abbey
1.0.0
修道院是一个具有笔记本,基本聊天,文档,YouTube视频等的AI界面。它在私人的自托管包中精心策划了各种AI模型。您可以使用自己的身份验证提供商将修道院作为服务器作为服务器,也可以在自己的计算机上自行运行。 Abbey使用您选择的LLM,TTS型号,OCR模型和搜索引擎的高度配置。您可以在这里找到托管版的修道院,许多学生和专业人士使用。
有问题吗?请,请发布问题或直接与创作者联系! Twitter dm @gkamer8,发送电子邮件至[email protected]或以其他方式ping他 - 他喜欢它。
如果修道院默认不适合您的喜好配置,并且您可以舒适地编写代码,请考虑以您的改进打开PR!添加新的集成甚至完整的接口很简单;在下面的“贡献”部分中查看更多详细信息。
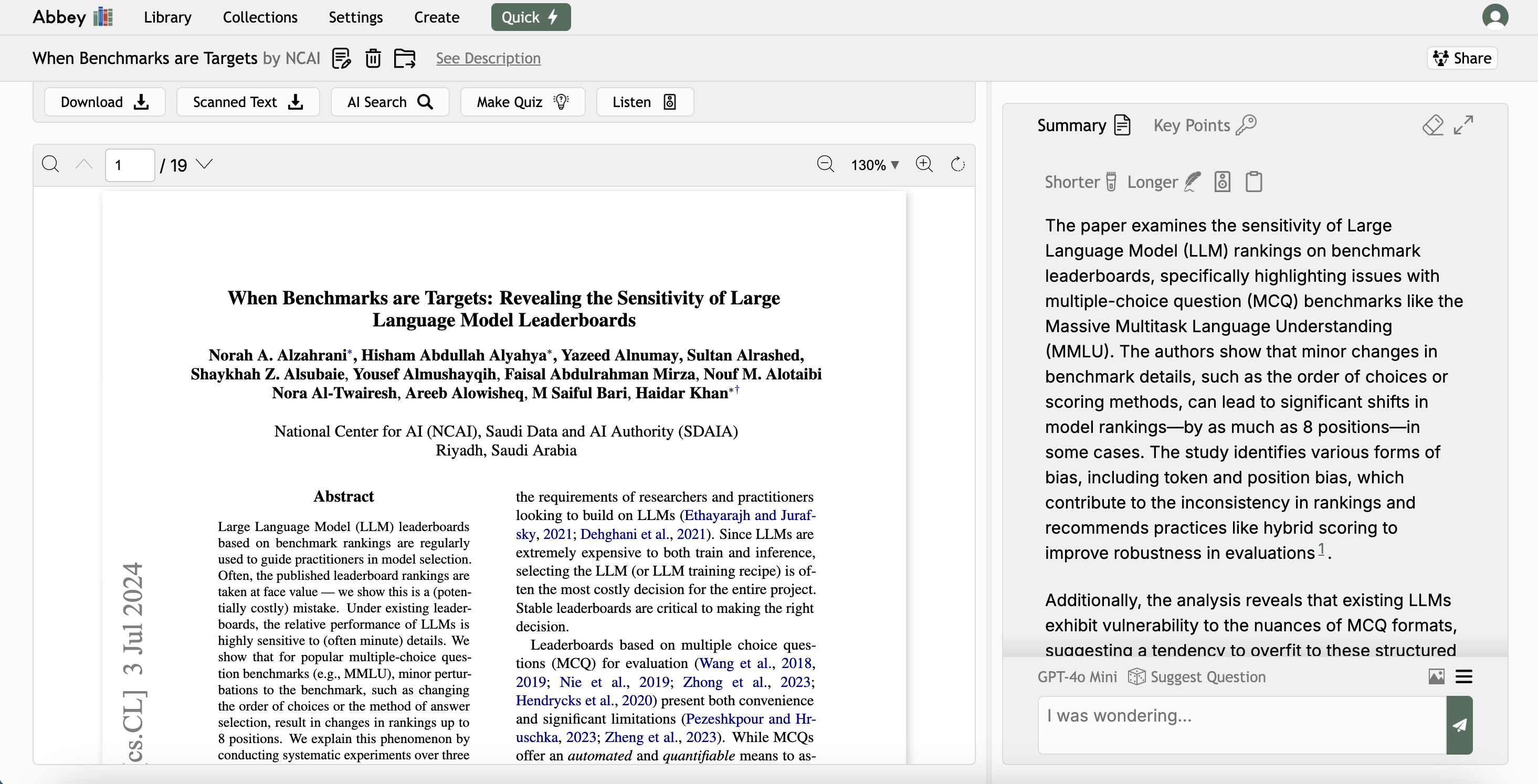
docker compose 。请参阅此处的详细信息。如果您先前有修道院的版本,并且正在使用settings.yml进行“新安装”模式,请拉动,创建一个新的设置。
设置涉及克隆/下载此仓库,创建.env和settings.yml文件,并使用您选择的AI集成,然后运行docker compose为开发(性能较差,但易于使用)或生产(更易于播放)或生产(较好的性能,但更较慢的更改设置)。这是步骤:
步骤1:克隆 /下载此存储库并在其中导航。
步骤2:创建一个名为.env的文件,用于秘密键和一个名为settings.yml docker-compose.yml文件。然后,输入您要使用的键 /模型。您可以找到有关如何在本读书中配置每种集成的详细信息。
.env文件包含您需要的任何API键或其他秘密。您还必须在Abbey使用的MySQL数据库中包含密码。一个用于使用官方OpenAI API的人的.env文件,一个需要键的OpenAI兼容API,拟人API可能看起来像:
MYSQL_ROOT_PASSWORD="my-password"
OPENAI_API_KEY="my-openai-key"
OPENAI_COMPATIBLE_KEY="my-api-key"
ANTHROPIC_API_KEY="my-anthropic-key"
settings.yml文件配置了修道院以使用所需的模型和选项。至少,您必须使用至少一种语言模型和一个嵌入模型。将最佳型号放在首位,以便修道院默认使用它们。例如,这是一个settings.yml文件,该文件使用官方OpenAI API,OpenAI兼容API,人类和Ollama的模型:
lms:
models:
- provider: anthropic
model: "claude-3-5-sonnet-20241022"
name: "Claude 3.5 Sonnet" # optional, give a name for Abbey to use
traits: "Coding" # optional, let Abbey display what it's good for
desc: "One of the best models ever!" # optional, let Abbey show a description
accepts_images: true # optional, put true if the model is a vision model / accepts image input
context_length: 200_000 # optional, defaults to 8192
- provider: openai_compatible
model: "gpt-4o"
accepts_images: true
context_length: 128_000
- provider: ollama
model: "llama3.2"
openai_compatible:
url: "http://host.docker.internal:1234" # Use host.docker.internal for services running on localhost
ollama:
url: "http://host.docker.internal:11434" # Use host.docker.internal for services running on localhost
embeds:
models:
- provider: "openai"
model: "text-embedding-ada-002"
鉴于您还将相关键放入.env中,这将是一个完整的设置文件。要配置不同的型号,请搜索引擎,身份验证服务,文本到语音模型等:请在下面查找适当的文档!
步骤3:如果您仍在使用设置,则可以通过使用以下方式以Dev模式进行修道院。
docker compose up
在开发模式下,当您更改设置 /秘密时,您只需要重新启动容器即可应用设置,可以使用:
docker compose restart backend frontend celery db_pooler
准备好后,您可以在生产模式下进行修道院以提供更好的性能:
docker compose -f docker-compose.prod.yml up --build
如果您想在产品模式下更改设置 /秘密,则需要重建容器:
docker compose down
docker compose -f docker-compose.prod.yml up --build
步骤4:现在,修道院应在http://localhost:3000 !只需在浏览器中访问该URL即可开始使用修道院。在开发模式下,可能需要一秒钟的加载。
请注意,后端在http://localhost:5000 - 如果您去那里,您应该看到吉尔伯特和沙利文的HMS pinafore的歌词。如果没有,则后端没有运行。
如果某件事不正常,请(请)提交问题或直接与创建者联系 - @gkamer8在Twitter或[email protected]上通过电子邮件。
默认情况下,修道院在前端的端口3000上在Localhost上运行,后端为5000。如果您想更改这些(由于您非常精通技术),则需要修改Docker撰写文件,然后将其添加到您的settings.yml中。
services:
backend:
public_url: http://localhost:5000 # Replace with your new user-accessible BACKEND URL
internal_url: http://backend:5000 # This probably won't change - it's where the frontend calls the backend server side, within Docker
frontend:
public_url: http://localhost:3000 # Replace with your new user-accessible FRONTEND URL
请确保通过例如将后端的端口映射更新为1234:5000,如果更改端口,请更新您的Docker组合文件。请确保将其切换为正确的Docker-Compose文件( docker-compose.prod.yml for prod builds, docker-compose.yml for dev)。这就是后端的样子:
backend:
# ... some stuff
ports:
- "1234:5000" # now the backend is at http://localhost:1234 in my browser
# ... some stuff
常规:确保所有Docker容器实际上都使用docker ps运行。您应该看到6:后端,前端,芹菜,redis,mysql和db_pooler(对不起,有很多 - 修道院可以在后台和多个线程中执行AI任务,这需要台球机,Redis和芹菜容器)。如果一个人不运行,请尝试使用docker compose restart backend (或Frontend或Celery,或您有什么)。如果它一直崩溃,您很有可能会弄乱您的settings.yml或忘了将适当的秘密放入.env中。否则,请查看日志。
Docker config Invalid:如果告诉您您的Docker组成是无效的,那么您可能需要将计算机上的Docker升级到某些东西> = = 2版。修道院利用某些相对较新的Docker功能,例如ENV变量和配置文件的默认功能。从长远来看,升级Docker会更容易 - 信任。
事情看起来空白 /不加载 /请求后端似乎不正确。首先,导航到浏览器中的后端,喜欢http://localhost:5000或您最初放置的任何URL。它应该给您一个信息,例如“英国焦油是一个飙升的灵魂……”,如果您看到了,那么后端正在启动并运行,但是您的后端URL配置是错误的或不完整的(您在玩吗?)。如果您的后端不运行,请检查Docker中的日志以获取更多信息 - 请阅读他们说的话!
Docker被卡住下载/安装/运行图像。您的机器上有可能用完空间。首先,尝试运行docker system prune ,清理您忘记的Docker周围的所有讨厌的东西。然后尝试清除计算机上的空间 - 也许足以在计算机上进行〜10GB。然后重新启动Docker,然后重试。如果您仍然遇到问题 - 尝试卸载 /重新安装Docker。
docker compose命令由于某些“ API”问题或其他内容而拒绝运行。如果Docker正在运行(例如,Mac上的Docker Desktop),则应重新启动它。如果没有帮助,请在重新启动之前尝试清除/清洁其数据(如果有的话,请单击Docker桌面中的“错误”图标 - 请参阅clean/purge数据”)。如果Docker不运行,那就是您的问题!您需要确保正在运行Docker守护程序(即Mac上的Docker桌面)。
端口已经被使用。修道院的后端默认情况下在端口5000上运行;修道院前端在端口3000上运行。计算机上的某些东西可能已经在使用端口5000或端口3000。在Mac上,通常意味着播放。您的目标应该是检查端口3000还是5000上的任何内容,如果是的,则关闭这些过程。在Mac/Linux上:使用lsof -i :5000或lsof -i :3000检查是否在这些端口上运行任何过程。如果您注意到像在Mac上运行的“ ControlCe”这样的过程,则意味着“控制中心”,这可能是Airplay接收器的东西。您可以进入Mac上的系统设置,并取消选中“ AirPlay接收器”。如果您找到了其他东西,则可以用kill -9 YOUR_PID杀死它,其中YOUR_PID被过程ID替换(使用LSOF显示)。在Windows上:使用netstat -ano | findstr :5000或netstat -ano | findstr :3000 。然后,您可以使用taskkill /PID YOUR_PID /F杀死该过程,然后用相关过程的过程ID替换YOUR_PID 。
第三方集成在您的设置和环境变量文件中进行管理。这是可用的摘要:
语言模型(LMS)
嵌入模型(嵌入)
文本到语音(TTS)
光学特征识别(OCR)
搜索引擎(网络)
https://api.bing.microsoft.com/v7.0/search )文件存储(存储)
file-storage文件夹(默认)验证
某些集成需要在设置中进行配置。如果使用以下任何集成,则必须这样指定其设置:
s3:
bucket: 'your-bucket'
searxng:
url: "http://host.docker.internal:8080" # Replace with your URL
ollama:
url: "http://host.docker.internal:11434" # Replace with your URL
openai_compatible:
url: "http://host.docker.internal:12345" # Replace with your URL
这些位于settings.yml的根部与lms或embeds相同的水平。
语言模型在lms中配置在settings.yml中。您可以从您希望支持的任何提供商中指定语言模型,以及用于测验生成,摘要和建议问题之类的幕后使用的默认设备。您必须至少有一个LM才能使修道院正常工作。请记住,如果需要,请配置相关的提供商设置,如上所述。
lms:
defaults: # all are optional, use the optional "code" you specify to refer to each model, or use "model-provider" like "gpt-4o-openai"
chat: "llama3.2-ollama" # User chat model (user can change) - defaults to first listed model
fast: "llama3.2-ollama" # Fastest model, used for suggested questions and other places - defaults to chat model
high_performance: "gpt-4o" # Your best language model, used for generating curricula - defaults to default chat model
long_context: "gpt-4o" # Model used in long-context situations - defaults to longest context model specified
balanced: "claude-3-5-sonnet-anthropic" # Model that is in the middle for speed / accuracy - defaults to default chat model
fast_long_context: "gpt-4o-mini-openai" # A long context model that's fast, defaults to long_context model, used for summaries / key points
alt_long_context: "claude-3-5-sonnet" # A long context model used for variation in things like question generation - default to long_context
models:
- provider: openai # required - see below table for options
model: "gpt-4o" # required, code for the API
context_length: 128_000 # optional (defaults to 4096)
supports_json: true # optional, defaults to false
accepts_images: true # optional, defaults to false
name: "GPT-4o" # optional display name for the model
desc: "One of the best models ever!" # optional, lets Abbey display a description
code: "gpt-4o" # optional - defaults to 'model-provider' like 'gpt-4o-openai' - used to specify defaults above.
disabled: false # optional
# Specify more in a list...
该表提供了每个提供商的提供商代码,以及将.env放置的相关API密钥名称:
| 提供者 | 提供商代码 | API密钥名称 | 需要提供商设置 |
|---|---|---|---|
| Openai | Openai | OpenAI_API_KEY | 不 |
| 人类 | 人类 | Anthropic_api_key | 不 |
| 霍拉马 | 霍拉马 | 是的 | |
| Openai兼容 | OpenAi_compatible | OpenAi_compatible_key | 是的 |
文本到语音模型在settings.yml中的tts下配置。您可以从您希望支持的任何提供商中指定TTS模型,以及默认模型。 TTS型号是完全可选的。请记住,如果需要,请配置相关的提供商设置,如上所述。
tts:
default: "openai_onyx"
voices:
- provider: openai # required
voice: "onyx" # required
model: "tts-1" # required
name: "Onyx" # optional
desc: "One of the best models ever!" # optional
code: "openai_onyx" # optional, to set a default via a code (defaults to "voice-model-provider")
sample_url: "https://public-audio-samples.s3.amazonaws.com/onyx.wav" # optional
disabled: false # optional
| 提供者 | 提供商代码 | API密钥名称 | 需要提供商设置 |
|---|---|---|---|
| Openai | Openai | OpenAI_API_KEY | 不 |
| Elevenlabs | eleven_labs | eleven_labs_api_key | 不 |
| Openai兼容 | OpenAi_compatible | OpenAi_compatible_key | 是的 |
嵌入模型是在settings.yml中的embeds下配置的。目前,一次在修道院中使用一个强制性嵌入模型。嵌入模型用于搜索文档。请记住,如果需要,请配置相关的提供商设置,如上所述。
embeds:
models:
- provider: "openai" # required
model: "text-embedding-ada-002" # required
| 提供者 | 提供商代码 | API密钥名称 | 需要提供商设置 |
|---|---|---|---|
| Openai | Openai | OpenAI_API_KEY | 不 |
| 霍拉马 | 霍拉马 | 是的 | |
| Openai兼容 | OpenAi_compatible | OpenAi_compatible_key | 是的 |
搜索引擎在settings.yml中的web下配置。当您在修道院聊天时检查Use Web时,它们会使用。请记住,如果需要,请配置相关的提供商设置,如上所述。
web:
engines:
- provider: "bing" # required
# TO USE SEARXNG, MAKE SURE YOUR SEARXNG SETTINGS ARE CORRECT - SEE [BELOW](#searxng)
- provider: "searxng"
- engine: "pubmed" # Only used for SearXNG - leave blank to search over all engines you've enabled
- provider: "searxng"
engine: "arxiv"
use_pdf: true # Some SearXNG engines give PDF URLs - this tells Abbey to go to the PDF rather than the regular result
| 提供者 | 提供商代码 | API密钥名称 | 需要提供商设置 |
|---|---|---|---|
| bing | bing | bing_api_key | 不 |
| searxng | searxng | 是的 |
默认情况下,Searxng不允许访问API。运行SEARXNG实例时,您必须确保您的searxng设置(不是在修道院的仓库中,而是在searxng/settings.yml中)允许JSON作为格式,例如:
search:
formats:
- html
- json
您可以在以下curl请求起作用时确保您的SEARXNG实例正常工作(用SEARXNG实例URL替换URL - 端口可能不同。
curl -kLX GET --data-urlencode q='abbey ai' -d format=json http://localhost:8080
光学字符识别API在ocr下配置在settings.yml中。默认情况下,没有使用OCR。可选的配置OCR允许修道院读取扫描的PDF。修道院会自动确定是否需要OCR。
ocr:
models:
- provider: "mathpix"
| 提供者 | 提供商代码 | API密钥名称 | 需要提供商设置 |
|---|---|---|---|
| MathPix | MathPix | MATHPIX_API_APP和MATHPIX_API_KEY | 不 |
电子邮件API在settings.yml中的email中配置。配置电子邮件使修道院共享时可以将链接发送到Abbey的资产,以及在其他一些情况下。默认情况下,修道院不发送电子邮件。使用电子邮件配置文件(例如docker compose up --profile email )运行Abbey,Abbey可以为某些模板发送其他提醒电子邮件。
email:
default: smtp # Refer to each service by its provider name (defaults to first specified)
services:
- provider: sendgrid # Required
email: "[email protected]" # Required
unsub_group: 24624 # Optional, only for Sendgrid
- provider: smtp # Regular email
email: "[email protected]"
| 提供者 | 提供商代码 | 强制性秘密 | 需要提供商设置 |
|---|---|---|---|
| sendgrid | sendgrid | sendgrid_api_key | 不 |
| SMTP电子邮件 | SMTP | smtp_server,smtp_port,smtp_email和smtp_password | 不 |
文件存储API在settings.yml中的storage下配置。默认情况下,修道院将所有已上传的文件存储在已安装的file-storage文件夹中。备份修道院时,您应该备份该文件夹以及数据库。如果要使用S3,则可以使用以下内容:
storage:
default: s3 # All new uploads go to the default provider (you don't need to set up local)
locations:
- provider: s3
| 提供者 | 提供商代码 | API密钥名称 | 需要提供商设置 |
|---|---|---|---|
| S3 | S3 | AWS_ACCESS_KEY和AWS_SECRET_KEY | 不 |
| 当地的 | 当地的 | 不 |
身份验证提供商在settings.yml中的auth下配置。默认情况下,修道院将使用单个“默认”用户。设置其他身份验证提供程序允许多用户设置。您可以使用诸如Google之类的OAuth2提供商,也可以自我托管keycloak实例(下面的说明)。对于像Google和Github这样的提供商,您需要客户秘密和客户端ID。注册修道院时,您可能必须提供可访问修道院的URL - 默认情况下是http://localhost:3000 ,或您用于Abbey的前端的任何公共URL。
auth:
providers:
- google
- github
- keycloak
| 提供者 | 提供商代码 | env变量 | 如何获取客户ID /秘密 |
|---|---|---|---|
| 谷歌 | 谷歌 | Google_client_id和Google_secret | 请参阅此处 |
| github | github | github_client_id和github_secret | 请参阅此处 |
| KeyCloak | KeyCloak | keycloak_public_url,keycloak_internal_url,keycloak_realm,keycloak_secret和keycloak_client_id | 见下文 |
在生产环境中,您还应提供处理验证令牌的其他秘密。通过将以下内容添加到您的环境文件中:
CUSTOM_AUTH_SECRET="my-auth-secret"
REFRESH_TOKEN_SECRET="my-refresh-secret"
您可以完全使用KeyCloak完全自主身份验证。使用KeyCloak与修道院需要某些设置 - 例如,必须指定领域的前端URL,以允许修道院和KeyCloak在同一Docker VM中运行。如果您有现有的KeyCloak实例,则应为您放置在.env中的客户ID和客户端秘密创建一个新的Abbey客户端。否则,以下说明正在为修道院设置新实例:
这是一个keycloak-realm.json文件,您可以将自动设置KeyCloak的docker-compose文件旁边放置:
{
"realm": "abbey-realm",
"enabled": true,
"loginWithEmailAllowed": true,
"duplicateEmailsAllowed": false,
"registrationEmailAsUsername": true,
"attributes": {
"frontendUrl": "http://localhost:8080"
},
"clients": [
{
"clientId": "abbey-client",
"enabled": true,
"protocol": "openid-connect",
"publicClient": false,
"secret": "not-a-secret",
"redirectUris": ["http://localhost:3000/*"]
}
],
"users": [
{
"username": "[email protected]",
"email": "[email protected]",
"enabled": true,
"emailVerified": true,
"credentials": [
{
"type": "password",
"value": "password"
}
]
}
]
}
这是您可以与docker-compose.yml文件一起运行的示例服务:
services:
keycloak:
image: quay.io/keycloak/keycloak:22.0.3
container_name: keycloak
environment:
KEYCLOAK_ADMIN: admin
KEYCLOAK_ADMIN_PASSWORD: admin
ports:
- 8080:8080
volumes:
- ./keycloak-realm.json:/opt/keycloak/data/import/myrealm.json
command: ["start-dev", "--import-realm"]
volumes:
keycloak_data:
KeyCloak在.env中还需要一些其他秘密:
# The Public URL should be user accessible
KEYCLOAK_PUBLIC_URL="http://localhost:8080"
# The optional Internal URL should be accessible within Docker
KEYCLOAK_INTERNAL_URL="http://keycloak:8080"
KEYCLOAK_REALM="abbey-realm"
KEYCLOAK_SECRET="not-a-secret"
KEYCLOAK_CLIENT_ID="abbey-client"
添加该服务 +创建keycloak-realm.json文件 +将秘密输入.env中应允许修道院在开发环境中与KeyCloak“仅使用”。
默认情况下,修道院具有MySQL服务,您必须在.env中提供MYSQL_ROOT_PASSWORD 。修道院使用两个数据库, custom_auth进行身份验证并learn其他所有内容。它们可以在相同或不同的服务器上。截至目前,服务器必须是MySQL或MySQL兼容(不是Postgres)。
您可以使用以下.env变量更改MySQL Server可用的位置:
MYSQL_ROOT_PASSWORD=my-root-password
# Remember that the endpoint is accessed server side, so "mysql" is the default network name
DB_ENDPOINT=mysql
DB_USERNAME=root
DB_PASSWORD=my-root-password
DB_PORT=3306
DB_NAME=learn
DB_TYPE=local # 'local' or 'deployed' --> changes how app deals with transaction settings
# You should set global transaction isolation level to READ COMMITTED when using your own database
CUSTOM_AUTH_DB_ENDPOINT=mysql
CUSTOM_AUTH_DB_USERNAME=root
CUSTOM_AUTH_DB_PASSWORD=my-root-password
CUSTOM_AUTH_DB_PORT=3306
CUSTOM_AUTH_DB_NAME=custom_auth
当启动默认的MySQL服务时,它将使用mysql-init中的文件初始化自身。如果您设置了自己的MySQL服务,则通过运行这些.sql文件(复制并粘贴到终端就足够)来初始化相关数据库 /表。
您可能会注意到,在主页上(在签名时),右侧具有图像和描述。关于数据库的初始化,默认情况下将出现一个图像(托管在Internet上)。要更改该图像或添加更多图像,您需要在学习数据库中的ART_HISTORY表中添加条目(在MySQL服务上)。在那里,您为图像放置了一个URL,并为描述降低了。图像的托管所需的域也需要包含在settings.yml中。
images:
domains:
- "my-domain.com"
要将条目添加到Art_history中,您需要执行一些SQL。使用Docker-Compose,您可以使用:
docker-compose exec mysql mysql -u root -p
然后使用您的MySQL root密码(在项目根部的.env文件中可用)。然后,您需要执行:
use learn;
INSERT INTO art_history (`markdown`, `image`)
VALUES ('This is my *description*', 'https://my-domain.com/image.webp');
随机选择图像以从该art_history表中显示。
您可以将修道院的名称更改为您喜欢在settings.yml中使用此选项的任何内容:yml:
name: "Abbey" # Replace with your chosen name
其他品牌(例如徽标,Favicons等)位于frontend/public 。您可以通过更换文件(但要保留其名称)来更改它们。背景图像在frontend/public/random文件夹中。
默认情况下,当后端启动和此后的每个小时时,修道院将在一个硬编码的URL上播放一个硬编码的URL。这样做是为了跟踪使用统计信息。您正在使用的后端版本加上settings.yml包含在ping中。要禁用ping,请将以下内容放在您的settings.yml中。
ping: false
由于我无法判断一个设置ping: false和一个停止使用修道院的用户,请考虑与[email protected]接触,这样我就可以得到大量禁用PING的用户。
修道院的主要优势之一是它的扩展性。您可以直接实现新的集成和接口。
除auth(请参见下文)以外的每种集成类型都位于backend/app/integrations中的文件中。每种类型的集成都实现了特定的类(例如, lm.py给出了LM类,每种类型的集成都实现了该类别)。您可以简单地添加从基类继承的类(LM,TTS,OCR等)。然后,您应该将您的类添加到PROVIDER_TO_ dictionary(每种类型的集成都不同)。对于用户可以选择的集成,一旦在settings.yml中进行了适当的更改。对于默认情况下由Abbey选择的embed之类的集成,您应该确保您的集成是settings.yml中的默认值。
如果您的集成依赖于秘密,则应使用指定的模式将其添加到backend/app/configs/secrets.py ,然后将其导入集成文件(例如, lm.py )。
与其他集成不同,如果您只是添加OAuth2提供商,则实际上没有理由在烧瓶后端做任何事情。 Next.js前端服务器处理所有内容。您需要做的是:
frontend/src/pages/api/auth/[...auth].js中创建一个提供商类。最简单的示例是提供三个URL的GoogleAuth类(扩展baseauth):OAuth2 auth端点; OAuth2令牌端点;和OpenID连接用户信息端点。由于GitHub未实现标准OpenID连接,因此它直接实现了GetUserData()函数。authProviders变量中。frontend/src/auth/custom.js中为该提供商创建一个前端登录按钮。首先,这意味着要根据是否设置为1的环境变量来enabledProviders新提供商的代码(环境变量必须从next_public开始),以便它可用的客户端。其次,这意味着将对象添加到providers列表中指定您的提供商代码和按钮值(您可以通过遵循模式并将徽标添加到frontend/public/random中添加提供商的徽标)。 搜索引擎上的一个注释:搜索引擎返回自定义搜索对象的某些类功能;相关类是在web.py中实现的,如果您选择实现新的搜索引擎集成,则应查看。
在修道院中,一切都是“资产”,每个资产都实现了“模板”。例如,如果您上传文档,它将成为模板document的“资产”。同样,如果创建一个新的工作区,它将成为模板notebook (工作区的内部名称)的“资产”。在前端,提供给用户的接口由他查看的模板确定。每个模板都必须设置一系列常见变量(例如,是否允许模板与文件夹中的模板聊天或类似的模板)。这些变量和实现功能决定了/asset/chat等一般端点的方式。
在后端,所有模板都是从Template基类继承的类。这些模板位于其自己的文件中,在backend/app/templates中。模板在backend/app/templates.py中注册。您必须在此处添加模板的实例才能启用它。您还必须将模板添加到backend/app/configs/user_config.py 。在模板文件中也可能是该模板的特定端点。如果选择创建一个,则必须在backend/app/__init__.py中注册。
在前端,所有模板均在一个文件中实现, frontend/src/template.js 。每个模板都有一个从Template类继承的类。在文件的底部,有各种列表和对象确定模板的可用性;您至少必须将模板添加到TEMPLATES对象中才能使用户可用。
一些模板就像叶子。例如,文档没有链接的资产来源,这意味着,当您与文档聊天时,您只能与该文档聊天。其他模板具有链接的来源。例如,文件夹的内容是链接的资产。该系统存在于其他模板(例如文本编辑器)的其他模板,该模板可以从其他资产中以其AI写入功能获取材料。以一致的方式使用源可以确保跨模板(例如共享资产)扩展的功能仍然有效。例如,如果您与某人共享一个文件夹,例如,权限将传播到该文件夹中的所有项目。
检索前端资产源信息的标准方法是/assets/sources-info端点。将源添加到资产的标准方法是端点/assets/add-resource和/assets/add-resources 。这些端点正在寻找asset_metadata表中的条目,其中具有键retrieval_source ,其值为资产ID。在backend/app/assets.py中查看有关这些端点的更多详细信息。


