PyArmor Unpacker
1.0.0
我认为是时候发布适当的Pyarmor拆开式释放了。当前公共的所有产品要么过时,根本不起作用,要么仅提供部分输出。我计划使这一支持最新版本的Pyarmor。
如果您发现它有用,请标记存储库。我真的很感激。
在此存储库中的方法文件夹中,有3种不同的方法来解开Pyarmor,您将找到每个方法所需的所有文件。在下面,您会找到有关我如何一直到最终产品的详细文章。我希望更多的人实际上了解它的工作方式,而不仅仅是使用该工具。
这是所有已知问题/缺失功能的列表。我没有足够的时间自己修复它们,所以我很大程度上依靠贡献者。
问题:
缺少功能:
重要的是:在各处使用相同的Python版本,查看您要拆开的程序所包含的程序。如果您不这样做,您将面临问题。
method_1.py文件run.py运行部分解开的程序dumps目录”中,您可以找到完全打开包装的.pyc文件。注意:请勿将静态解开器用于3.9.7版本以下的任何内容, marshal.loads审核日志仅在3.9.7之后添加。欢迎任何贡献者增加支持
python3 bypass.py filename.pyc (显然,用实际文件名替换filename.pyc )dumps目录”中,您可以找到完全打开包装的.pyc文件。贡献确实很重要。我没有足够的时间来解决上述所有问题。如果可以的话,请做出贡献。
捐款也非常欢迎:
BTC -37RQ1XEB5Q8SCMMKKKKK3MVMD4RBE5FV7EMMH
ETH -0x28152666867856FA48B3924C185D7E1FB36F3B9A
LTC -MFHDLRDZAQYGZXXUVXQFM4RWVGBMRZMDZAO
这是关于我去除颠覆或拆开Pyarmor的完整过程的期待已久的文章,我将仔细研究我所做的所有研究,最后提供3种拆开Pyarmor的方法,它们都是独特的,并且适用于不同的情况。我想提一下,我对Python内部的了解不多,所以对我来说花了很多时间比其他在python内部经验的人更长。
Pyarmor拥有有关他们如何完成所有操作的非常广泛的文档,我建议您完全阅读。 Pyarmor实质上循环通过每个代码对象并对其进行加密。虽然有一个固定的标头和页脚。这取决于是否启用了“包装模式”,默认情况下是。
wrap header:
LOAD_GLOBALS N (__armor_enter__) N = length of co_consts
CALL_FUNCTION 0
POP_TOP
SETUP_FINALLY X (jump to wrap footer) X = size of original byte code
changed original byte code:
Increase oparg of each absolute jump instruction by the size of wrap header
Obfuscate original byte code
...
wrap footer:
LOAD_GLOBALS N + 1 (__armor_exit__)
CALL_FUNCTION 0
POP_TOP
END_FINALLY
来自Pyarmor文档
在标题中,有一个呼叫__armor_enter__函数,该功能将在内存中解密代码对象。在代码对象完成后,将调用__armor_exit__将再次重新加密代码对象,以便没有解密的代码对象在内存中落后。
当我们编译Pyarmor脚本时,我们可以看到有入口点文件和Pytransform文件夹。该文件夹包含一个dll和__init__.py文件。
dist
│ test.py
└───pytransform
| _pytransform.dll
| __init__.py
__init__.py文件不必在解密代码对象方面做得太多。它主要使用,因此我们可以导入模块。它可以进行一些检查,例如您使用的操作系统,如果您想阅读它,则是开源的,因此您可以像普通的Python脚本一样打开它。
它最重要的是加载_pytransform.dll并将其功能暴露于Python解释器的Globals。在所有脚本中,我们都可以看到,从pytransform导入pyarmor_runtime。
from pytransform import pyarmor_runtime
pyarmor_runtime ()
__pyarmor__ ( __name__ , __file__ , b' x50 x59 x41 x5...' )此功能将创建运行Pyarmor脚本所需的所有功能,例如__armor_enter__和__armor_exit__函数。
我发现的第一个资源是在tuts4you论坛上的该线程,在这里,用户extremecoders在这里撰写了一些有关他如何打开Pyarmor受保护文件的文章。他编辑了CPYTHON源代码,以丢弃执行每个代码对象的元帅。
尽管此方法非常适合公开所有常数,但如果您想获得字节码,则不太理想,这是因为:
__armor_enter__函数时才发生,而该函数在代码对象的开头。由于__armor_enter__函数将其解密在内存中,因此不会被CPYTHON倾倒。有些人通过注入Python代码来尝试从内存中倾倒解密的代码对象。
在此视频中,有人演示了他如何在内存中解密所有解密的功能。
但是,他尚未找到如何抛弃主模块,只有功能。值得庆幸的是,他发表了他用来注入Python代码的代码。在GitHub存储库上,我们可以看到他创建了一个DLL,其中他称其为从Python DLL中的导出函数来执行简单的Python代码。目前,他仅添加了为3.7至3.9版本的Python DLL找到的支持,但是您可以通过修改源并重新编译来轻松添加更多版本。他做到了这一点,因此它执行了Code.py中找到的代码,这样就可以轻松编辑Python代码,而无需每次重建项目。
在存储库中,他包括一个python文件,该文件将把所有函数的名称都转移到一个带有相应地址的文件中,如果没有记忆,则该文件尚未被调用,因此尚未被解密。
# Copyright holder: https://github.com/call-042PE
# License: GNU GPL v3.0 (https://github.com/call-042PE/PyInjector/blob/main/LICENSE)
import os , sys , inspect , re , dis , json , types
hexaPattern = re . compile ( r'b0x[0-9A-F]+b' )
def GetAllFunctions (): # get all function in a script
functionFile = open ( "dumpedMembers.txt" , "w+" )
members = inspect . getmembers ( sys . modules [ __name__ ]) # the code will take all the members in the __main__ module, the main problem is that it can't dump main code function
for member in members :
match = re . search ( hexaPattern , str ( member [ 1 ]))
if ( match ):
functionFile . write ( "{ " functionName " : " " + str ( member [ 0 ]) + " " , " functionAddr " : " " + match . group ( 0 ) + " " } n " )
else :
functionFile . write ( "{ " functionName " : " " + str ( member [ 0 ]) + " " , " functionAddr " :null} n " )
functionFile . close ()
GetAllFunctions ()来自Call-042PE的存储库
在代码中,您可以看到他添加了评论,说他遇到的问题是他无法访问主模块代码对象。
经过大量谷歌搜索后,我被困了,找不到有关如何获取当前运行代码对象的信息。在一个不相关的项目中的某个时候,我看到了一个函数调用sys._getframe() 。我对它的作用进行了一些研究,它得到了当前的运行框架。
您可以将整数作为一个参数,该参数将沿着呼叫堆栈行走,并以特定的索引获取框架。
sys . _getframe ( 1 ) # get the caller's frame现在,这很重要的原因是因为Python中的框架基本上只是一个代码对象,但有关其状态中的更多信息。为了从框架获取代码对象,我们可以使用.f_code属性,如果您创建了一个自定义的CPYTHON版本,您也将熟悉此属性,该版本转储在我们也从那里获得代码对象的代码对象。
...
1443 tstate -> frame = frame ;
1444 co = frame -> f_code ;
...从我的自定义cpython版本中
因此,现在我们已经弄清楚了如何获取当前的运行代码对象,我们可以简单地向上走呼叫堆栈,直到找到将被解密的主模块。
现在,我们几乎已经弄清楚了如何解开Pyarmor的主要思想。现在,我将展示三种解开包装的方法,我个人在不同情况下个人发现有用。
第一个要求您注入Python代码,因此您必须运行Pyarmor脚本。当我们像我在主要问题上解释的主代码对象一样,将仍然将某些函数加密,因此第一个方法调用Pyarmor运行时函数,因此加载了代码对象所需的所有功能,例如__armor_enter__ and ____________enter__ and __armor_exit__ 。
这似乎是一件很简单的事情,但是Pyarmor确实考虑了这一点,他们实现了限制模式。您可以在编译Pyarmor脚本时指定此内容,默认情况下,限制模式为1。
我尚未测试每个限制模式,但它适用于默认模式。
当我们尝试在REPL中运行此代码时,您将收到以下错误:
> >> from pytransform import pyarmor_runtime
> >> pyarmor_runtime ()
Check bootstrap restrict mode failed这样可以防止我们能够使用__armor_enter__和__armor_exit__ 。
因此,我采取的下一步是与Tuts4You上的extremecoders联系。他通过提到我可以在_pytransform.dll上进行修补。我还要感谢他为我提供了仅在Python做这件事的解决方案。
如果我们在本机调试器中打开_pytransform.dll ,我选择了x64dbg,我们将在当前模块中寻找所有字符串。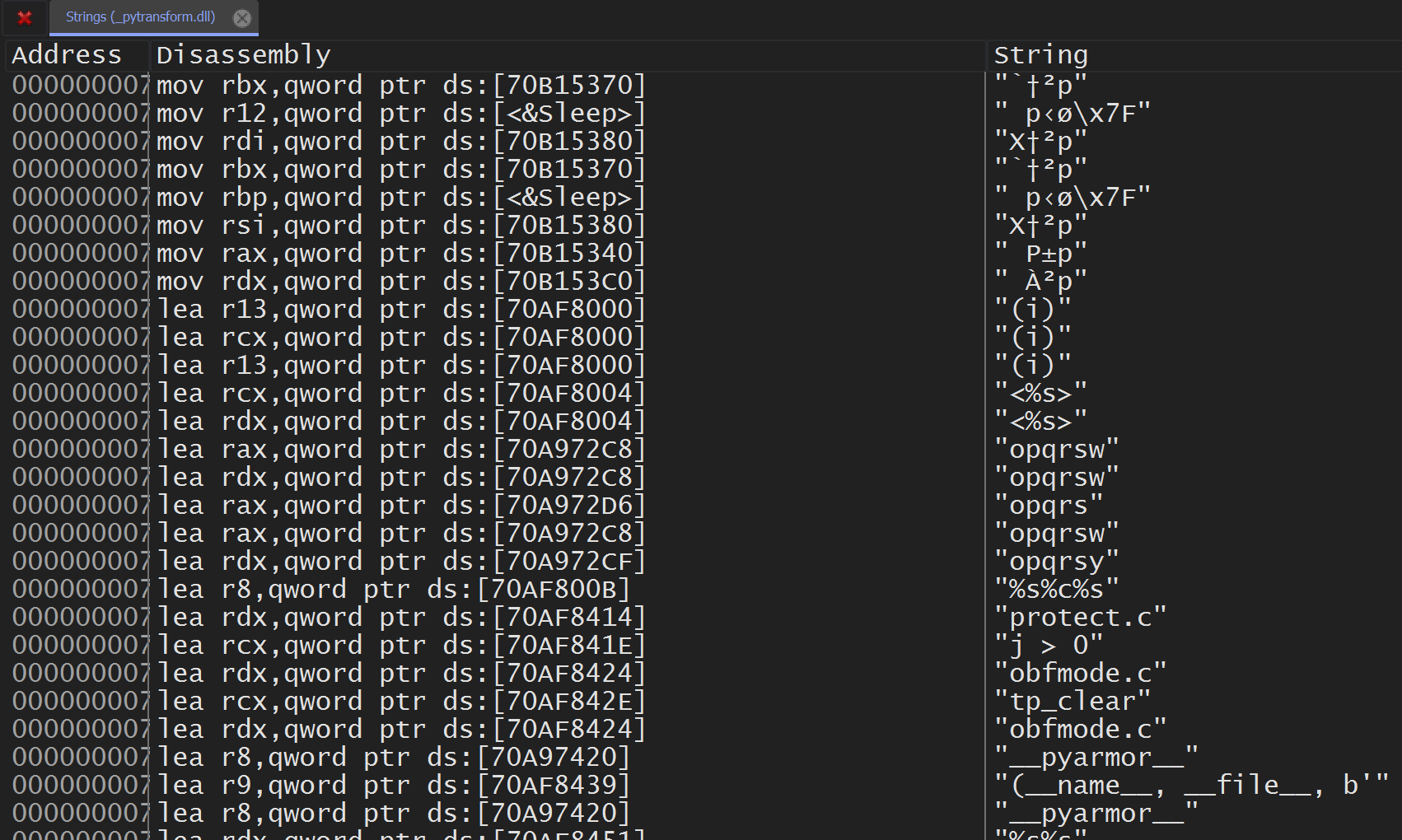
如果我们现在通过搜索“ bootstrap”来过滤它,我们将获得以下内容。
当我们在第一个搜索结果上观看拆卸时,您会看到_errno的引用表明可能会出现一些错误,低于几行,我们可以看到我们在Python中遇到的错误。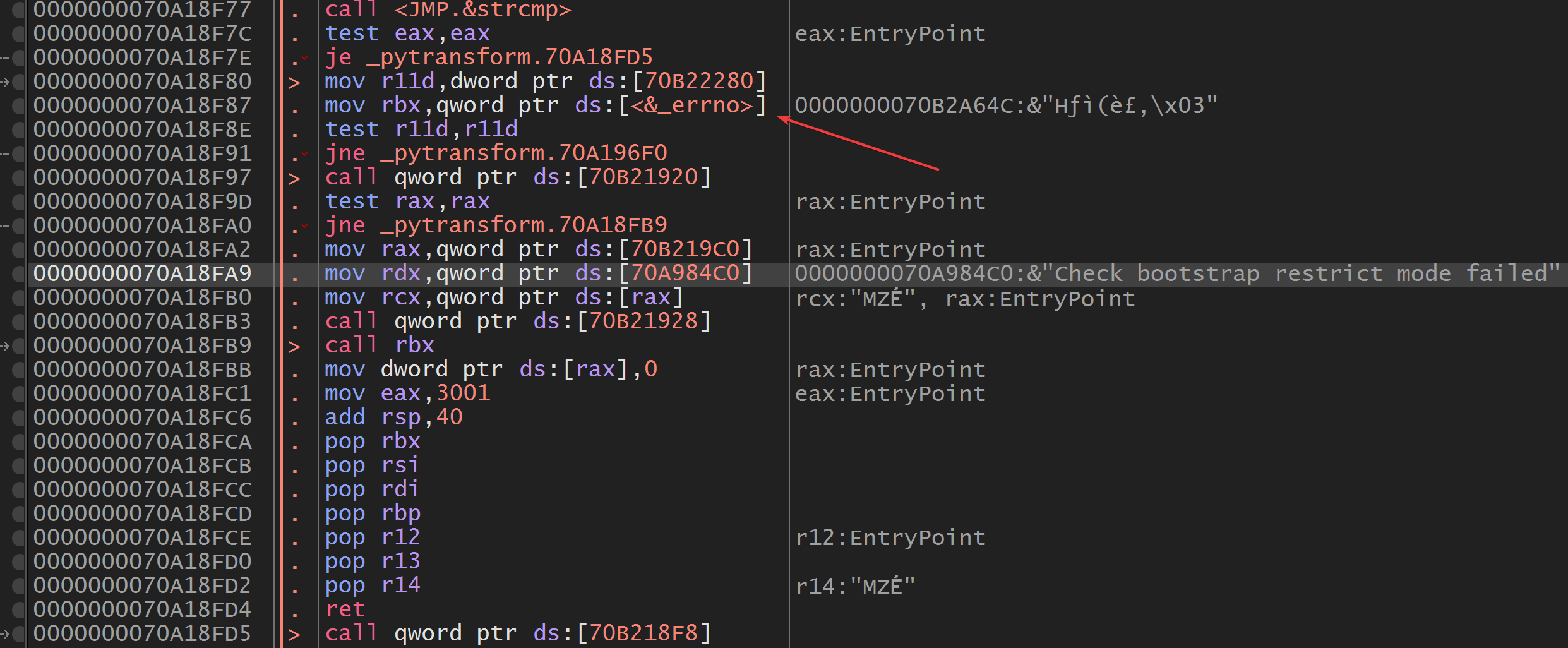
当我们只是从跳跃的跳转点上毫无疑问的所有内容时,触发错误到返回的代码,就无法提出错误。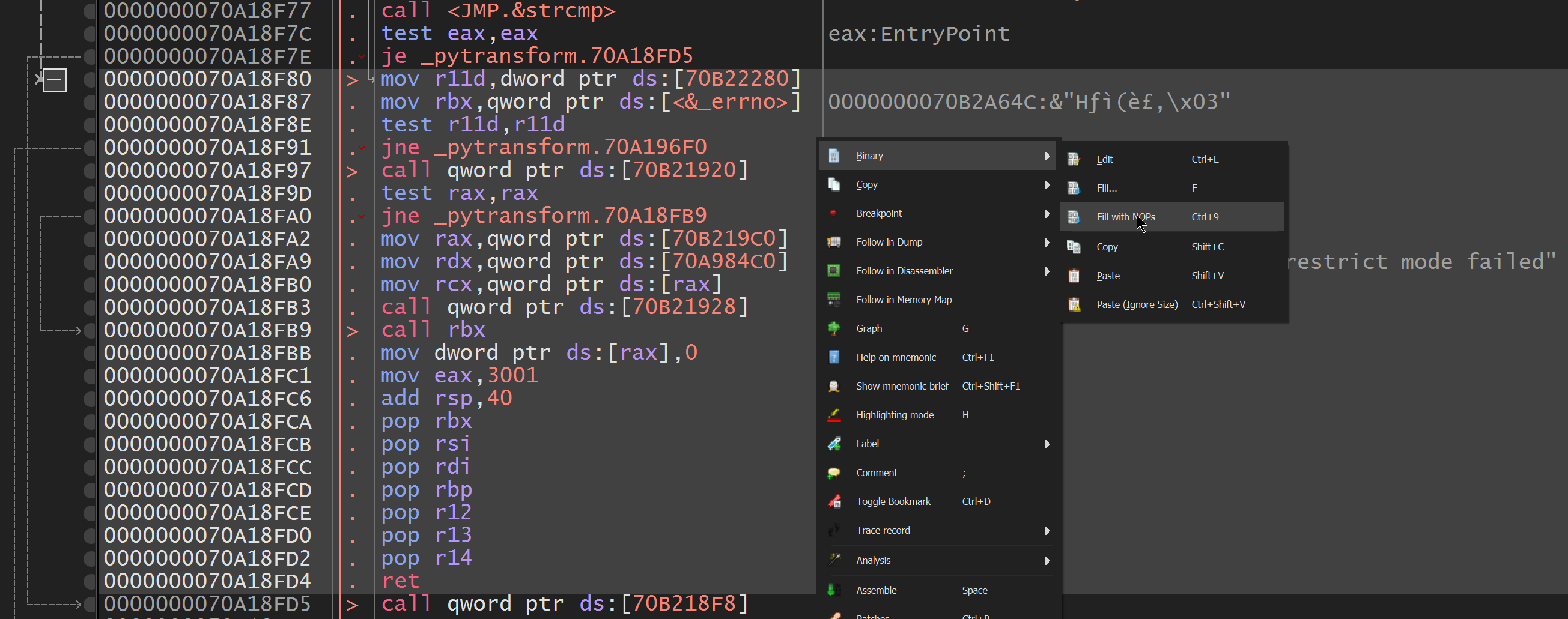
现在,如果我们保存它并替换_pytransform.dll ,您会看到,当我们再次尝试相同的代码时,错误将不会发生,并且我们可以访问__armor_enter__和__armor_exit__函数。
> >> from pytransform import pyarmor_runtime
> >> pyarmor_runtime ()
> >> __armor_enter__
< built - in function __armor_enter__ >
> >> __armor_exit__
< built - in function __armor_exit__ >现在,如果我们必须为要打开包装的每个Pyarmor脚本执行此操作,这将很累,因此extremecoders制作了一个脚本,可以将Memory中的特定地址指向Python中的特定地址。
# Credit to extremecoders (https://forum.tuts4you.com/profile/79240-extreme-coders/) for writing the script
# Credit to me for adding the comments explaining it
import ctypes
from ctypes . wintypes import *
VirtualProtect = ctypes . windll . kernel32 . VirtualProtect
VirtualProtect . argtypes = [ LPVOID , ctypes . c_size_t , DWORD , PDWORD ]
VirtualProtect . restype = BOOL
# Load the dll in memory, this is useful because once it's loaded in memory it won't need to get loaded again so all the changes we make will be kept, including the bootstrap bypass
h_pytransform = ctypes . cdll . LoadLibrary ( "pytransform \ _pytransform.dll" )
pytransform_base = h_pytransform . _handle # Get the memory address where the dll is loaded
print ( "[+] _pytransform.dll loaded at" , hex ( pytransform_base ))
# We got this offset like I showed above with x64dbg, it's the first address where we start the NOP
patch_offset = 0x70A18F80 - pytransform_base
num_nops = 0x70A18FD5 - 0x70A18F80 # Minus the end address, this is the size that the NOP will be. The result will be 0x55
oldprotect = DWORD ( 0 )
PAGE_EXECUTE_READWRITE = DWORD ( 0x40 )
print ( "[+] Setting memory permissions" )
VirtualProtect ( pytransform_base + patch_offset , num_nops , PAGE_EXECUTE_READWRITE , ctypes . byref ( oldprotect ))
print ( "[+] Patching bootstrap restrict mode" )
ctypes . memset ( pytransform_base + patch_offset , 0x90 , num_nops ) # 0x90 is NOP
print ( "[+] Restoring memory permission" )
VirtualProtect ( pytransform_base + patch_offset , num_nops , oldprotect , ctypes . byref ( oldprotect ))
print ( "[+] All done! Pyarmor bootstrap restrict mode disabled" )如果我们将此代码a放在名为restrict_bypass.py _pytransform.dll文件中
> >> import restrict_bypass
[ + ] _pytransform . dll loaded at 0x70a00000
[ + ] Setting memory permissions
[ + ] Patching bootstrap restrict mode
[ + ] Restoring memory permission
[ + ] All done ! Pyarmor bootstrap restrict mode disabled
>> > from pytransform import pyarmor_runtime
>> > pyarmor_runtime ()
>> > __armor_enter__
< built - in function __armor_enter__ >
> >> __armor_exit__
< built - in function __armor_exit__ > 第二种方法开始与第一个方法相同,我们注入获取当前运行代码对象的脚本。
只有现在,不同之处在于,我们不仅会抛弃它,我们会“修复”它。我的意思是完全从中删除Pyarmor,以便我们获得原始代码对象。
由于Pyarmor在混淆时有多种选择,因此我决定增加对所有常见的支持。
当它检测到脚本中的__armor_enter__时,它将对其进行修改,以便在调用__armor_enter__之后立即返回代码对象。
在函数调用之后,有一个POP_TOP OPCODE,它可以使用该函数的返回值从堆栈中删除,我们只需将其替换为RETURN_VALUE opcode,以便我们可以在不实际运行原始bytecode的内存中获得__armor_enter__功能的返回值,以便我们在内存中具有解密的代码对象。请参阅下面的示例
1 0 JUMP_ABSOLUTE 18
2 NOP
4 NOP
>> 6 POP_BLOCK
3 8 < 53 >
10 NOP
12 NOP
14 NOP
7 16 JUMP_ABSOLUTE 82
>> 18 LOAD_GLOBAL 5 ( __armor_enter__ )
20 CALL_FUNCTION 0
22 POP_TOP # we change this to RETURN_VALUE
9 24 NOP
26 NOP
28 NOP
30 SETUP_FINALLY 50 ( to 82 )由于Pyarmor在内存中编辑代码对象,即使我们退出代码对象,更改也将保留。
现在,我们可以调用(EXEC)代码对象。现在,我们可以访问解密的代码对象。现在剩下的就是将Pyarmor修改删除代码对象,即包装标头和页脚。
在此之后,我们必须从co_names中删除__armor_enter__和__armor_exit__ 。
我们为所有代码对象递归地重复此操作。
输出将是原始代码对象。就像Pyarmor从未使用过。
因此,我们可以使用我们所有喜欢的工具,例如Depompyle3获取原始源代码。
第三种方法用方法#2修复了最后一个问题。
在方法#2中,我们仍然必须实际运行该程序并注入程序。
这可能是一个问题,因为:
第三种方法试图静态地解开Pyarmor,我的意思是没有运行任何混淆程序的任何东西。
您可以通过几种方法进行静态解放它,但是我将解释的方法看起来最容易实现,而无需使用其他工具和/或语言。
我们将使用审核日志,出于安全原因,在Python中实现了审核日志。具有讽刺意味的是,我们将利用审核日志以删除安全性。
审核日志本质上是记录内部CPYTHON功能。包括exec和marshal.loads ,我们都可以用来获取主要混淆的代码对象,而无需注入/运行代码。可以在此处找到完整的审核日志列表
Cpython添加了一些简洁的称为审核钩,每次触发审核日志时,都会对我们安装的钩子进行回调。挂钩将只是一个函数,即2个参数, event , arg 。
审计钩子的示例:
import sys
def hook ( event , arg ):
print ( event , arg )
sys . addaudithook ( hook )将代码对象保存到磁盘的唯一方法是编组它。这意味着Pyarmor必须对编组的代码对象进行加密,因此自然而然的是,当他们想在Python中访问它时,他们必须解密它。
他们像大多数其他人一样使用内置的骑士。该软件包称为marshal ,它是用C编写的内置软件包。它是具有审核日志的软件包之一,因此,当Pyarmor称其为审计日志时,我们可以看到参数。
代码对象仍将加密字节码,但是我们已经设法超越了第一个“层”,我们基本上可以从此阶段重新使用我们的方法#2,因为它也必须处理加密的代码对象。现在唯一的区别是,每个代码对象都将被加密,而不是通常已经运行的代码对象,例如主代码对象。
因为在方法#2中,我们注入代码,我们已经可以访问所有Pyarmor函数,例如__armor_enter__和__armor_exit__ 。由于我们试图从静态上解开它,因此我们没有这种奢侈品。
正如我上面提到的Pyarmor具有限制模式,我已经显示了如何绕过Bootstrap限制模式,因为只有在运行pyarmor_runtime()函数时才会触发。
现在,我们需要运行整个混淆的文件,其中包括__pyarmor__呼叫。该功能触发了另一个限制模式,因此我们必须绕过它。首先,我认为我们通过本地对其进行修补来使用类似的方法。
一个朋友为此提供了帮助,这些是您可以重复的步骤。请记住,我发现一种更好,更轻松的方法。 pyarmor检查pyarmor字符串是否存在于__main__中的特定内存地址。我们需要修补此检查。请参阅下图
现在,我发现更好的方法是,Pyarmor的限制模式无法检查主文件是否由Python直接运行或是否被调用,因此我们可以简单地执行此操作:
exec ( open ( filename ))当然,我们安装了审核钩。
我遇到的问题是,审计挂钩在marshal.loads上触发,但是显然,在它触发之后,我需要自己加载代码对象,但这只是再次触发它,因此我添加了检查以查看dumps目录是否存在。这很危险,因为如果仍然有一个dumps夹从之前剩下的文件夹只会导致执行受保护的脚本而无需停止它。我们必须找到一种更好的方法来做到这一点。
编辑:我最近发现我忘记了需要编辑绝对跳跃的部分。这部分将涵盖这一点。
需要在方法#2和方法3中执行此操作。当我们删除页脚时,索引将不会碰撞。但是,当我们卸下标头时,它将导致索引按标头的大小移动,因此我们需要在所有绝对跳跃上循环并减去标头的大小。那部分很容易。
for i in range ( 0 , len ( raw_code ), 2 ):
opcode = raw_code [ i ]
if opcode == JUMP_ABSOLUTE :
argument = calculate_arg ( raw_code , i )
new_arg = argument - ( try_start + 2 )
extended_args , new_arg = calculate_extended_args ( new_arg )
for extended_arg in extended_args :
raw_code . insert ( i , EXTENDED_ARG )
raw_code . insert ( i + 1 , extended_arg )
i += 2
raw_code [ i + 1 ] = new_arg从方法#3
我们循环遍历字节码,并检查OpCode是否是JUMP_ABSOLUTE OpCode。如果是,我们将计算参数(请记住EXTENDED_ARG )。然后,我们将try_start是标头的大小(实际上是从标题中的最后一个opcode的索引,这就是为什么我们添加2)并从JUMP_ABSOLUTE opcode的参数中减去它。
实施此操作的最困难的部分是照顾当参数超过1字节的最大大小(255)时,我们可能必须添加的EXTENDED_ARG opcodes。我们在calculate_extended_args中处理。
def calculate_extended_args ( arg : int ): # This function will calculate the necessary extended_args needed
extended_args = []
new_arg = arg
if arg > 255 :
extended_arg = arg >> 8
while True :
if extended_arg > 255 :
extended_arg -= 255
extended_args . append ( 255 )
else :
extended_args . append ( extended_arg )
break
new_arg = arg % 256
return extended_args , new_arg从方法#3
要编写此代码,我首先必须了解EXTENDED_ARG工作方式。
本文有助于理解此操作码。
Python中的指令是最新版本(3.6+)中的2个字节。一个字节用于操作码,一个字节用于参数。当我们需要超过一个字节时,我们会使用EXTENDED_ARG 。它基本上是这样的:
arg = 300 # Let's say this is the size of our argument我们知道允许的最大值为255,因此我们需要使用Extended_arg,您会认为这是这样的:
extended_arg = 255
arg = 45这就是我首先假设的,但是在查看了Python生成的代码之后,我注意到是这样的:
extended_arg = 1
arg = 44我很困惑为什么这样会这样,因为我看到我的期望与现实之间没有相关性。上面链接的文章解释了一切。
Python像以下内容一样处理extended_arg:
extended_arg = extended_arg * 256看到这一点之后,一切都很清楚,因为这意味着
extended_arg = 1 * 256
arg = 44
print ( extended_arg + arg )将输出300 。
我将该逻辑应用到该函数上,以便它返回必要的Extended_arg opcodes和新参数值(将低于或等于255)的列表。
然后,我只需在正确的索引上插入Extended_Arg即可。


