Recurrent LLM
1.0.0
纸的开源LLM实施:
recurrentgpt:(任意)长文本的交互式生成。
[纸] [arxiv] [huggingface] [ofstical]
变压器的固定尺寸上下文使GPT模型无法生成任意长的文本。在本文中,我们引入了RecurrentGpt,这是RNN中复发机制的基于语言的模拟。 recurrentgpt建立在大型语言模型(LLM)(例如Chatgpt)上,并使用自然语言模拟LSTM中的长期短期记忆机制。在每个时间段上,RecurrentGpt生成文本段落,并分别更新其基于语言的长期记忆内存储在硬盘驱动器和提示上的长期记忆。这种复发机制使得可以复发能够生成任意长度的文本而不会忘记。由于人类用户可以轻松地观察和编辑自然语言记忆,因此可以解释recurrentgpt,并可以互动长期产生。 RecurrentGPT是迈出下一代计算机辅助写作系统的第一步,而不是本地编辑建议。除了产生AI生成的内容(AIGC)外,我们还证明了将RecurrentGpt用作直接与消费者互动的互动小说的可能性。我们称``AI''(AIAC)的生成模型使用,我们认为这是常规AIGC的下一种形式。我们进一步证明了使用Recurrentgpt创建个性化互动小说的可能性,该小说直接与读者互动,而不是与作家互动。从更广泛的角度来看,Recurrentgpt展示了从认知科学中流行的模型设计和促使LLM的深度学习中借用思想的实用性。
变压器的固定尺寸上下文使得gpt模型无法生成任意长的文本。在本文中,我们介绍了recurrentgpt,一个基于语言的模拟rnns中的递归机制。recurrentgpt 建立在大型语言模型( llm),之上,如chatgpt,并使用自然语言来模拟lstm中的长短时记忆机制。在每个时间段,recurrentGpt生成一段文字,生成一段文字,并更新其基于语言的长短时记忆,并更新其基于语言的长短时记忆制使recurrentgpt能够生成任意长度的文本而不被遗忘。由于人类用户可以很容易地观察和编辑自然语言记忆,因此recurrentGpt是可解释的,并能互动地生成长文本。术(Aigc),aigrentgpt 是朝着超越本地编辑建议的下一代计算机辅助写作系统迈出的第一步。除了制作人工智能生成的内容( aigrentgpt 是朝着超越本地编辑建议的下一代计算机辅助写作系统迈出的第一步。除了制作人工智能生成的内容(),我们还展示了使用recurrentgpt作为直接与消费者互动的互动小说的可能性。我们称这种生成模型的使用为“ AI作为内容”(aiac),我们认为这是传统aigc的下一个形式。我们进一步展示了使用cretrentgpt创造个性化互动小说的可能性,这种小说直接与读者互动,而不是与作者互动。更广泛地说
pip install transformers@git+https://github.com/huggingface/transformers.git
pip install peft@git+https://github.com/huggingface/peft.git
pip install accelerate@git+https://github.com/huggingface/accelerate.git
pip install bitsandbytes==0.39.0
pip install -U flagai
pip install bminf
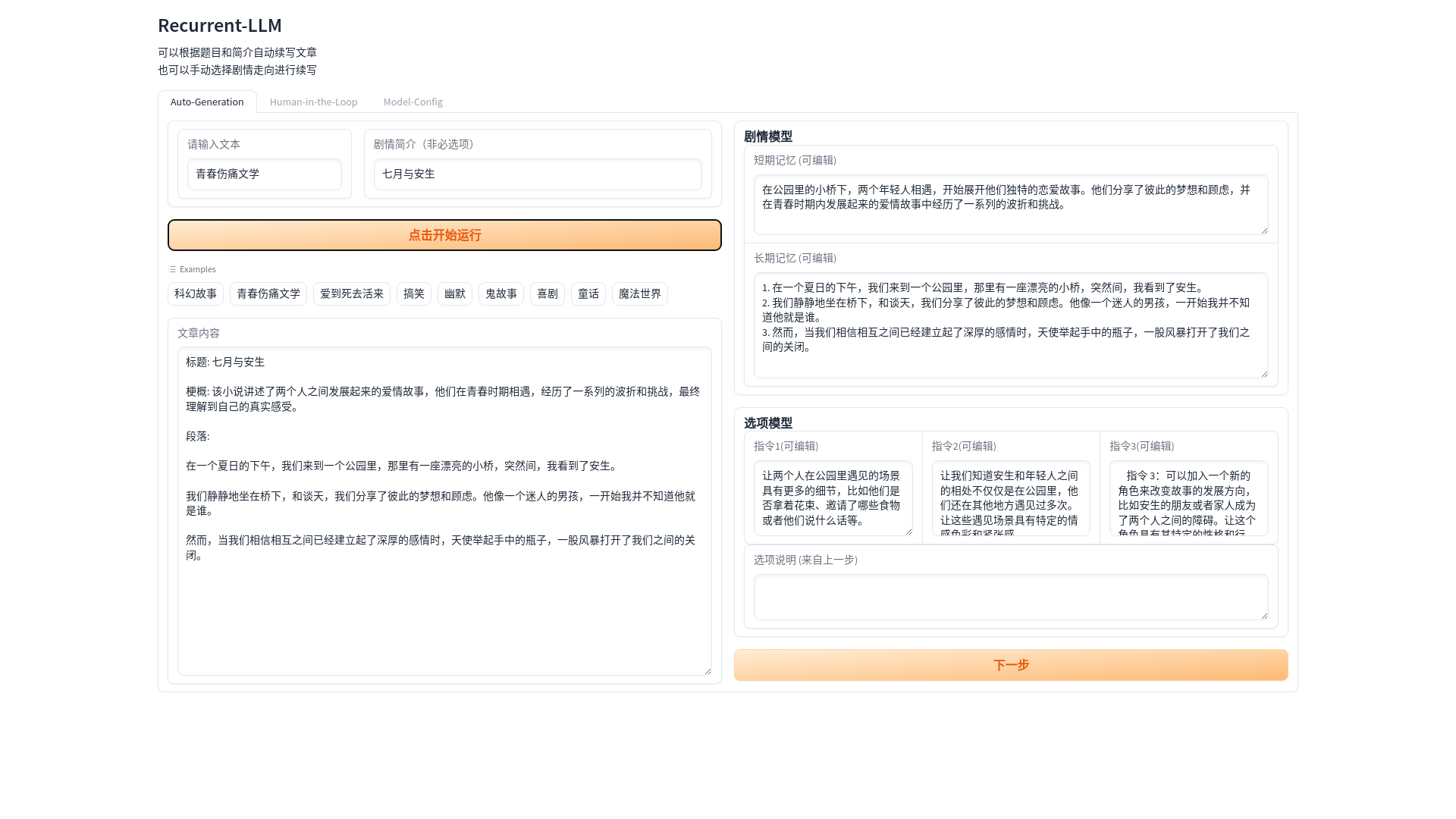
[global_config.py]
lang_opt = "zh" # zh or en. make English or Chinese Novel
llm_model_opt = "openai" # default is openai, it also can be other open-source LLMs as below
您应该先应用OpenAI API密钥。然后
export OPENAI_API_KEY = "your key"
下载Vicuna型号。并在型号/vicuna_bin.py中进行配置
tokenizer = AutoTokenizer . from_pretrained ( model_name_or_path , trust_remote_code = True )
model_config = AutoConfig . from_pretrained ( model_name_or_path , trust_remote_code = True )
model = AutoModel . from_pretrained ( model_name_or_path , config = model_config , trust_remote_code = True ) tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/baichuan-7B" , trust_remote_code = True )
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/baichuan-7B" , device_map = "auto" , trust_remote_code = True ) loader = AutoLoader (
"lm" ,
model_dir = state_dict ,
model_name = model_name ,
use_cache = True ,
fp16 = True )
model = loader . get_model ()
tokenizer = loader . get_tokenizer ()
model . eval ()如果要使用BMINF,请添加代码如下:
with torch . cuda . device ( 0 ):
model = bminf . wrapper ( model , quantization = False , memory_limit = 2 << 30 ) python gradio_server.py
如果该项目可以帮助您减少开发时间,您可以给我一杯咖啡:)
支付宝(支付宝)

微弱(微信)

麻省理工学院©Kun


