llamav2_local
1.0.0
該項目的創建是為了教授類似於CHATPDF的工具的構建(這是一個與pdfs對話的ChatGpt),使用aS LLM(大語言模型)開源的Llama V2(META)模型,本地運行。
基於該項目的第一個版本,我於2010年8月10日在YouTube上的Rocketseat頻道上進行了直播,在那裡我解釋了該應用程序的主要概念,代碼並騎了一些示例。如果您想檢查此Live的錄製,請轉到此鏈接。
為了促進對本解決方案的“構建塊”的理解,遵循下面的圖表,顯示了項目的動作和組成部分。
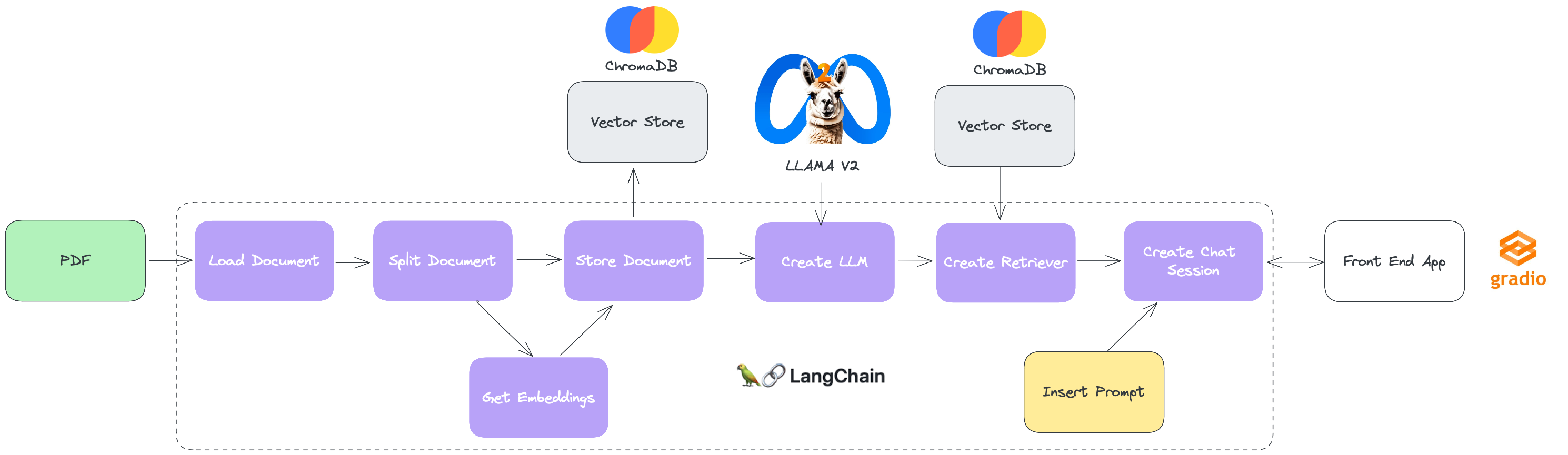
Langchain:這是一個開源框架,可提供簡單且靈活的API,可與LLMS一起使用。它允許開發人員創建使用LLMS進行各種任務的應用程序,包括翻譯,文本生成,問題(Q&A),代理等。它的連接器生態系統包括與最多樣化的LLM,矢量數據庫,聊天引擎的集成,這使其成為構建LLM的功能強大且通用的選項。
Chromadb:它是用於存儲嵌入的數據庫向量,它是代表單詞或短語含義的向量。它允許開發人員有效地存儲和研究嵌入,這對於使用LLMS的應用至關重要。 Chromadb使用近列鄰居搜索算法找到類似於特定嵌入的嵌入。這使開發人員可以快速,準確地研究大量嵌入數據。
Gradio:這是一個Python庫,它允許您快速創建用於機器學習模型的原型製作和測試的圖形接口。通過記錄,只需幾行代碼將Python函數轉換為交互式接口。它對於演示或測試機器學習模型而無需構建完整的應用程序特別有用。
Llama V2:它是預先培訓和微調的LLM的集合,範圍從70億到700億參數。精細調整的LLM,稱為Llama 2-Chat,針對對話用例(例如聊天和對話界面)進行了優化。在大多數測試的基准上,Llama V2模型都超過了開源聊天模型,並且根據我們的人類公用事業和安全評估,可以是封閉代碼模型的合適替代品。
pip install -r requirements.txtpipenv install在配置文件夾中,有一個稱為.env的文件,我們將配置一些信息以執行我們的項目。
為了使其更容易,我留下了一個.env文件,其中填充了默認配置,該文件考慮了該項目的文件夾中的所有文件夾。
只需打開IDE中的Jupyter筆記本電腦rag_pdf_live.ipynb,最好是按順序運行單元格即可。
在此筆記本的最後一個單元格中,其中IU實例與聊天會話進行交互,“在本地URL上運行:http://127.0.0.0.0.1:1:xxxx”,出現在xxxx是用於攀登網絡應用程序的等級的門中。為了使與聊天互動更容易,只需單擊地址,您的默認瀏覽器將使用聊天窗口打開。


