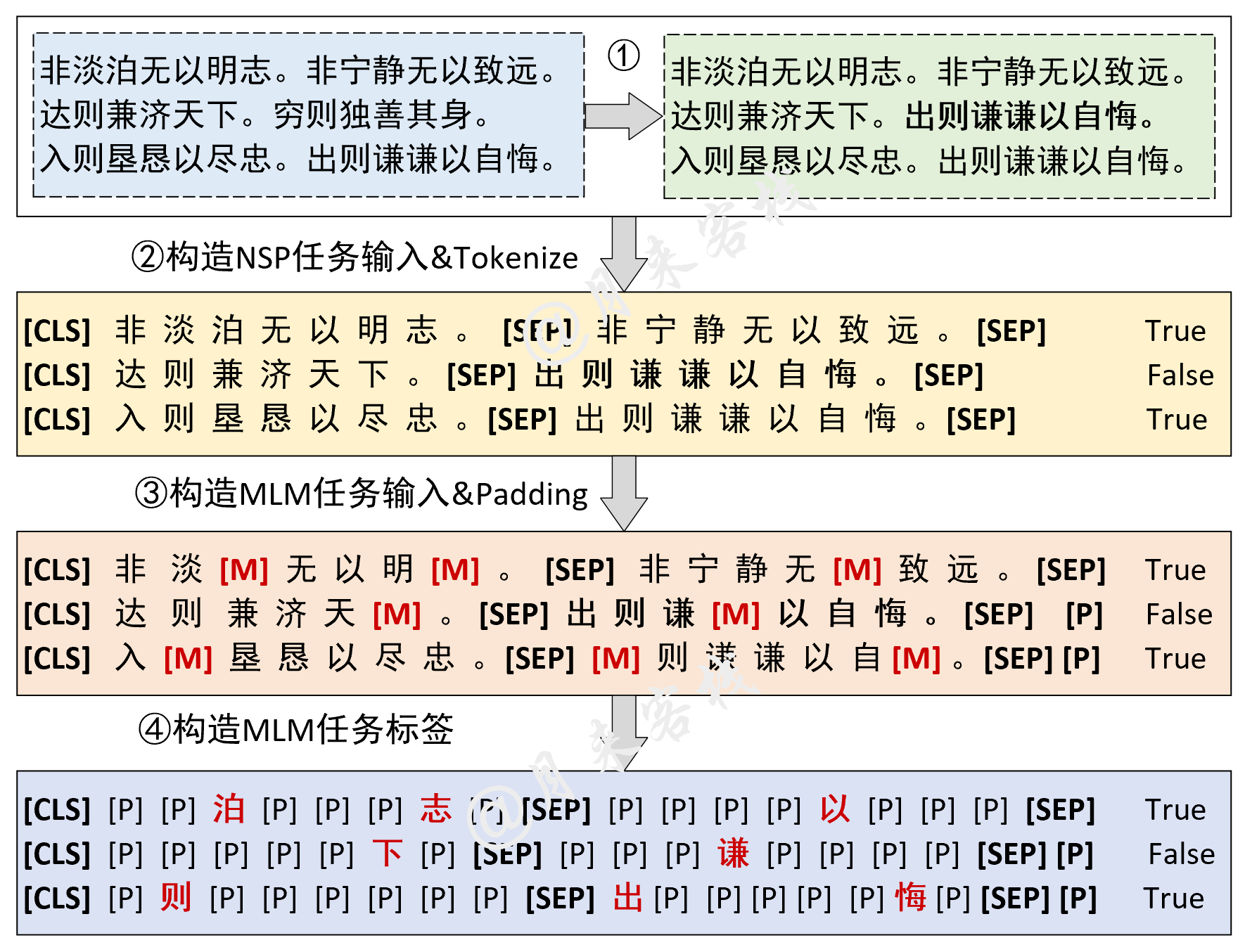
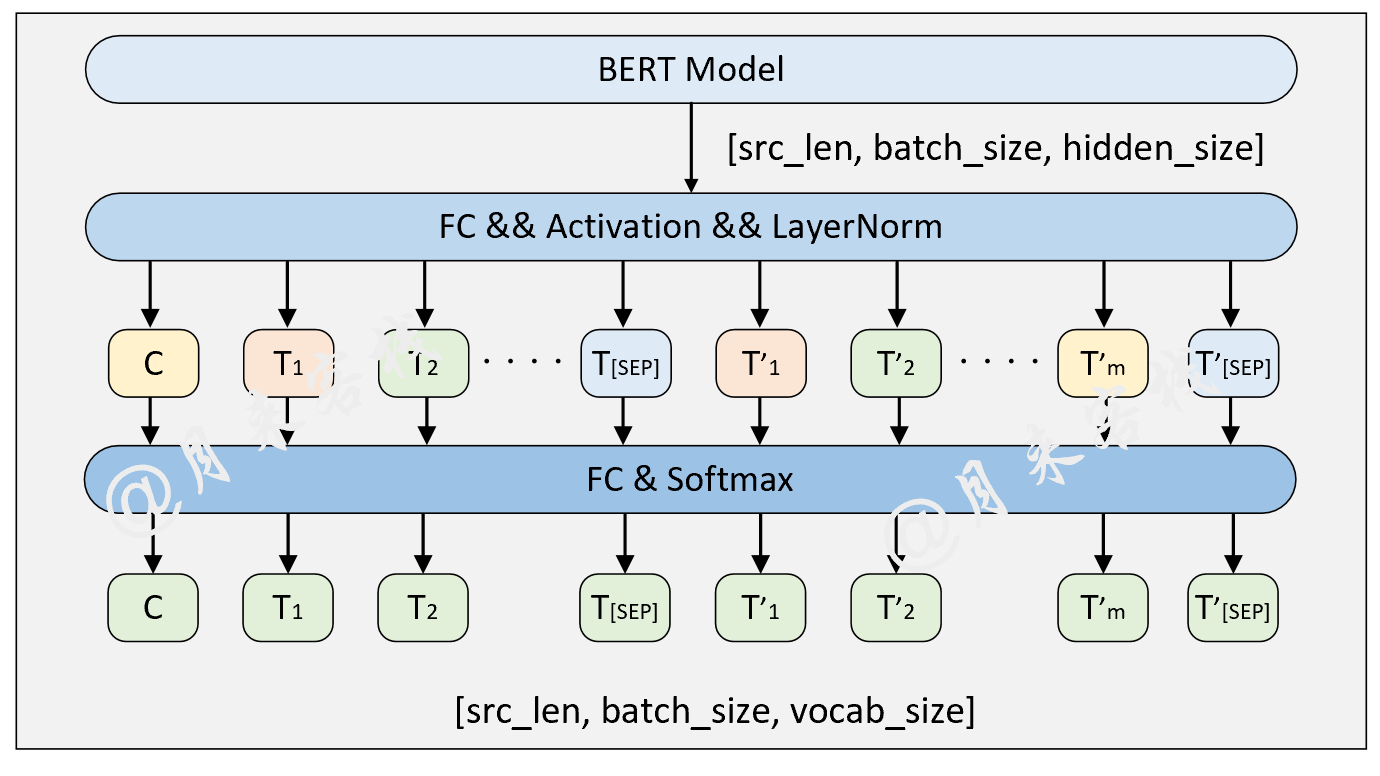
if __name__ == '__main__' :
config = ModelConfig ()
train ( config )
sentences_1 = [ "I no longer love her, true, but perhaps I love her." ,
"Love is so short and oblivion so long." ]
sentences_2 = [ "我住长江头,君住长江尾。" ,
"日日思君不见君,共饮长江水。" ,
"此水几时休,此恨何时已。" ,
"只愿君心似我心,定不负相思意。" ]
inference ( config , sentences_2 , masked = False , language = 'zh' )نتيجة:
- INFO : ## 成功载入已有模型进行推理……
- INFO : ### 原始:我住长江头,君住长江尾。
- INFO : ## 掩盖:我住长江头,[MASK]住长[MASK]尾。
- INFO : ## 预测:我住长江头,君住长河尾。
- INFO : == == == == == == == == == ==
- INFO : ### 原始:日日思君不见君,共饮长江水。
- INFO : ## 掩盖:日日思君不[MASK]君,共[MASK]长江水。
- INFO : ## 预测:日日思君不见君,共饮长江水。
# ......بنية النموذج ومعالجة البيانات:
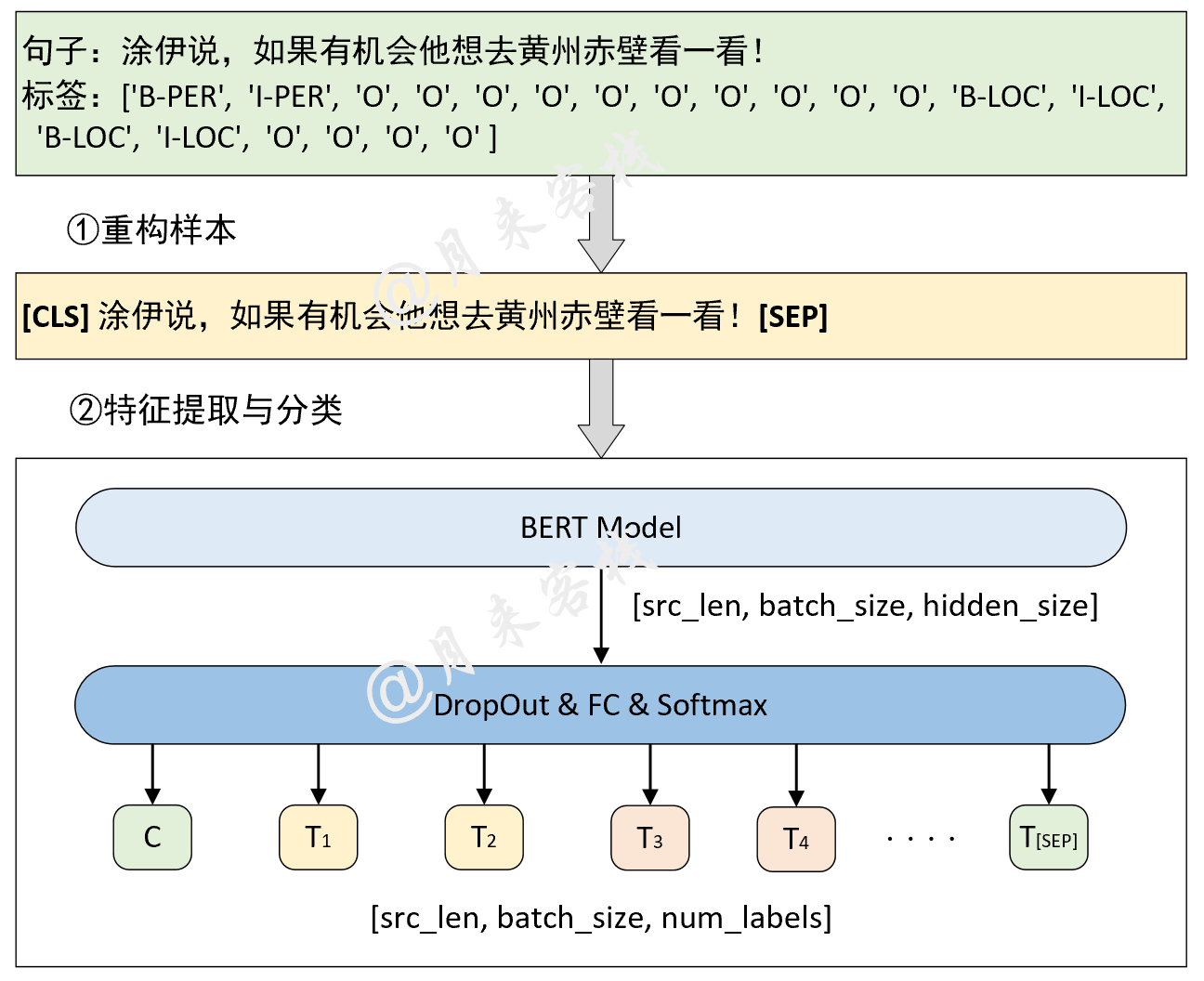
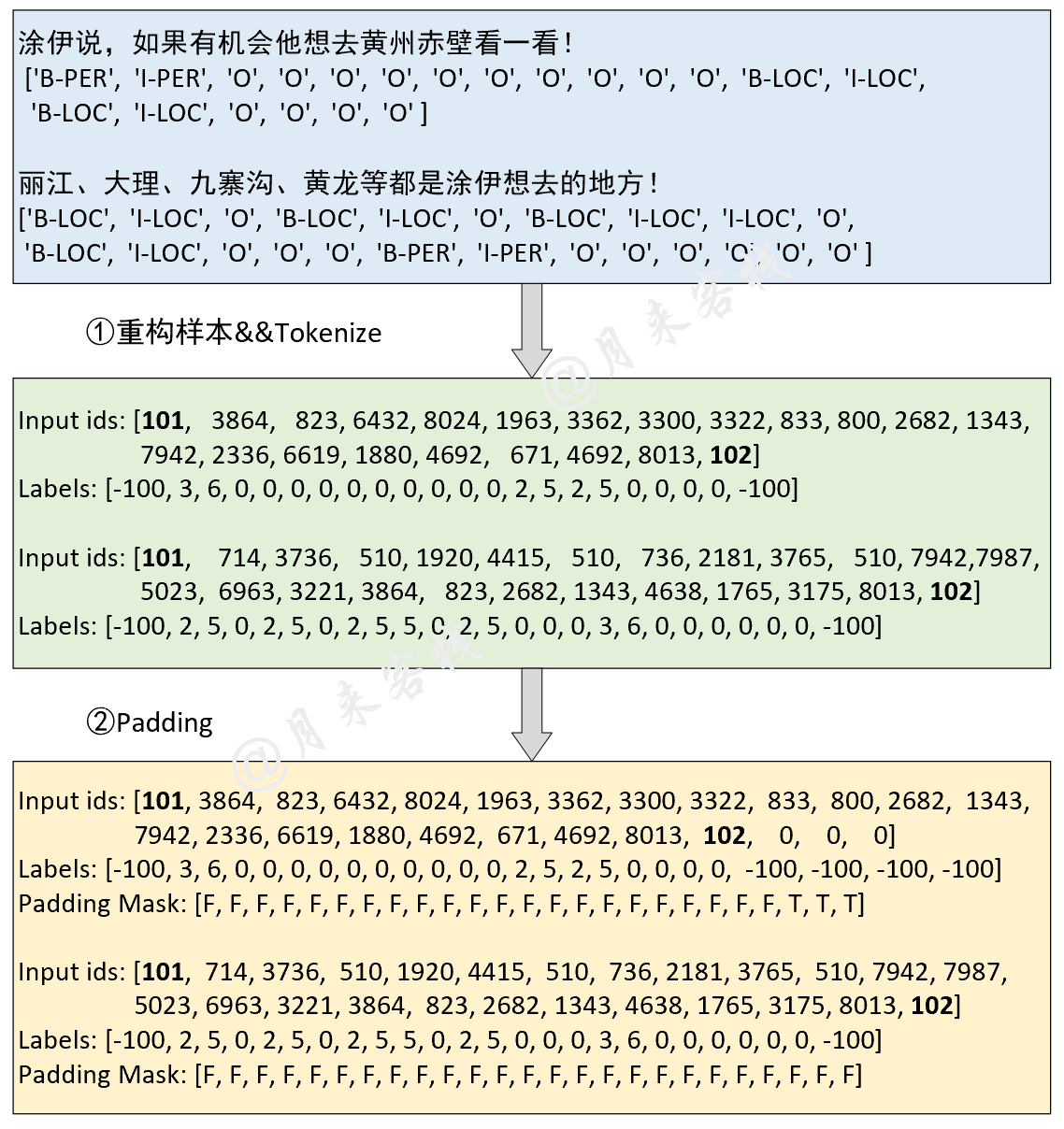
if __name__ == '__main__' :
config = ModelConfig ()
train ( config )
sentences = [ '智光拿出石壁拓文为乔峰详述事情始末,乔峰方知自己原本姓萧,乃契丹后族。' ,
'当乔峰问及带头大哥时,却发现智光大师已圆寂。' ,
'乔峰、阿朱相约找最后知情人康敏问完此事后,就到塞外骑马牧羊,再不回来。' ]
inference ( config , sentences )نتيجة التدريب:
- INFO : Epoch : [ 1 / 10 ], Batch [ 620 / 1739 ], Train Loss : 0.115 , Train acc : 0.96386
- INFO : Epoch : [ 1 / 10 ], Batch [ 240 / 1739 ], Train Loss : 0.098 , Train acc : 0.96466
- INFO : Epoch : [ 1 / 10 ], Batch [ 660 / 1739 ], Train Loss : 0.087 , Train acc : 0.96435
......
- INFO :句子:在澳大利亚等西方国家改变反倾销政策中对中国的划分后,不少欧盟人士也认识到,此种划分已背离中国经济迅速发展的现实。
- INFO : 澳大利亚: LOC
- INFO : 中国: LOC
- INFO : 欧盟: LOC
- INFO : 中国: LOC
......
precision recall f1 - score support
O 1.00 0.99 1.00 97640
B - ORG 0.86 0.93 0.89 984
B - LOC 0.94 0.93 0.94 1934
B - PER 0.97 0.97 0.97 884
I - ORG 0.90 0.96 0.93 3945
I - LOC 0.91 0.95 0.93 2556
I - PER 0.99 0.98 0.98 1714
accuracy 0.99 109657
macro avg 0.94 0.96 0.95 109657
weighted avg 0.99 0.99 0.99 109657نتيجة الاستدلال:
- INFO : 句子:智光拿出石壁拓文为乔峰详述事情始末,乔峰方知自己原本姓萧,乃契丹后族。
- INFO : 智光: PER
- INFO : 乔峰: PER
- INFO : 乔峰: PER
- INFO : 萧: PER
- INFO : 丹: PER
......

