full stack on prem cv mlops
1.0.0
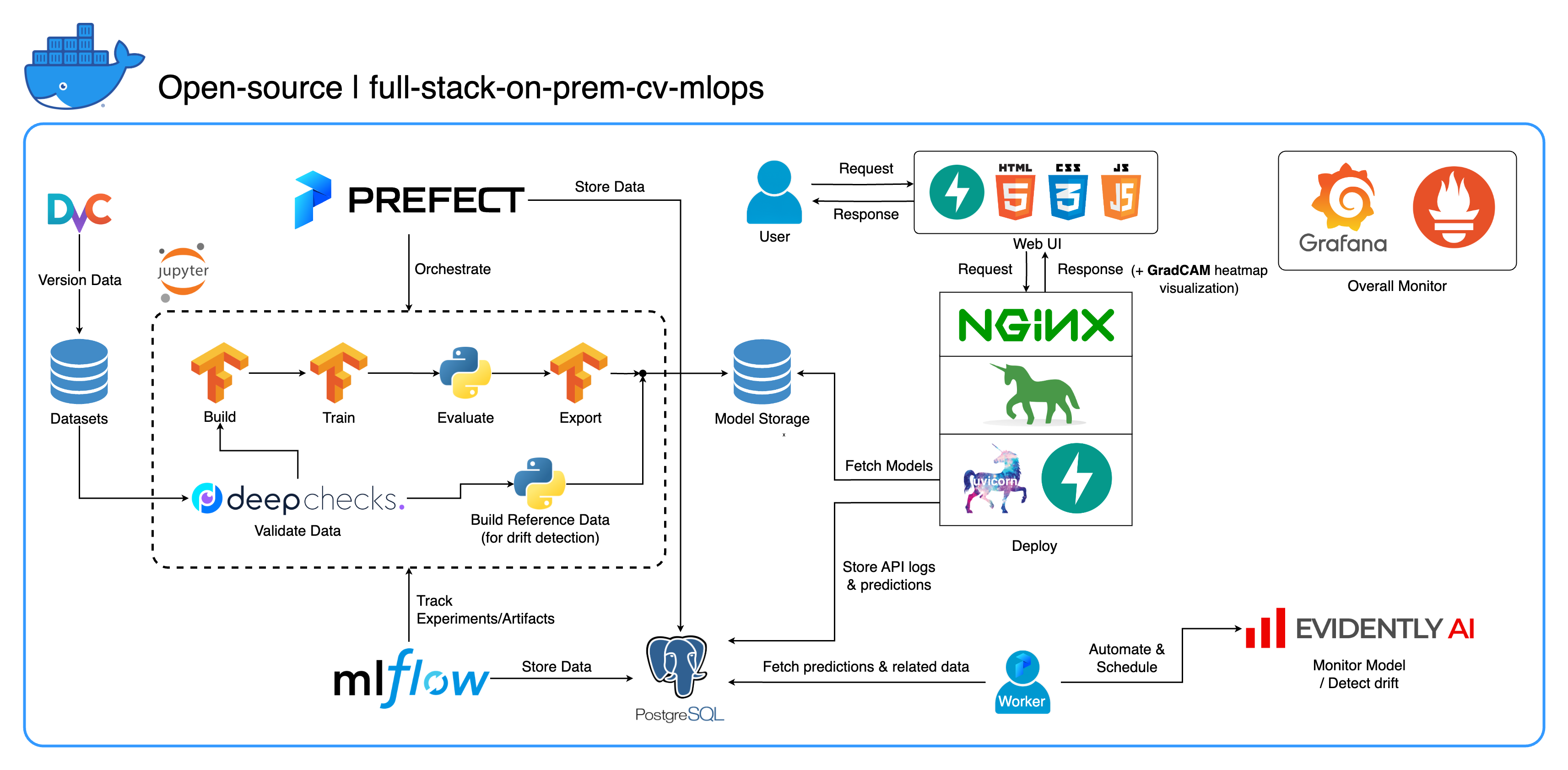
مرحبًا بك في نظام MLOps البيئي الشامل الخاص بنا والذي تم تصميمه خصيصًا لمهام رؤية الكمبيوتر، مع التركيز بشكل أساسي على تصنيف الصور. يزودك هذا المستودع بكل ما تحتاجه، بدءًا من مساحة عمل التطوير في Jupyter Lab/Notebook وحتى الخدمات على مستوى الإنتاج. أفضل جزء؟ لا يتطلب الأمر سوى "تكوين واحد وأمر واحد" لتشغيل النظام بأكمله بدءًا من إنشاء النموذج وحتى النشر! لقد قمنا بدمج العديد من أفضل الممارسات لضمان قابلية التوسع والموثوقية مع الحفاظ على المرونة. في حين أن حالة الاستخدام الأساسية لدينا تدور حول تصنيف الصور، فإن هيكل مشروعنا يمكن أن يتكيف بسهولة مع مجموعة واسعة من تطورات ML/DL، وحتى الانتقال من مكان العمل إلى السحابة!
الهدف الآخر هو إظهار كيفية دمج كل هذه الأدوات وجعلها تعمل معًا في نظام واحد كامل. إذا كنت مهتمًا بمكونات أو أدوات محددة، فلا تتردد في اختيار ما يناسب احتياجات مشروعك.
يتم وضع النظام بأكمله في حاوية في ملف Docker Compose واحد. لإعداده، كل ما عليك فعله هو تشغيل docker-compose up ! هذا نظام داخلي بالكامل، مما يعني عدم الحاجة إلى حساب سحابي، ولن يكلفك استخدام النظام بأكمله سنتًا واحدًا !
نوصي بشدة بمشاهدة مقاطع الفيديو التجريبية في قسم مقاطع الفيديو التجريبية للحصول على نظرة عامة شاملة وفهم كيفية تطبيق هذا النظام على مشاريعك. تحتوي مقاطع الفيديو هذه على تفاصيل مهمة قد تكون طويلة جدًا وغير واضحة بدرجة كافية لتغطيتها هنا.
العرض التوضيحي: https://youtu.be/NKil4uzmmQc
إرشادات تقنية متعمقة: https://youtu.be/l1S5tHuGBA8
الموارد في الفيديو:
لاستخدام هذا المستودع، ما عليك سوى Docker. كمرجع، نستخدم إصدار Docker 24.0.6 وبناء ed223bc وإصدار Docker Compose v2.21.0-desktop.1 على Mac M1.
لقد قمنا بتنفيذ العديد من أفضل الممارسات في هذا المشروع:
tf.data لـ TensorFlowimgaug lib للحصول على مرونة أكبر في خيارات التكبير مقارنة بالوظائف الأساسية من TensorFlowos.env للتكوينات المهمة أو على مستوى الخدمةlogging بدلاً من print.env للمتغيرات في docker-compose.ymldefault.conf.template لـ Nginx لتطبيق متغيرات البيئة بشكل أنيق في تكوين Nginx (ميزة جديدة في Nginx 1.19)يمكن تخصيص معظم المنافذ في ملف .env في جذر هذا المستودع. فيما يلي الإعدادات الافتراضية:
123456789 )[email protected] ، pw: SuperSecurePwdHere )admin , pw: admin ) عليك أن تفكر في التعليق على هذا platform: linux/arm64 في docker-compose.yml إذا كنت لا تستخدم جهاز كمبيوتر يستند إلى ARM (نحن نستخدم Mac M1 للتطوير). وإلا فإن هذا النظام لن يعمل.
--recurse-submodules في أمرك: git clone --recurse-submodules https://github.com/jomariya23156/full-stack-on-prem-cv-mlopsdeploy ضمن خدمة jupyter في docker-compose.yml وتغيير الصورة الأساسية في services/jupyter/Dockerfile من ubuntu:18.04 إلى nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 (النص موجود في الملف، ما عليك سوى التعليق عليه و uncomment) للاستفادة من وحدة (وحدات) GPU الخاصة بك. قد تحتاج أيضًا إلى تثبيت nvidia-container-toolkit على الجهاز المضيف حتى يعمل. بالنسبة لمستخدمي Windows/WSL2، وجدنا هذه المقالة مفيدة جدًا.docker-compose up أو docker-compose up -d لفصل الوحدة الطرفية.datasets/animals10-dvc واتبع الخطوات الموجودة في قسم كيفية الاستخدام . http://localhost:8888/labcd ~/workspace/docker-compose.yml ) conda activate computer-viz-dlpython run_flow.py --config configs/full_flow_config.yamltasksflowsrun_flow.py في جذر الريبو.start(config) في ملف التدفق الخاص بك. تقبل هذه الوظيفة التكوين باعتباره إملاءًا لـ Python ثم تستدعي بشكل أساسي التدفق المحدد في هذا الملف.datasets ويجب أن يكون لها جميعًا نفس بنية الدليل الموجودة داخل هذا الريبو.central_storage في ~/ariya/ على دليلين فرعيين على الأقل باسم models و ref_data . يخدم هذا central_storage غرض تخزين الكائنات المتمثل في تخزين جميع الملفات المرحلية لاستخدامها عبر بيئات التطوير والنشر. (هذا أحد الأشياء التي يمكنك التفكير في تغييرها إلى خدمة تخزين سحابية في حالة رغبتك في النشر على السحابة وجعلها أكثر قابلية للتطوير)اتفاقيات مهمة يجب توخي الحذر الشديد إذا كنت تريد التغيير (لأن هذه الأشياء مرتبطة وتستخدم في أجزاء مختلفة من النظام):
central_storage -> بالداخل يجب أن يكون هناك models/ ref_data/ أدلة فرعية<model_name>.yaml ، <model_name>_uae ، <model_name>_bbsd ، <model_name>_ref_data.parquetcurrent_model_metadata_file و monitor_pool_namecomputer-viz-dl (القيمة الافتراضية)، مع كافة الحزم المطلوبة لهذا المستودع. من المفترض أن يتم تشغيل جميع أوامر/أكواد Python داخل Jupyter هذا.central_storage بمثابة مخزن الملفات المركزي المستخدم خلال عملية التطوير والنشر. يحتوي بشكل أساسي على ملفات نموذجية (بما في ذلك أجهزة كشف الانجراف) وبيانات مرجعية بتنسيق Parquet. في نهاية خطوة تدريب النموذج، يتم حفظ النماذج الجديدة هنا، وتقوم خدمة النشر بسحب النماذج من هذا الموقع. ( ملاحظة : هذا هو المكان المثالي للاستبدال بخدمات التخزين السحابية من أجل قابلية التوسع.)model في التكوين لإنشاء نموذج مصنف. تم إنشاء النموذج باستخدام TensorFlow وتم ترميز بنيته ضمن tasks/model.py:build_model .dataset في التكوين لإعداد مجموعة بيانات للتدريب. يتم استخدام DvC في هذه الخطوة للتحقق من تناسق البيانات الموجودة في القرص مقارنة بالإصدار المحدد في التكوين. إذا كانت هناك تغييرات، فإنه يحولها مرة أخرى إلى الإصدار المحدد برمجياً. إذا كنت تريد الاحتفاظ بالتغييرات، في حالة قيامك بتجربة مجموعة البيانات، يمكنك تعيين حقل dvc_checkout في التكوين إلى false حتى لا يقوم DvC بأشياءه.train في التكوين لإنشاء أداة تحميل البيانات وبدء عملية التدريب. يتم تعقب معلومات التجربة والتحف وتسجيلها باستخدام MLflow . ملاحظة: يتم أيضًا تحميل تقرير النتائج (في ملف .html ) من DeepChecks إلى تجربة التدريب على MLflow الخاصة بالاتفاقية.model في ملف config.central_storage (في هذه الحالة، يتم فقط إنشاء نسخة إلى موقع central_storage . هذه هي الخطوة التي يمكنك تغييرها لتحميل الملفات إلى التخزين السحابي)model/drift_detection في ملف التكوين.central_storage .central_storage .central_storage . (هذه إحدى المخاوف التي تمت مناقشتها في الفيديو التوضيحي التعليمي، شاهده لمزيد من التفاصيل)current_model_metadata_file الذي يخزن اسم ملف بيانات تعريف النموذج المنتهي بـ .yaml و monitor_pool_name يخزن اسم مجمع العمل لنشر العامل المحافظ والتدفقات.cd برمجيًا في deployments/prefect-deployments وتشغيل prefect --no-prompt deploy --name {deploy_name} باستخدام المدخلات من قسم deploy/prefect في التكوين. نظرًا لأن كل شيء قد تم إرساءه ووضعه في حاوية بالفعل في هذا الريبو، فإن تحويل الخدمة من الخدمة المحلية إلى السحابة يعد أمرًا بسيطًا للغاية. عند الانتهاء من تطوير واختبار واجهة برمجة تطبيقات الخدمة الخاصة بك، يمكنك فقط فصل الخدمات/dl_service عن طريق إنشاء الحاوية من ملف Dockerfile الخاص بها، ودفعها إلى خدمة تسجيل حاوية سحابية (AWS ECR، على سبيل المثال). هذا كل شيء!
ملحوظة: هناك مشكلة واحدة محتملة في كود الخدمة إذا كنت تريد استخدامه في بيئة إنتاج حقيقية. لقد تناولت هذا الأمر في الفيديو المتعمق وأوصيك بقضاء بعض الوقت في مشاهدة الفيديو بأكمله. 
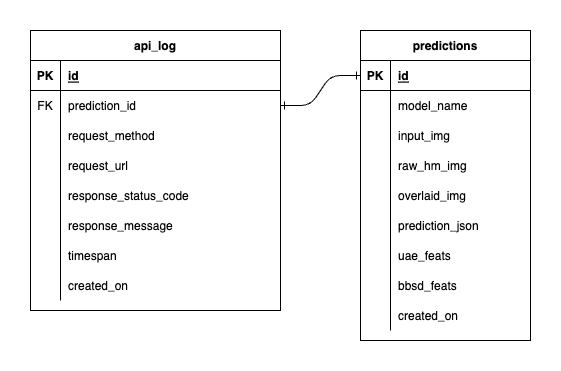
لدينا ثلاث قواعد بيانات داخل PostgreSQL: واحدة لـ MLflow، وواحدة للـ Prefect، وواحدة أنشأناها لخدمة نموذج ML الخاص بنا. لن نتعمق في الأولين، حيث تتم إدارتهما ذاتيًا بواسطة تلك الأدوات. قاعدة البيانات الخاصة بخدمة نموذج ML لدينا هي تلك التي صممناها بأنفسنا.
لتجنب التعقيد الشديد، أبقينا الأمر بسيطًا من خلال جدولين فقط. يتم عرض العلاقات والسمات في ERD أدناه. في الأساس، نهدف إلى تخزين التفاصيل الأساسية حول الطلبات الواردة واستجابات خدمتنا. يتم إنشاء جميع هذه الجداول ومعالجتها تلقائيًا، لذلك لا داعي للقلق بشأن الإعداد اليدوي.
جدير بالملاحظة: input_img و raw_hm_img و overlaid_img عبارة عن صور مشفرة بـ base64 ومخزنة كسلاسل. uae_feats و bbsd_feats عبارة عن مصفوفات من ميزات التضمين لخوارزميات اكتشاف الانجراف لدينا.
ImportError: /lib/aarch64-linux-gnu/libGLdispatch.so.0: cannot allocate memory in static TLS block ، فحاول export LD_PRELOAD=/lib/aarch64-linux-gnu/libGLdispatch.so.0 ثم أعد تشغيل البرنامج النصي.

