AMRICA
1.0.0
AMRICA(跨語言對齊的 AMR 檢查器)是一個簡單的工具,用於對齊和直觀地表示 AMR(Banarescu,2013),既適用於雙語環境,也適用於單語註釋者間協議。它基於並擴展了用於識別 AMR 互註釋器協議的 Smatch 系統(Cai,2012)。
也可以使用 AMRICA 來視覺化您自己編輯或編譯的手動對齊(請參閱通用標誌)。
從 github 下載 python 原始碼。
我們假設您有pip 。要安裝依賴項(假設您已經有下面提到的 graphviz 依賴項),只需執行:
pip install argparse_config networkx==1.8 pygraphviz pynlpl
pygraphviz需要 graphviz 才能運作。在 Linux 上,您可能必須安裝graphviz libgraphviz-dev pkg-config 。此外,要準備雙語對齊數據,您將需要 GIZA++,可能還需要 JAMR。
./disagree.py -i sample.amr -o sample_out_dir/
此命令將讀取sample.amr中的AMR(由空白行分隔)並將其graphviz視覺化放入位於sample_out_dir/ .png檔案中。
為了產生 Smatch 比對的可視化,我們需要一個 AMR 輸入文件,其中每個::tok或::snt字段包含標記化句子, ::id字段具有句子 ID,以及::annotator或::anno字段具有註釋器ID。特定句子的註釋按順序列出,第一個註釋被認為是可視化目的的黃金標準。
如果您只想視覺化每個句子的單一註釋而無需註釋器間達成一致,則可以使用僅具有單一註釋器的 AMR 檔案。在這種情況下,註釋者和句子 ID 欄位是可選的。產生的圖形將是全黑的。
對於雙語對齊,我們從兩個 AMR 檔案開始,一個包含目標註釋,另一個包含相同順序的來源註釋,每個註釋都有::tok和::id欄位。如果我們想要任一側的 JAMR 對齊,我們將其包含在::alignments欄位中。
句子對齊應採用兩個 GIZA++ 對齊 .NBEST 文件的形式,一個源-目標文件,一個目標-源文件。要產生這些,請使用 GIZA++ 設定檔中的 --nbestalignments 標誌設定為您首選的 nbest 計數。
可以在命令列或設定檔中設定標誌。設定檔的位置可以在命令列中使用-c CONF_FILE設定。
除了--conf_file之外,還有其他幾個標誌適用於單語和雙語文字。 --outdir DIR是唯一必要的,它指定我們將寫入映像檔的目錄。
可選的共享標誌是:
--verbose在對齊句子時印製它們。--no-verbose覆蓋詳細的預設設定。--json FILE.json將對齊圖寫入 .json 檔案。--num_restarts N指定 Smatch 應執行的隨機重新啟動次數。--align_out FILE.csv將對齊寫入檔案。--align_in FILE.csv從磁碟讀取比對而不是執行 Smatch。--layout將版面參數修改為graphviz。對齊 .csv 檔案採用以下格式:每個圖形匹配集均由空白行分隔,並且集合內的每一行包含註解或指示對齊的行。例如:
3 它 - 1 it
2 多长 - -1
-1 - 2 take
製表符分隔的欄位是測試節點索引(由 Smatch 處理)、測試節點標籤、黃金節點索引和黃金節點標籤。
單語言對齊需要一個附加標誌--infile FILE.amr ,其中FILE.amr設定為 AMR 檔案的位置。
以下是一個範例設定檔:
[default]
infile: data/events_amr.txt
outdir: data/events_png/
json: data/events.json
verbose
在雙語對齊中,需要更多的標誌。
--src_amr FILE 。--tgt_amr FILE 。--align_tgt2src FILE.A3.NBEST用於將目標到來源對齊的 GIZA++ .NBEST 檔案(目標為 vcb1),使用--nbestalignments N生成--align_src2tgt FILE.A3.NBEST用於將來源到目標對齊的 GIZA++ .NBEST 檔案(來源為 vcb1),使用--nbestalignments N生成現在,如果--nbestalignments N設定為 >1,我們應該使用--num_aligned_in_file指定它。如果我們只想計算頂部--num_align_read 。
--nbestalignments是一個使用起來很棘手的標誌,因為它只會在最終的對齊運行中產生。我只能自己讓它使用預設的 GIZA++ 設定。
由於 AMRICA 是 Smatch 的變體,因此應該先了解 Smatch。 Smatch 嘗試辨識同一句子的兩個 AMR 表示的變數節點之間的匹配,以衡量註釋者間的一致性。應選擇匹配以最大化 Smatch 分數,該分數為兩個圖中出現的每條邊分配一個點,分為三類。每個類別都在下面的“沒多久”註釋中進行了說明。
(t / take-10
:ARG0 (i / it)
:ARG1 (l2 / long
:polarity -))
(instance, t, take-10)(ARG0, t, i)(polarity, l2, -)由於尋找使 Smatch 得分最大化的匹配問題是 NP 完全問題,因此 Smatch 使用爬山演算法來逼近最佳解。它透過將每個節點與共享其標籤的節點(如果可能)進行配對並隨機匹配較小圖中的剩餘節點(以下稱為目標)來進行播種。然後,Smatch 執行一個步驟,透過切換兩個目標節點的匹配或將匹配從其來源節點移動到不匹配的來源節點來尋找最能增加分數的操作。它重複此步驟,直到沒有任何步驟可以立即增加 Smatch 分數。
為了避免局部最優,Smatch一般會重啟5次。
有關 AMRICA 內部運作的技術細節,閱讀我們的 NAACL 演示論文可能更有用。
AMRICA 首先將所有常數節點替換為變數節點,這些變數節點是常數標籤的實例。這是必要的,以便我們可以對齊常數節點和變數。因此,添加到 AMRICA 分數中的唯一點將來自匹配變數-變數邊緣和實例標籤。
雖然 Smatch 嘗試將較小圖中的每個節點與較大圖中的某個節點進行匹配,但 AMRICA 會刪除不會增加修改後的 Smatch 分數或 AMRICA 分數的匹配。
然後 AMRICA 從比對的 graphviz 圖中產生圖像檔。如果節點或邊僅出現在黃金資料中,則它是紅色的。如果該節點或邊僅出現在測試資料中,則它是藍色的。如果節點或邊在我們的最終對齊中匹配,則它是黑色的。
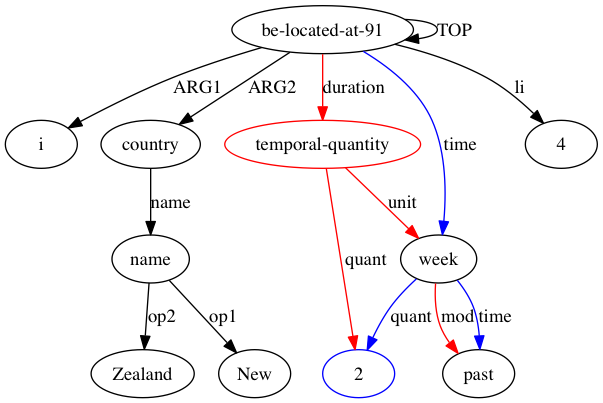
在 AMRICA 中,我們不是為每個完美匹配的實例標籤添加一個點,而是根據這些標籤對齊的似然分數添加一個點。似然得分 ℓ(aLt,Ls[i]|Lt,Wt,Ls,Ws) 與目標標籤集 Lt、來源標籤集 Ls、目標句 Wt、來源句 Ws 和對齊 aLt,Ls[i] 映射 Lt[ i ] 到某個標籤Ls[aLt,Ls[i]] 上,是根據以下規則定義的可能性計算的:
一般來說,雙語 AMRICA 似乎比單語 AMRICA 需要更多的隨機重啟才能表現良好。可以使用標誌--num_restarts修改此重新啟動計數。
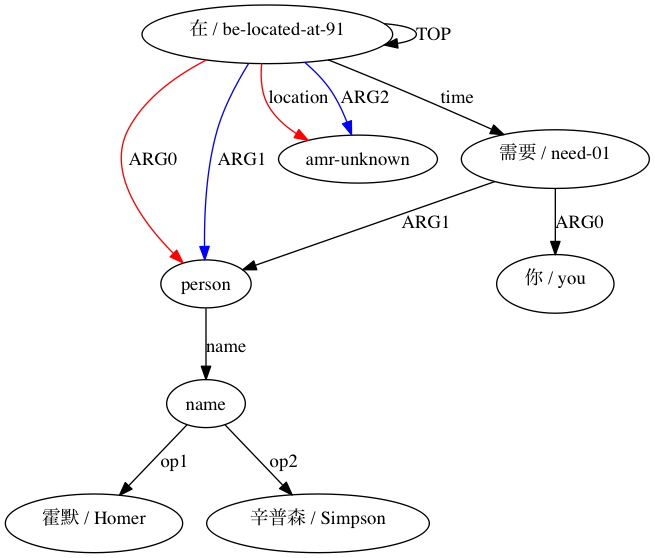
我們可以觀察到使用類似 Smatch 的近似(此處使用 20 個隨機初始化)比從原始對齊資料中選擇可能的匹配(智慧初始化)提高了準確性。對於(Xue 2014)聲明結構相容的配對。
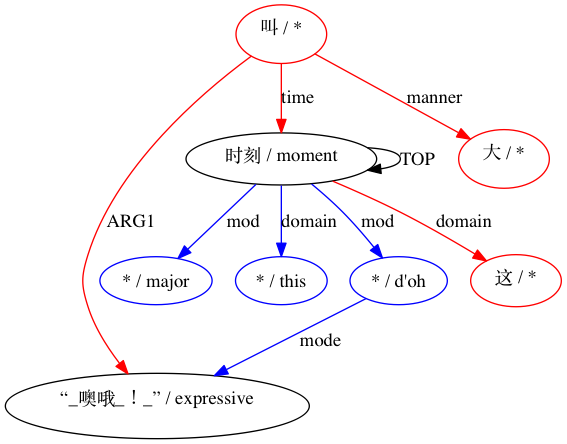
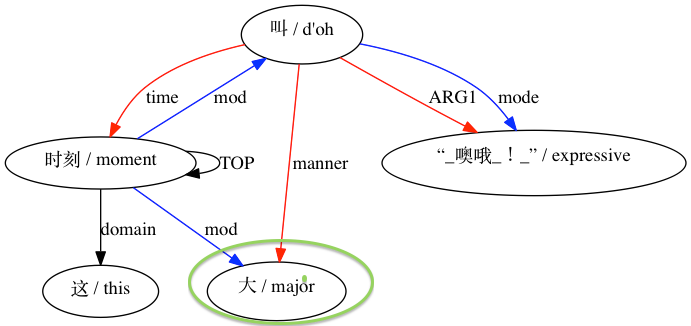
對於被認為不相容的配對:
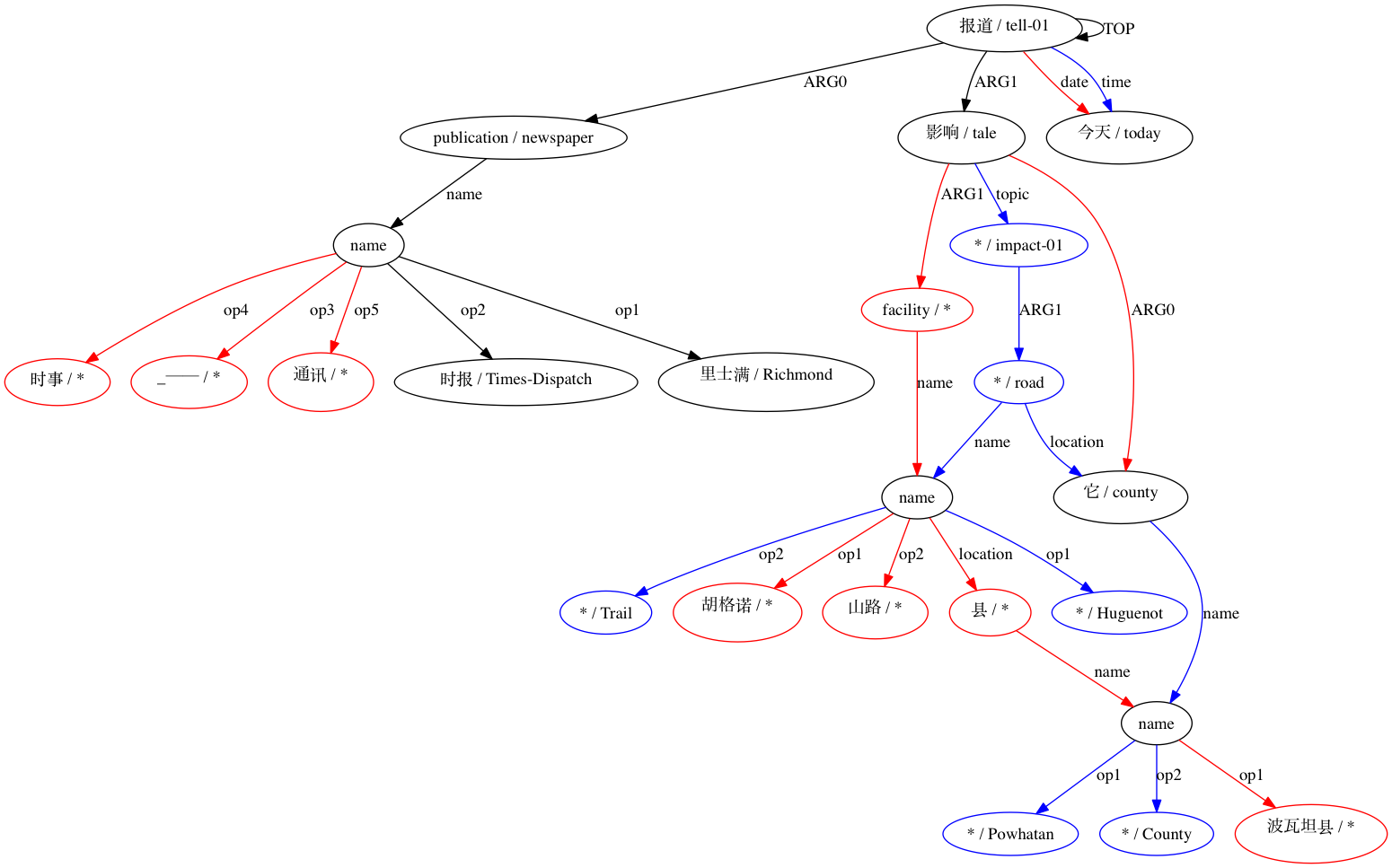
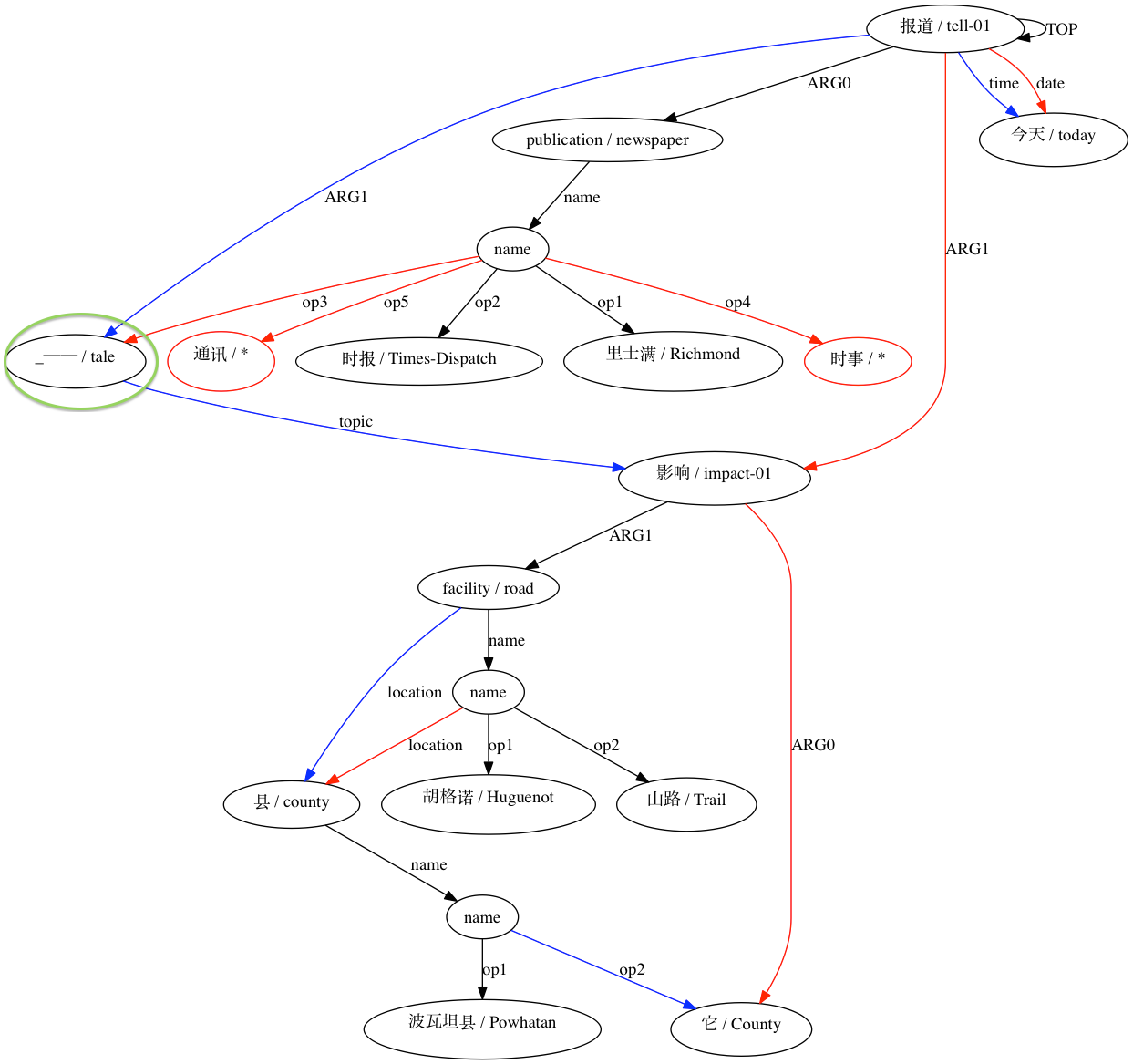
該軟體的開發部分得到了美國國家科學基金會(美國)的支持,獎項為 1349902 和 0530118。


