Чатбот с PDF для семантического поиска над документами (построить с помощью когнитивного поиска в Streamlit, Langchain, Pinecone/Chroma/Azure)
Этот репозиторий содержит пример кода для создания интерактивного чата для семантического поиска над документами. Чатбот позволяет пользователям задавать вопросы о естественном языке и получать соответствующие ответы из коллекции документов. Чатбот использует streamlit для интерфейса веб -и чат -бота, Langchain и использует различные типы векторных баз данных, такие как Pinecone, Chroma и Vector Search Cognative Search, для выполнения эффективного и точного поиска сходства. Код записан в Python и может быть легко изменен в соответствии с различными вариантами использования и источниками данных.
Пожалуйста, также ознакомьтесь с моей историей в Medium (базы данных Streamlit и Vector: Руководство по созданию интерактивных веб -приложений для семантического поиска документов) для получения более подробной информации об обмене.
- preprocess_pinecone.ipynb <- Пример использования модели встраивания из Azure Openai для встраивания контента из документа и сохранения ее в базу данных вектора Pinecone.
- preprocess_chroma.ipynb <- Пример использования модели встраивания из службы Azure Openai для встраивания контента из документа и сохранения ее в базу данных вектора Chroma.
- preprocess_acs.ipynb <- Пример использования модели встраивания из службы Azure Openai для встраивания контента из документа и сохранения ее в базу данных векторов когнитивного поиска.
- unsume_pinecone.ipynb <-Пример использования модуля с ответом на вопрос Langchain для выполнения поиска сходства из базы данных Vector Vector и использовать GPT-3.5 (Text-Davinci-003), чтобы суммировать результат.
- unsume_chroma.ipynb <-Пример использования модуля для вопросов Langchain для выполнения поиска сходства из базы данных Vector Chroma и использовать GPT-3.5 (Text-Davinci-003) для обобщения результата.
- unsume_acs.ipynb <-Пример использования модуля с ответом на вопрос Langchain для выполнения поиска сходства из базы данных вектора когнитивного поиска Azure и использовать GPT-3.5 (Text-Davinci-003), чтобы суммировать результат.
- APP_PINECONE.PY <- Пример использования базы данных StreamLit, Langchain и Vection Vector для создания интерактивного чата для облегчения семантического поиска над документами. Он использует модель GPT-3.5-Turbo от Azure Openai Service для суммирования результатов и чата.
- APP_CHROMA.PY <- Пример использования базы данных Streamlit, Langchain и Croma Vector для создания интерактивного чата для облегчения семантического поиска по документам. Он использует модель GPT-3.5-Turbo от Azure Openai Service для суммирования результатов и чата.
- APP_ACS.PY <- Пример использования базы данных вектора когнитивного поиска Streamlit, Langchain и Azure Cognative Search для создания интерактивного чата для облегчения семантического поиска над документами. Он использует модель GPT-3.5-Turbo от Azure Openai Service для суммирования результатов и чата.
Чтобы запустить это веб -приложение Streamlit
streamlit run app_pinecone.py
Архитектура и поток этого семантического поиска по поводу демонстрации документов 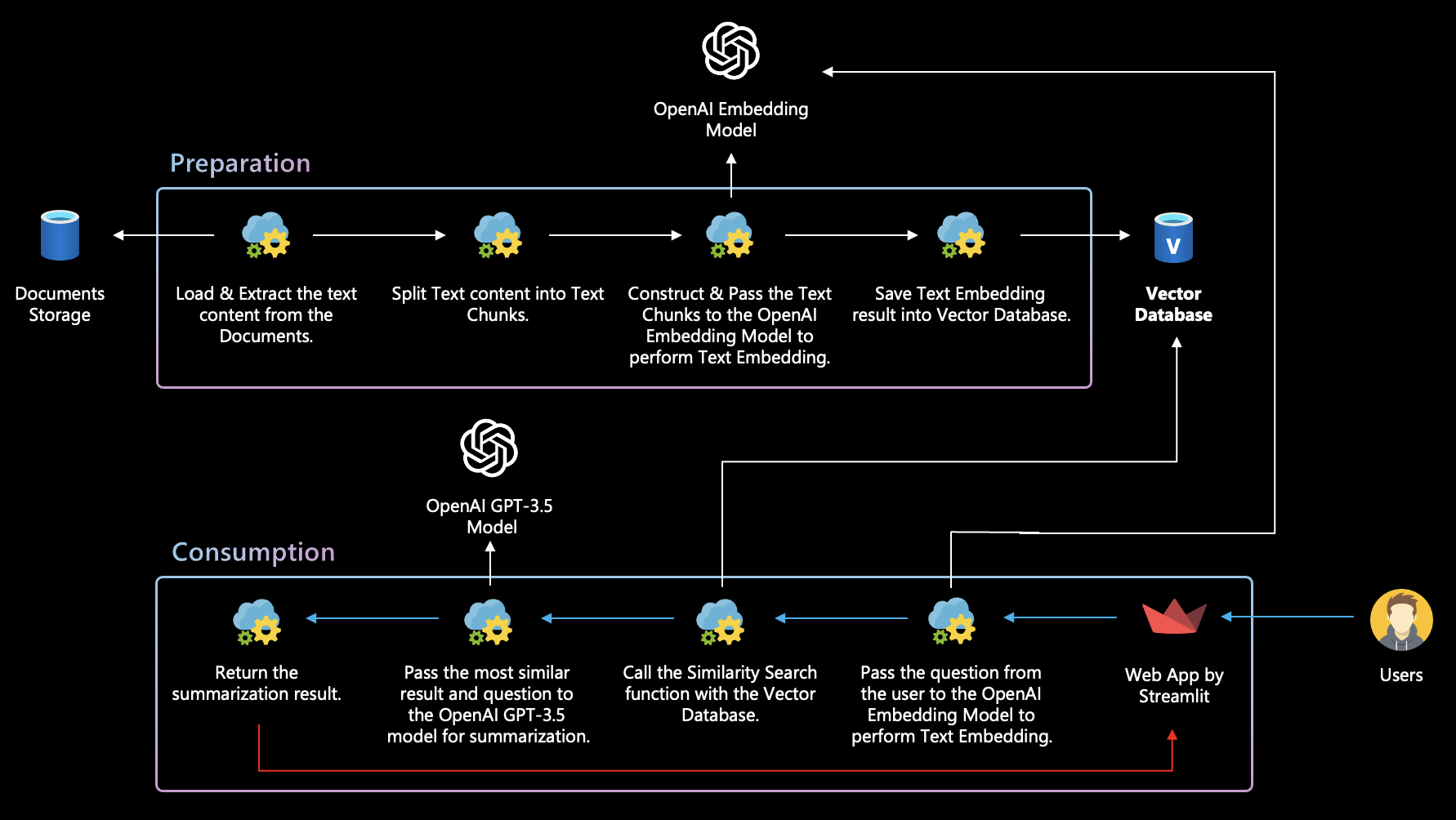
Наслаждаться!


