In recent years, the Transformer model and its attention mechanism have made significant progress in the field of large language models (LLM), but the problem of being susceptible to interference from irrelevant information has always existed. The editor of Downcodes will interpret a latest paper for you, which proposes a new model called Differential Transformer (DIFF Transformer), which aims to solve the attention noise problem in the Transformer model and improve model efficiency and accuracy. The model effectively filters out irrelevant information through an innovative differential attention mechanism, allowing the model to focus more on key information, thereby achieving significant improvements in multiple aspects, including language modeling, long text processing, key information retrieval, and Reduce model illusion, etc.
Large language models (LLM) have developed rapidly recently, in which the Transformer model plays an important role. The core of Transformer is the attention mechanism, which acts like an information filter and allows the model to focus on the most important parts of the sentence. But even a powerful Transformer will be interfered by irrelevant information, just like you are trying to find a book in the library, but you are overwhelmed by a pile of irrelevant books, and the efficiency is naturally low.
The irrelevant information generated by this attention mechanism is called attention noise in the paper. Imagine that you want to find a key piece of information in a file, but the Transformer model's attention is scattered to various irrelevant places, just like a short-sighted person who cannot see the key points.
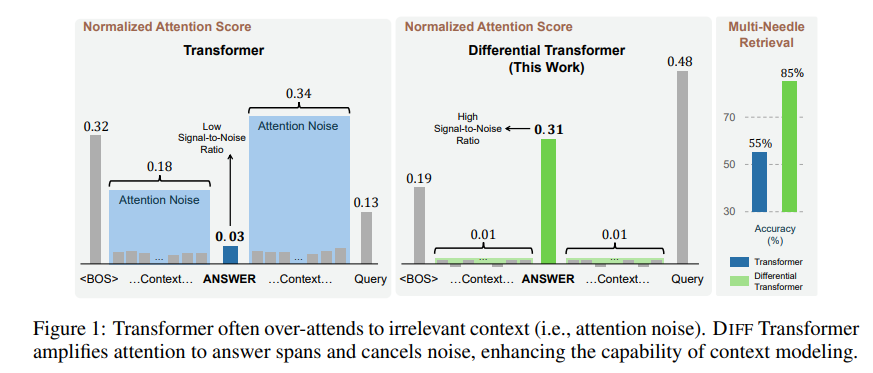
To solve this problem, this paper proposes Differential Transformer (DIFF Transformer). The name is very advanced, but the principle is actually very simple. Just like noise-cancelling headphones, noise is eliminated through the difference between two signals.
The core of Differential Transformer is the differential attention mechanism. It divides the query and key vectors into two groups, calculates two attention maps respectively, and then subtracts these two maps to get the final attention score. This process is like shooting the same object with two cameras, and then superimposing the two photos, and the differences will be highlighted.
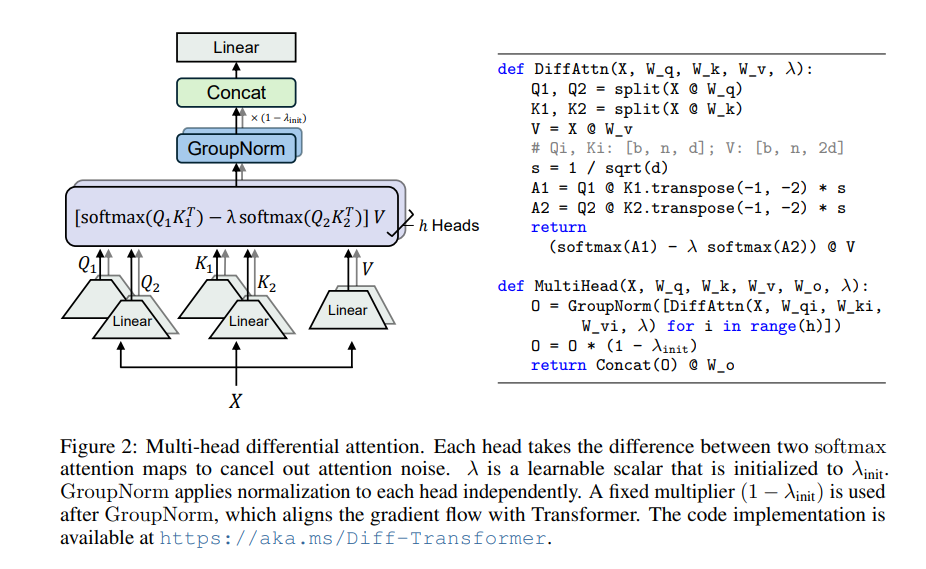
In this way, Differential Transformer can effectively eliminate attention noise and allow the model to focus more on key information. Just like when you put on noise-canceling headphones, the surrounding noise disappears and you can hear the sound you want more clearly.
A series of experiments were conducted in the paper to prove the superiority of Differential Transformer. First, it performs well in language modeling, requiring only 65% of the model size or training data of Transformer to achieve similar results.
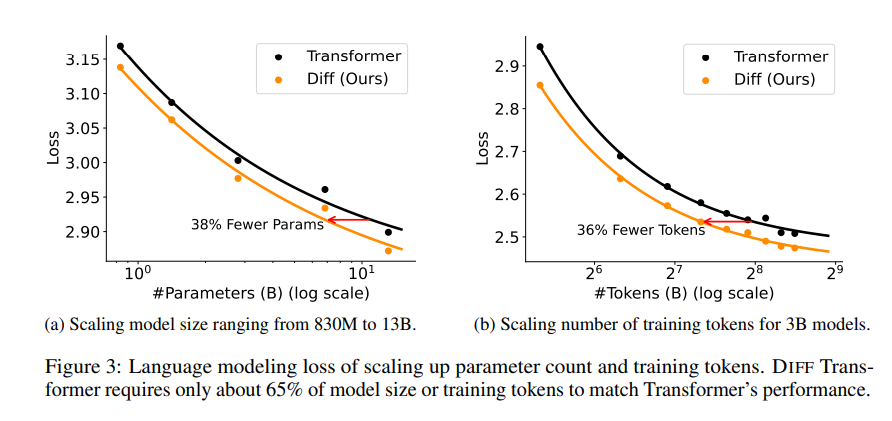
Secondly, Differential Transformer is also better at long text modeling and can effectively utilize longer contextual information.
More importantly, Differential Transformer shows significant advantages in key information retrieval, model illusion reduction, and context learning.
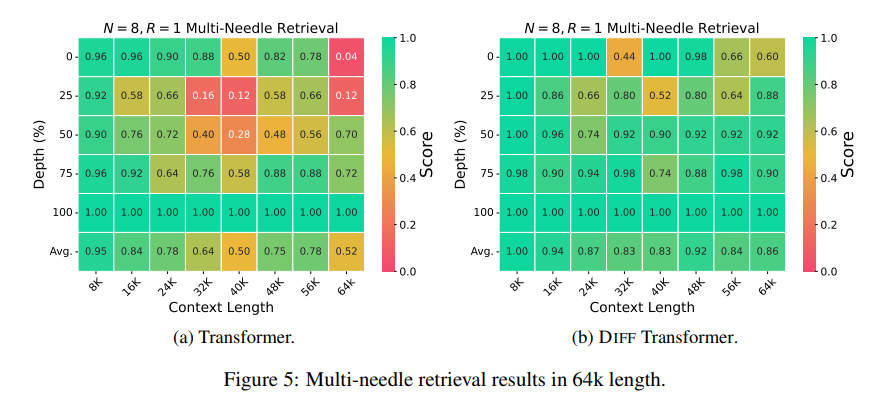
In terms of key information retrieval, Differential Transformer is like a precise search engine that can accurately find what you want in massive amounts of information. It can maintain high accuracy even in scenarios with extremely complex information.
In terms of reducing model hallucinations, Differential Transformer can effectively avoid model "nonsense" and generate more accurate and reliable text summarization and question and answer results.
In terms of context learning, Differential Transformer is more like a master of learning, able to quickly learn new knowledge from a small number of samples, and the learning effect is more stable, unlike Transformer, which is not easily affected by the order of samples.
In addition, Differential Transformer can also effectively reduce outliers in model activation values, which means that it is more friendly to model quantization and can achieve lower-bit quantization, thereby improving the efficiency of the model.
All in all, Differential Transformer effectively solves the attention noise problem of the Transformer model through the differential attention mechanism and achieves significant improvements in multiple aspects. It provides new ideas for the development of large language models and will play an important role in more fields in the future.
Paper address: https://arxiv.org/pdf/2410.05258
All in all, Differential Transformer provides an effective method to solve the attention noise problem of Transformer model. Its excellent performance in multiple fields indicates its important position in the development of large language models in the future. The editor of Downcodes recommends readers to read the complete paper to gain an in-depth understanding of its technical details and application prospects. We look forward to Differential Transformer bringing more breakthroughs in the field of artificial intelligence!