KoBERT
1.0.0
predefined_args = {
'attention_cell' : 'multi_head' ,
'num_layers' : 12 ,
'units' : 768 ,
'hidden_size' : 3072 ,
'max_length' : 512 ,
'num_heads' : 12 ,
'scaled' : True ,
'dropout' : 0.1 ,
'use_residual' : True ,
'embed_size' : 768 ,
'embed_dropout' : 0.1 ,
'token_type_vocab_size' : 2 ,
'word_embed' : None ,
}| 数据 | 句子 | 单词 |
|---|---|---|
| 韩国维基 | 5m | 54m |
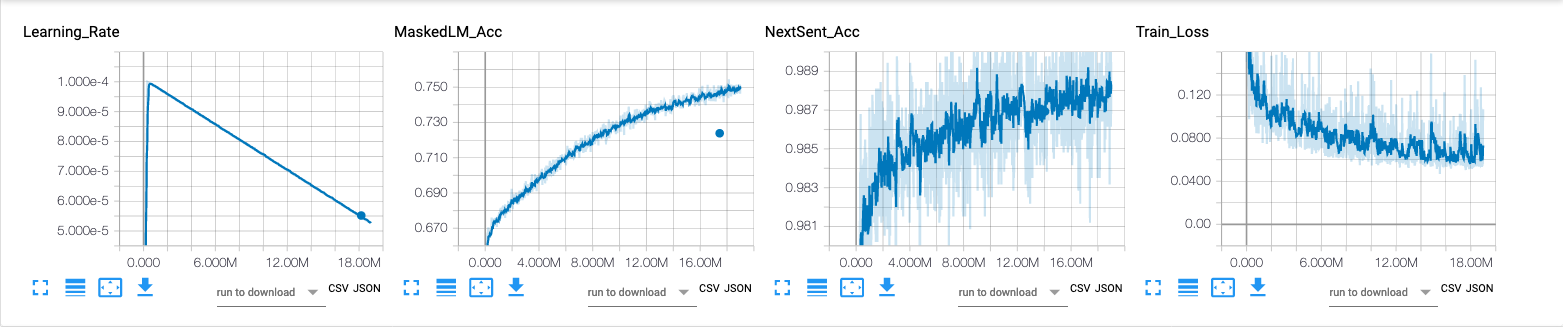
将Kobert作为Python包装
pip install git+https://[email protected]/SKTBrain/KoBERT.git@master如果要修改源代码,请克隆此存储库
git clone https://github.com/SKTBrain/KoBERT.git
cd KoBERT
pip install -r requirements.txt如果您对HuggingFace Transformers API感到满意,请参见此处。
> >> import torch
> >> from kobert import get_pytorch_kobert_model
> >> input_ids = torch . LongTensor ([[ 31 , 51 , 99 ], [ 15 , 5 , 0 ]])
> >> input_mask = torch . LongTensor ([[ 1 , 1 , 1 ], [ 1 , 1 , 0 ]])
> >> token_type_ids = torch . LongTensor ([[ 0 , 0 , 1 ], [ 0 , 1 , 0 ]])
> >> model , vocab = get_pytorch_kobert_model ()
> >> sequence_output , pooled_output = model ( input_ids , input_mask , token_type_ids )
> >> pooled_output . shape
torch . Size ([ 2 , 768 ])
> >> vocab
Vocab ( size = 8002 , unk = "[UNK]" , reserved = "['[MASK]', '[SEP]', '[CLS]']" )
> >> # Last Encoding Layer
>> > sequence_output [ 0 ]
tensor ([[ - 0.2461 , 0.2428 , 0.2590 , ..., - 0.4861 , - 0.0731 , 0.0756 ],
[ - 0.2478 , 0.2420 , 0.2552 , ..., - 0.4877 , - 0.0727 , 0.0754 ],
[ - 0.2472 , 0.2420 , 0.2561 , ..., - 0.4874 , - 0.0733 , 0.0765 ]],
grad_fn = < SelectBackward > ) model返回到默认情况下的eval()模式,因此在用于学习时必须通过model.train()命令更改为学习模式。
> >> import onnxruntime
> >> import numpy as np
> >> from kobert import get_onnx_kobert_model
> >> onnx_path = get_onnx_kobert_model ()
> >> sess = onnxruntime . InferenceSession ( onnx_path )
> >> input_ids = [[ 31 , 51 , 99 ], [ 15 , 5 , 0 ]]
> >> input_mask = [[ 1 , 1 , 1 ], [ 1 , 1 , 0 ]]
> >> token_type_ids = [[ 0 , 0 , 1 ], [ 0 , 1 , 0 ]]
> >> len_seq = len ( input_ids [ 0 ])
> >> pred_onnx = sess . run ( None , { 'input_ids' : np . array ( input_ids ),
>> > 'token_type_ids' : np . array ( token_type_ids ),
>> > 'input_mask' : np . array ( input_mask ),
>> > 'position_ids' : np . array ( range ( len_seq ))})
> >> # Last Encoding Layer
>> > pred_onnx [ - 2 ][ 0 ]
array ([[ - 0.24610452 , 0.24282141 , 0.25895312 , ..., - 0.48613444 ,
- 0.07305173 , 0.07560554 ],
[ - 0.24783179 , 0.24200465 , 0.25520486 , ..., - 0.4877185 ,
- 0.0727044 , 0.07536091 ],
[ - 0.24721591 , 0.24196623 , 0.2560626 , ..., - 0.48743123 ,
- 0.07326943 , 0.07650235 ]], dtype = float32 )ONNX转换有助于Soeque1。
> >> import mxnet as mx
> >> from kobert import get_mxnet_kobert_model
> >> input_id = mx . nd . array ([[ 31 , 51 , 99 ], [ 15 , 5 , 0 ]])
> >> input_mask = mx . nd . array ([[ 1 , 1 , 1 ], [ 1 , 1 , 0 ]])
> >> token_type_ids = mx . nd . array ([[ 0 , 0 , 1 ], [ 0 , 1 , 0 ]])
> >> model , vocab = get_mxnet_kobert_model ( use_decoder = False , use_classifier = False )
> >> encoder_layer , pooled_output = model ( input_id , token_type_ids )
> >> pooled_output . shape
( 2 , 768 )
> >> vocab
Vocab ( size = 8002 , unk = "[UNK]" , reserved = "['[MASK]', '[SEP]', '[CLS]']" )
> >> # Last Encoding Layer
>> > encoder_layer [ 0 ]
[[ - 0.24610372 0.24282135 0.2589539 ... - 0.48613444 - 0.07305248
0.07560539 ]
[ - 0.24783105 0.242005 0.25520545 ... - 0.48771808 - 0.07270523
0.07536077 ]
[ - 0.24721491 0.241966 0.25606337 ... - 0.48743105 - 0.07327032
0.07650219 ]]
< NDArray 3 x768 @ cpu ( 0 ) > > >> from gluonnlp . data import SentencepieceTokenizer
> >> from kobert import get_tokenizer
> >> tok_path = get_tokenizer ()
> >> sp = SentencepieceTokenizer ( tok_path )
> >> sp ( '한국어 모델을 공유합니다.' )
[ '▁한국' , '어' , '▁모델' , '을' , '▁공유' , '합니다' , '.' ]| 模型 | 准确性 |
|---|---|
| Bert Base多语言案例 | 0.875 |
| 科伯特 | 0.901 |
| 科格普22 | 0.899 |
문장을 입력하세요: SKTBrain에서 KoBERT 모델을 공개해준 덕분에 BERT-CRF 기반 객체명인식기를 쉽게 개발할 수 있었다.
len: 40, input_token:['[CLS]', '▁SK', 'T', 'B', 'ra', 'in', '에서', '▁K', 'o', 'B', 'ER', 'T', '▁모델', '을', '▁공개', '해', '준', '▁덕분에', '▁B', 'ER', 'T', '-', 'C', 'R', 'F', '▁기반', '▁', '객', '체', '명', '인', '식', '기를', '▁쉽게', '▁개발', '할', '▁수', '▁있었다', '.', '[SEP]']
len: 40, pred_ner_tag:['[CLS]', 'B-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'O', 'B-POH', 'I-POH', 'I-POH', 'I-POH', 'I-POH', 'O', 'O', 'O', 'O', 'O', 'O', 'B-POH', 'I-POH', 'I-POH', 'I-POH', 'I-POH', 'I-POH', 'I-POH', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', '[SEP]']
decoding_ner_sentence: [CLS] <SKTBrain:ORG>에서 <KoBERT:POH> 모델을 공개해준 덕분에 <BERT-CRF:POH> 기반 객체명인식기를 쉽게 개발할 수 있었다.[SEP]
| 模型 | 余弦皮尔逊 | 余弦斯皮尔曼 | 欧两者的皮尔森 | Eucliding Spearman | 曼哈顿皮尔逊 | 曼哈顿斯皮尔曼 | Dot Pearson | Dot Spearman |
|---|---|---|---|---|---|---|---|---|
| nll | 65.05 | 68.48 | 68.81 | 68.18 | 68.90 | 68.20 | 65.22 | 66.81 |
| sts | 80.42 | 79.64 | 77.93 | 77.43 | 77.92 | 77.44 | 76.56 | 75.83 |
| STS + NLI | 78.81 | 78.47 | 77.68 | 77.78 | 77.71 | 77.83 | 75.75 | 75.22 |
onnx 1.8.0No module named 'kobert.utils'aws s3下载大文件请在此处注册与KoBERT相关的问题。
KoBERT以Apache-2.0许可发布。如果您使用的是模型和代码,请遵循许可内容。许可专家可以在LICENSE文件中找到。


