Extendible Hashing for DBMS
1.0.0
Низкоуровневая реализация расширяемого хеширования для систем баз данных.
Этот метод использует каталоги и сегменты для хэширования данных и широко известен своей гибкостью и эффективностью вычислений.
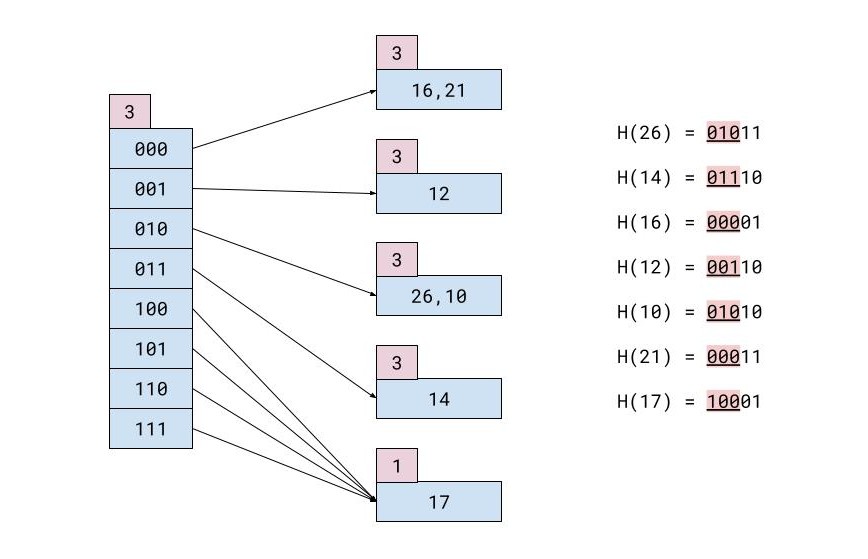
Например, у вас есть такая таблица записей:
| ИДЕНТИФИКАТОР | ИМЯ | ФАМИЛИЯ | ГОРОД |
|---|---|---|---|
| 26 | Мария | Коронис | Гонконг |
| 14 | Христофорос | Гайтанис | Токио |
| 16 | Марианна | Карвунари | Майами |
| 12 | Теофилос | Николопулос | Лондон |
| 10 | Иосиф | Свингос | Токио |
| 21 | Теофилос | Михас | Афины |
| 17 | Гиоргос | Халацис | Мюнхен |
Если в каждом блоке памяти может быть только 2 записи, хэш-файл после всех вставок будет выглядеть так:
Программа может запускаться двумя разными основными функциями. Первый вставляет большое количество записей в файл, а второй создает и вставляет записи в три разных файла одновременно.
test_main1:
make main1
./build/runner
test_main2:
make main2
./build/runner