retail pricing search personaliztion
1.0.0
Em um ambiente de varejo, colocar o cliente primeiro se torna a chave para o sucesso qualquer ônibus comércio eletrônico. Portanto, toda e qualquer interação do cliente em um aplicativo da Web pode informar sobre as pré -frcelas e interesses do cliente. A modelagem em torno dos clientes Informações ajuda a desbloquear o valor a ajudar as decisões de compra e ali movendo o KPI do Bussiness. Neste repositório, demonstramos os recursos para armazenar a interação em tempo real do cliente no aplicativo da web para modelar os seguintes Behviours:
Esses recursos modelados são usados para alimentar as funcionalidades de classificação e classificação na frente Discoverabiltiy desses produtos.
http: // go/varejo-Demo
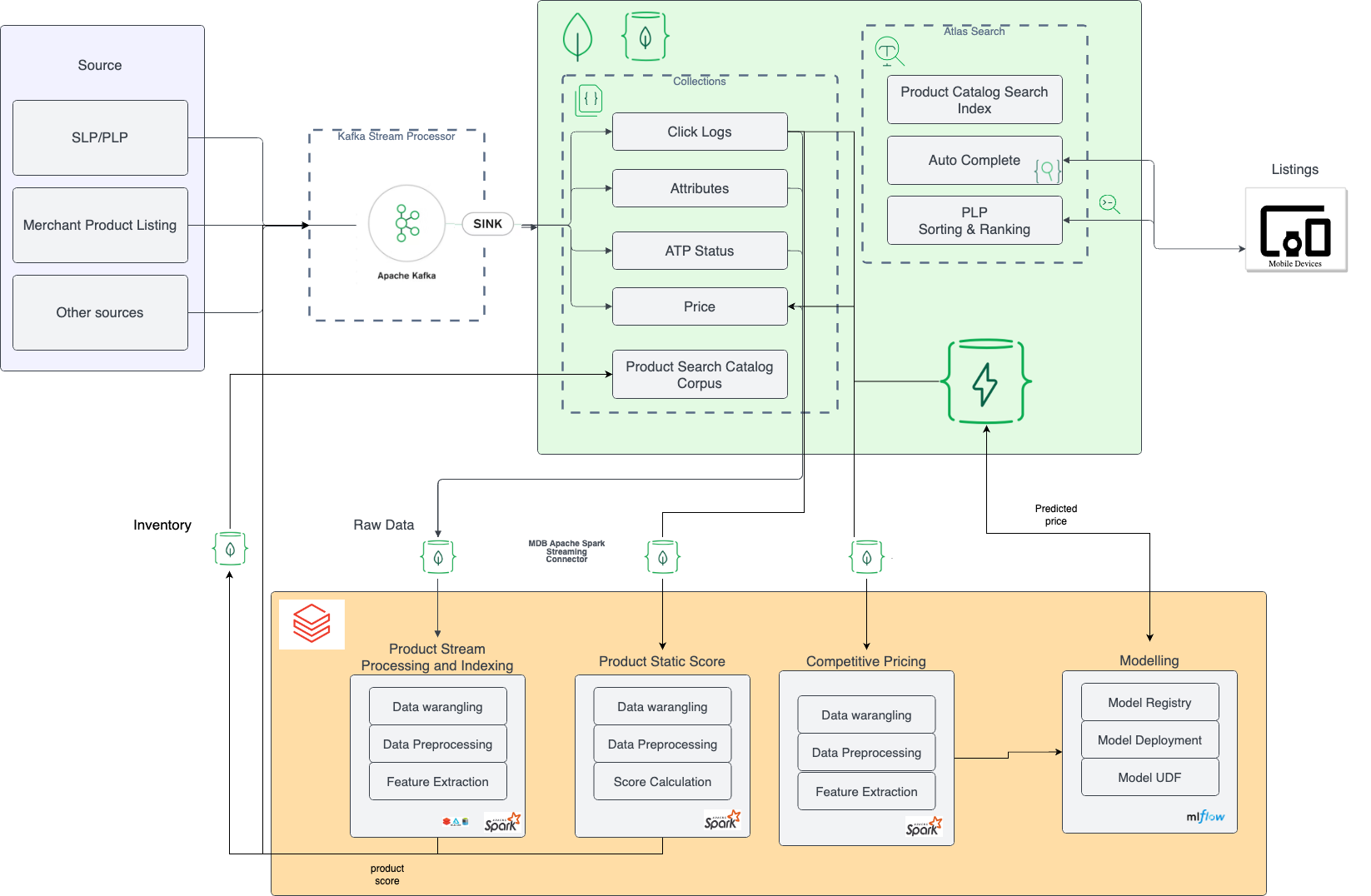
A arquitetura de varejo do E Commerce para preços e pesquisas competitivas é composta por 4 camadas principais, a saber:
Um sistema apoiado por comércio eletrônico moderno deve poder coletar dados de várias fontes em tempo real, bem como cargas em lote e transformar esses dados em um esquema/formato sobre o qual um índice de pesquisa do Lucene pode ser criado para permitir a descoberta do inventário adicionado. Além disso, a arquitetura também deve ser capaz de integrar o comportamento do cliente no site, contribui positivamente para a descoberta do inventário e, ao mesmo tempo, apóia e melhora as decisões de compra com uma boa margem de lucro.
Esses recursos são bons capturados na arquitetura de comércio eletrônico acima, onde: 1. Com a ajuda do conector MongoDB Kafka, somos capazes de afundar dados em tempo real de várias fontes para o MongoDB. 2. Com a ajuda do MongoDB Spark Connector e Databricks MLFlow, somos capazes de preparar recursos e treinar um modelo robusto de ML para prever o preço do inventário, dados os dados do clickstream quase em tempo real sobre os produtos fornecidos. 3. Todos os fluxos gerados de dados são transformados e gravados em uma visão unificada na coleção MongoDB chamada Catalog, que é usada para criar índices de pesquisa e apoiar a consulta e a descoberta de produtos. 4. Com a ajuda dos recursos de pesquisa do Atlas e dos pipelines de agregação robustos, podemos alimentar recursos como pesquisa/descoberta, personalização hiper e destaque em aplicativos móveis/web.
Antes de executar o aplicativo, você precisará instalar o seguinte no seu sistema:
Clone este repositório para sua máquina local.
git clone https://github.com/ashwin-gangadhar-mdb/retail-pricing-search-personaliztion.git
cd mobile-demo/backend-serviceAtualize a string de conexão MongoDB no seguinte arquivo.
./service/app.pyInstale as dependências do projeto usando PIP
pip3 install -r [label](service/requirements.txt)
Execute o código Python.
python3 app.py
./run-connector.sh ./kafka/mongodb-clogs-sink-connector.properties ./kafka/mongodb-atp-sink-connector.propertiesgit clone https://github.com/ashwin-gangadhar-mdb/retail-pricing-search-personaliztion.git cd frontend
npm install react-scripts@latestfrontend/src/config.jsnpm start

