Improving the efficiency of large language models has always been a research hotspot in the field of artificial intelligence. Recently, research teams from Aleph Alpha, Technical University of Darmstadt and other institutions have developed a new method called T-FREE, which significantly improves the operating efficiency of large language models. This method reduces the number of embedding layer parameters by using character triples for sparse activation, and effectively models the morphological similarity between words. It greatly reduces the consumption of computing resources while ensuring model performance. This breakthrough technology brings new possibilities for the application of large language models.
The research team recently introduced an exciting new method called T-FREE, which allows the operating efficiency of large language models to skyrocket. Scientists from Aleph Alpha, TU Darmstadt, hessian.AI and the German Research Center for Artificial Intelligence (DFKI) have jointly launched this amazing technology, whose full name is "Tagger-free Sparse Representation, Memory-efficient embedding is possible.”
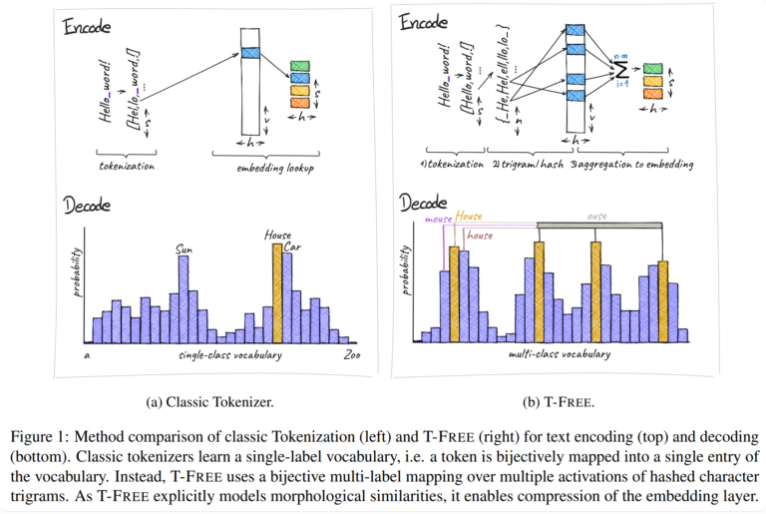
Traditionally, we use tokenizers to convert text into a numerical form that computers can understand, but T-FREE has chosen a different path. It uses character triples, what we call "triples", to embed words directly into the model through sparse activation. As a result of this innovative move, the number of parameters in the embedding layer was reduced by an astonishing 85% or more, while the performance of the model was not affected at all when handling tasks such as text classification and question answering.
Another highlight of T-FREE is that it very cleverly models morphological similarities between words. Just like the words "house", "houses" and "domestic" that we often encounter in daily life, T-FREE can more effectively represent these similar words in the model. The researchers believe that similar words should be embedded closer to each other to achieve higher compression rates. Therefore, T-FREE not only reduces the size of the embedding layer, but also reduces the average encoding length of text by 56%.
What’s more worth mentioning is that T-FREE performs particularly well in transfer learning between different languages. In one experiment, the researchers used a model with 3 billion parameters, trained first in English and then in German, and found that T-FREE was far more adaptable than traditional tagger-based methods.
However, the researchers remain modest about their current results. They admit that experiments so far have been limited to models with up to 3 billion parameters, and further evaluations on larger models and larger data sets are planned in the future.
The emergence of the T-FREE method provides new ideas for improving the efficiency of large language models. Its advantages in reducing computational costs and improving model performance are worthy of attention. Future research directions will focus on the verification of larger-scale models and data sets to further expand the application scope of T-FREE and promote the continued development of large-scale language model technology. It is believed that T-FREE will play an important role in more fields in the near future.