hamza
1.0.0
HAMZA是一个仅标题,快速和便携式C99 Unicode/Opentype构建和渲染库。它旨在是一个易于集成到任何现有项目的小型,便携式和优化的塑造器。下面是使用相当复杂的字体,将随机颜色分配给每个字形的简短的阿拉伯语形状的短字符串。 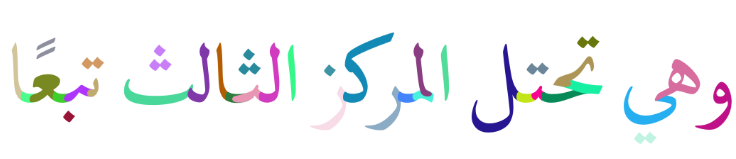
HAMZA包括单文件程序update_ucd_ftp和generate_ucd_headers 。第一个从ftp.unicode.org上从FTP服务器中摘取必要的UCD文件,并需要卷曲。第二个从这些UCD文件中生成了优化的C标头。这两个程序都利用Posix Regex库进行过滤和解析。
下载UCD TXT,这可能需要几分钟,因此只有在UCD标题过时时才这样做:
./build/update_ucd_ftp生成UCD版本的标头文件:
./build/generate_ucd_headers要开始使用HAMZA,请在包括hz.h之前定义HZ_IMPLEMENTATION 。您可以选择为HZ_NO_STDLIB定义。还必须为您需要的版本包含UCD的标头。我们稍后将解释如何生成它们以及如何自己更新它们。
#define HZ_IMPLEMENTATION
#include <hz/hz_ucd_15_0_0.h>
#include <hz/hz.h>要初始化库首先填充hz_config_t struct并致电hz_init :
hz_config_t cfg = {
};
if ( hz_init ( & cfg ) != HZ_OK ) {
fprintf ( stderr , "%sn" , "Failed to initialize Hamza!" );
return -1 ;
}接下来,在塑造任何文本之前,必须提供字体数据。您需要将字体加载到stbtt_fontinfo结构中。 HAMZA包含stb_truetype.h ,旨在用于读取字体。要从STBTT字体创建hz_font_t ,请写下:
hz_font_t * font = hz_stbtt_font_create ( & fontinfo ); HAMZA的目的是让用户尽可能管理内存分配和数据。在构建字体之前,必须将数据解析为hz_font_data_t结构。这保留了使用特定字体塑造所需的所有Opentype表数据。 hz_font_data_init函数作为参数将其分配多少内存以持有该字体的数据:
hz_font_data_t font_data ;
hz_font_data_init ( & font_data , 1024 * 1024 ); // 1MiB
hz_font_data_load ( & font_data , font );创建一个造型并初始化它:
hz_shaper_t shaper ;
hz_shaper_init ( & shaper );设置造型者的必需参数:
hz_shaper_set_direction ( & shaper , HZ_DIRECTION_RTL );
hz_shaper_set_script ( & shaper , HZ_SCRIPT_ARABIC );
hz_shaper_set_language ( & shaper , HZ_LANGUAGE_ARABIC );设置塑造器的排版功能:
hz_feature_t features [] = {
HZ_FEATURE_ISOL ,
HZ_FEATURE_INIT ,
HZ_FEATURE_MEDI ,
HZ_FEATURE_FINA ,
HZ_FEATURE_RLIG ,
HZ_FEATURE_LIGA ,
};
hz_shaper_set_features ( & shaper , features , sizeof ( features )/ sizeof ( features [ 0 ]));创建字形缓冲液和形状!
hz_buffer_t buffer ;
hz_buffer_init ( & buffer );
hz_shape_sz1 ( & shaper , & font_data , HZ_ENCODING_UTF8 , "السلام عليكم" , & buffer );之后,您可以访问缓冲区的字形数据并渲染。完成所有必须进行脱位的一切之后。
hz_buffer_release ( & buffer );
hz_font_data_release ( & font_data );
hz_font_destroy ( font );
hz_deinit ();.aat .woff和.woff2格式HAMZA获得了LGPLV3的许可。


