arcmindvector
v1.0.0
ArcMind矢量数据库是Internet计算机的高性能,灵活和人体工程学的相似性搜索数据库。它被设计为通用矢量相似性搜索数据库,可用于广泛的AI驱动应用程序,包括推荐系统,搜索引擎,检索增强发电(RAG)以及对ArcMind AI等自主AI代理的长期记忆。
序列流程图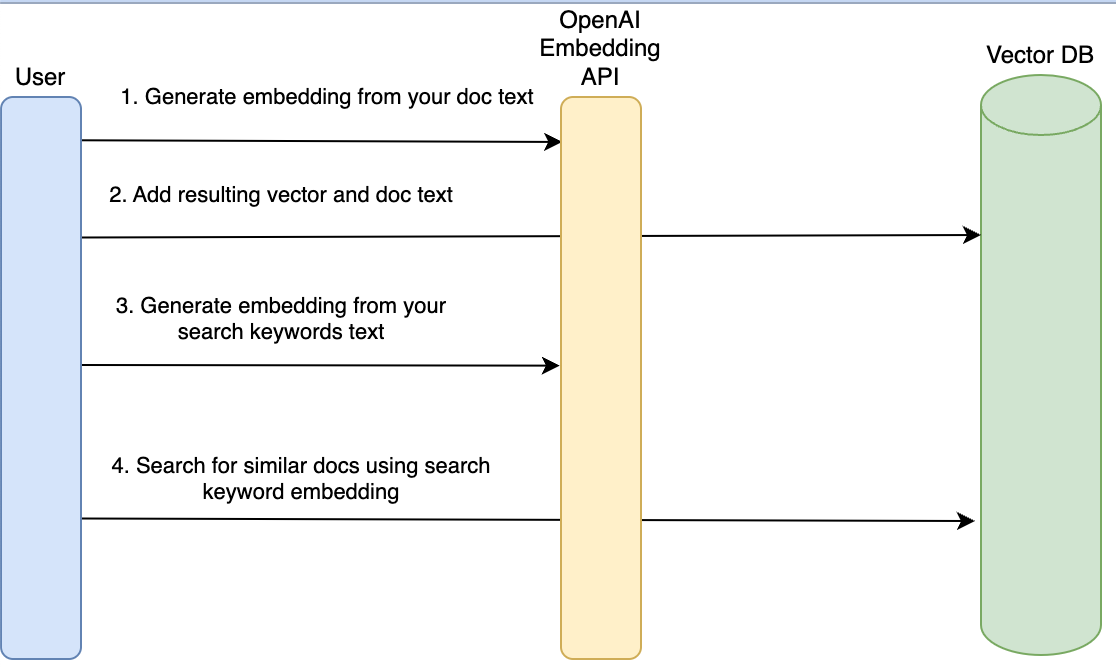
cargo install cargo-audit
如果要在本地测试项目,则可以使用以下命令:
# Starts the replica, running in the background
dfx start --background
# Deploys controller and brain canisters to the local replica
# Setup the environment variable: CONTROLLER_PRINCIPAL using using > dfx identity get-principal
./scripts/provision.sh配置脚本将部署arcmindvectordb罐。
请参阅坦率的完整API。
提供了样本外壳脚本以与交互目录中的罐头交互。嵌入式目录中提供了样品嵌入含量及其嵌入向量。
打开并编辑:
./interact/add_vector.sh尝试将多个主题的多个向量添加到矢量店。
然后,使用添加为输入的向量之一搜索类似的向量。它应该返回与同一主题的最相似向量和其他类似向量的相同矢量。看看它如何了解具有许多维度的向量的语义含义。
打开并编辑:
./interact/search_vector.sh请注意,必须将相同的嵌入模型用于添加和搜索向量。建议您在单个矢量店中使用相同的嵌入模型以进行一致的结果。
使用epenai text-embedding-ada-002型号与嵌入API生成 /嵌入 /嵌入 /嵌入 /
使用下面的命令获取字符串,然后将其放入github秘密中。注意:用所需的身份名称替换默认值。
awk 'NF {sub(/r/, ""); printf "%s\r\n",$0;}' ~/.config/dfx/identity/default/identity.pem
cat ~/.config/dfx/identity/default/wallets.json
有关许可权和限制(MIT),请参见许可证文件。
有关如何为该项目做出贡献的详细信息,请参见贡献。
代码与建筑:Henry Chan,[email protected],Twitter:@kinwo


