ไลบรารีเครื่องมือค้นหาแบบเต็มข้อความที่เขียนด้วย Rust
หากคุณกำลังมองหาทางเลือกสำหรับ Elasticsearch หรือ Apache Solr ลองดู Quickwit เครื่องมือค้นหาแบบกระจายของเราที่สร้างขึ้นบน Tantivy
Tantivy อยู่ใกล้กับ Apache Lucene มากกว่า Elasticsearch หรือ Apache Solr ในแง่ที่ว่ามันไม่ใช่เซิร์ฟเวอร์เครื่องมือค้นหานอกชั้นวาง แต่เป็นลังที่สามารถใช้ในการสร้างเครื่องมือค้นหาดังกล่าว
ในความเป็นจริง Tantivy ได้รับแรงบันดาลใจอย่างมากจากการออกแบบของ Lucene
เกณฑ์มาตรฐาน
เกณฑ์มาตรฐานต่อไปนี้แบ่งประสิทธิภาพสำหรับการสืบค้น/คอลเลกชันประเภทต่าง ๆ
ไมล์สะสมของคุณจะแตกต่างกันไปขึ้นอยู่กับลักษณะของการสืบค้นและภาระของพวกเขา
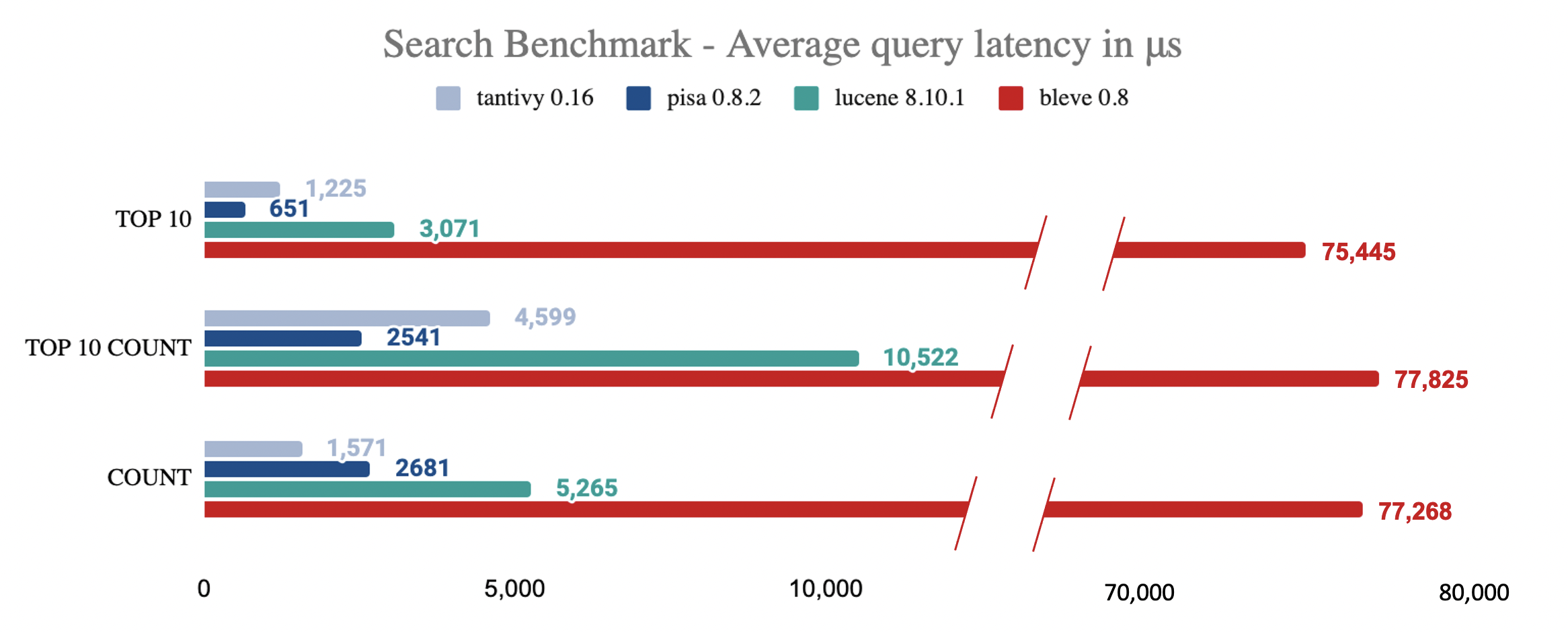
รายละเอียดเกี่ยวกับเกณฑ์มาตรฐานสามารถดูได้ที่ที่เก็บนี้
คุณสมบัติ
- การค้นหาข้อความแบบเต็ม
- Tokenizer ที่กำหนดค่าได้ (มีให้บริการสำหรับภาษาละติน 17 ภาษา) ด้วยการสนับสนุนบุคคลที่สามสำหรับจีน (Tantivy-Jieba และ Cang-Jie), ญี่ปุ่น (Lindera, Vaporetto และ Tantivy-Tokenizer-tiny-segmenter) และเกาหลี (Lindera + Lindera-ko-dic-builder)
- เร็ว (ตรวจสอบเกณฑ์มาตรฐาน?)
- เวลาเริ่มต้นเล็ก ๆ (<10ms) เหมาะสำหรับเครื่องมือบรรทัดคำสั่ง
- การให้คะแนน BM25 (เหมือนกับ Lucene)
- ภาษาคิวรีธรรมชาติ (เช่น
(michael AND jackson) OR "king of pop" ) - การค้นหาวลีแบบสอบถาม (เช่น
"michael jackson" ) - การทำดัชนีที่เพิ่มขึ้น
- การทำดัชนีแบบมัลติเธรด (การจัดทำดัชนีภาษาอังกฤษวิกิพีเดียใช้เวลา <3 นาทีบนเดสก์ท็อปของฉัน)
- ไดเรกทอรี MMAP
- การบีบอัดจำนวนเต็ม SIMD เมื่อแพลตฟอร์ม/CPU มีชุดคำสั่ง SSE2
- U64, I64, และ F64 FAST FIELDS Single Valued ที่มีมูลค่า
-
&[u8] ฟิลด์เร็ว - ข้อความ, i64, U64, F64, วันที่, IP, บูลและฟิลด์ด้านลำดับชั้น
- ร้านเอกสารบีบอัด (LZ4, ZSTD, NONE)
- แบบสอบถามช่วง
- การค้นหาแบบ faceted
- การจัดทำดัชนีที่กำหนดค่าได้ (ความถี่คำที่เป็นตัวเลือกและการจัดทำดัชนีตำแหน่ง)
- สนาม JSON
- การรวมตัวสะสม: ฮิสโตแกรม, ช่วงถัง, ค่าเฉลี่ยและตัวชี้วัดสถิติ
- logmergepolicy พร้อมลบ
- ผู้ค้นหาอุ่น API
- โลโก้วิเศษกับม้า
ที่ไม่ได้มีคุณสมบัติ
การค้นหาแบบกระจายอยู่นอกขอบเขตของ Tantivy แต่ถ้าคุณกำลังมองหาคุณสมบัตินี้ให้ตรวจสอบ QuickWit
เริ่มต้น
Tantivy ทำงานบนสนิมที่มั่นคงและรองรับ Linux, MacOS และ Windows
- ตัวอย่างการค้นหาง่าย ๆ ของ Tantivy
- Tantivy-cli และการสอน
tantivy-cli เป็นอินเทอร์เฟซบรรทัดคำสั่งจริงที่ทำให้คุณสร้างเครื่องมือค้นหาเอกสารดัชนีและค้นหาผ่าน CLI หรือเซิร์ฟเวอร์ขนาดเล็กที่มี REST API มันนำคุณผ่านการรับเครื่องมือค้นหา Wikipedia และทำงานในไม่กี่นาที - เอกสารอ้างอิงสำหรับเวอร์ชันล่าสุดที่ปล่อยออกมา
ฉันจะสนับสนุนโครงการนี้ได้อย่างไร
มีหลายวิธีในการสนับสนุนโครงการนี้
- ใช้ tantivy และบอกเราเกี่ยวกับประสบการณ์ของคุณเกี่ยวกับ Discord หรือทางอีเมล ([email protected])
- รายงานข้อบกพร่อง
- เขียนโพสต์บล็อก
- ความช่วยเหลือเกี่ยวกับเอกสารโดยถามคำถามหรือส่ง PRS
- มีส่วนร่วมรหัส (คุณสามารถเข้าร่วมเซิร์ฟเวอร์ Discord ของเราได้)
- พูดคุยเกี่ยวกับ tantivy รอบตัวคุณ
รหัสที่มีส่วนร่วม
เราใช้เวิร์กโฟลว์คำขอดึง GitHub: อ้างอิงตั๋ว GitHub และ/หรือรวมถึงข้อความการกระทำที่ครอบคลุมเมื่อเปิดการประชาสัมพันธ์ อย่าลังเลที่จะอัปเดต changelog.md ด้วยการบริจาคของคุณ
โทเค็น
เมื่อใช้ tokenizer สำหรับ tantivy ขึ้นอยู่กับลัง tantivy-tokenizer-api
โคลนและสร้างในพื้นที่
Tantivy รวบรวมการเกิดสนิมที่มั่นคง ในการตรวจสอบและเรียกใช้การทดสอบคุณสามารถเรียกใช้:
git clone https://github.com/quickwit-oss/tantivy.git
cd tantivy
cargo test
บริษัท ที่ใช้ Tantivy








คำถามที่พบบ่อย
ฉันสามารถใช้ tantivy ในภาษาอื่น ๆ ได้หรือไม่?
- Python → tantivy-py
- ทับทิม→ tantiny
นอกจากนี้คุณยังสามารถหาผลผูกพันอื่น ๆ ใน GitHub ได้ แต่อาจได้รับการดูแลน้อยลง
มีตัวอย่างของการใช้ tantivy อะไรบ้าง?
- SESHAT: ฐานข้อมูลข้อความเมทริกซ์/ดัชนี
- tantiny: การค้นหาข้อความแบบเต็มขนาดเล็กสำหรับทับทิม
- LNX: เครื่องมือค้นหาที่ปรับตัวพิมพ์ผิดได้ด้วย REST API
- และอีกมากมาย
โดยเฉลี่ยแล้ว tantivy เร็วแค่ไหนเมื่อเทียบกับ Lucene?
- ตามมาตรฐานการค้นหาเวลาแฝงของเรา Tantivy นั้นเร็วกว่า Lucene ประมาณ 2 เท่า
Tantivy สนับสนุนการทำดัชนีที่เพิ่มขึ้นหรือไม่?
ฉันจะแก้ไขเอกสารได้อย่างไร?
- ข้อมูลใน tantivy ไม่เปลี่ยนรูป ในการแก้ไขเอกสารเอกสารจะต้องถูกลบและจัดทำดัชนีใหม่
เอกสารของฉันจะค้นหาได้เมื่อใดในระหว่างการจัดทำดัชนี?
- เอกสารจะสามารถค้นหาได้หลังจาก
commit ที่เรียกใช้กับ IndexWriter IndexReader ที่มีอยู่จะต้องโหลดซ้ำเพื่อสะท้อนการเปลี่ยนแปลง ในที่สุดการเปลี่ยนแปลงจะปรากฏเฉพาะ Searcher ที่ได้มาใหม่เท่านั้น


