superduper
0.4.5

O Superduper é uma estrutura baseada em Python para criar fluxos de trabalho e aplicativos de fim de ponta de final de ponta-2-Data em seus próprios dados, integrando-se aos principais bancos de dados. It supports the latest technologies and techniques, including LLMs, vector-search, RAG, multimodality as well as classical AI and ML paradigms.
Os desenvolvedores podem aproveitar o Superduper, construindo objetos composicionais e declarativos que superam os detalhes da implantação, orquestração e versão e muito mais para o mecanismo SuperDuper. This allows developers to completely avoid implementing MLOps, ETL pipelines, model deployment, data migration and synchronization.
Usando o Superduper é simplesmente " Cape ": conecte-se aos seus dados, aplique a IA arbitrária a esses dados, embalam e reutilizem o aplicativo em dados arbitrários e execute consultas e previsões de AI-Database sobre as saídas e dados de IA resultantes.
Conectar
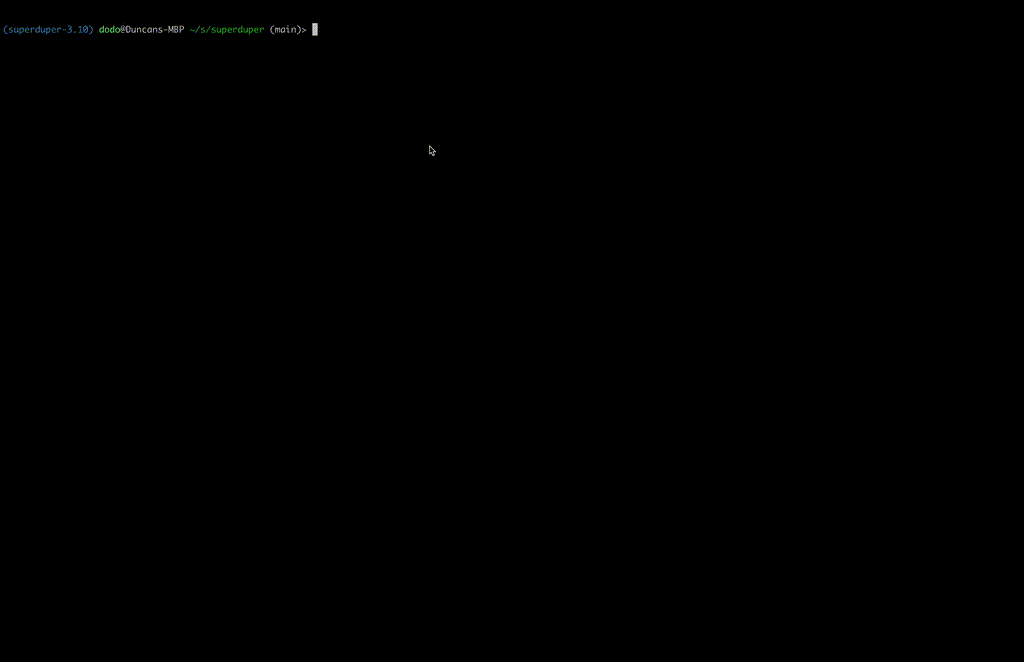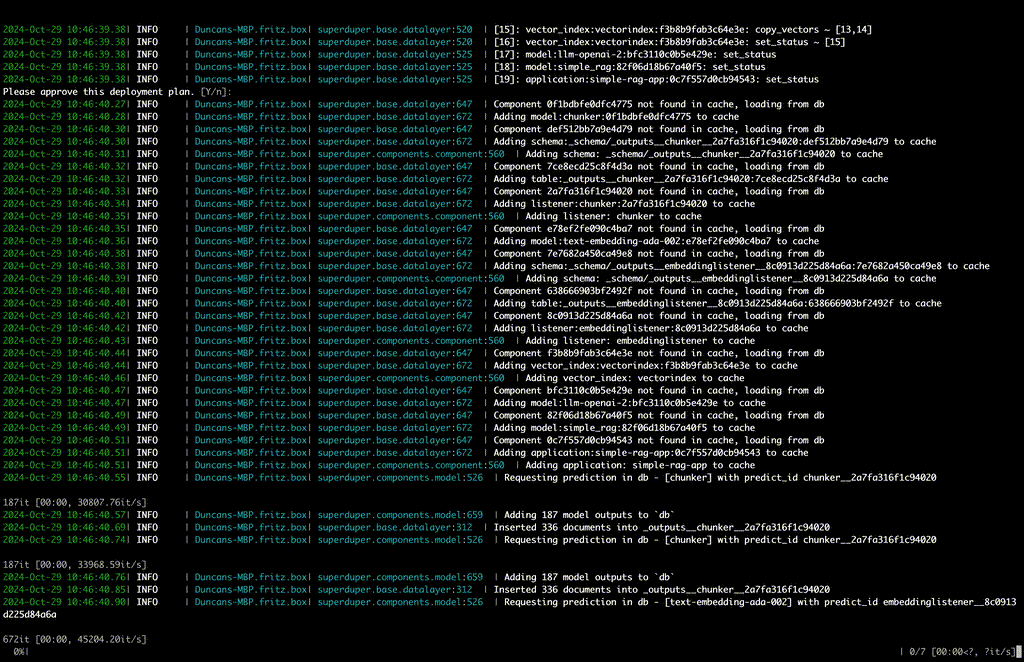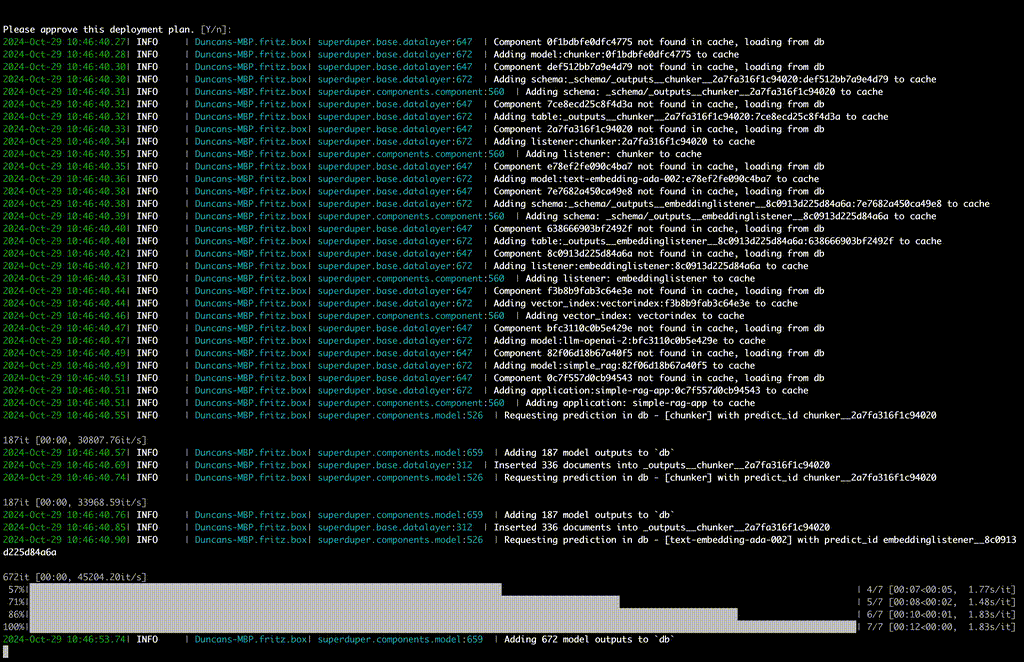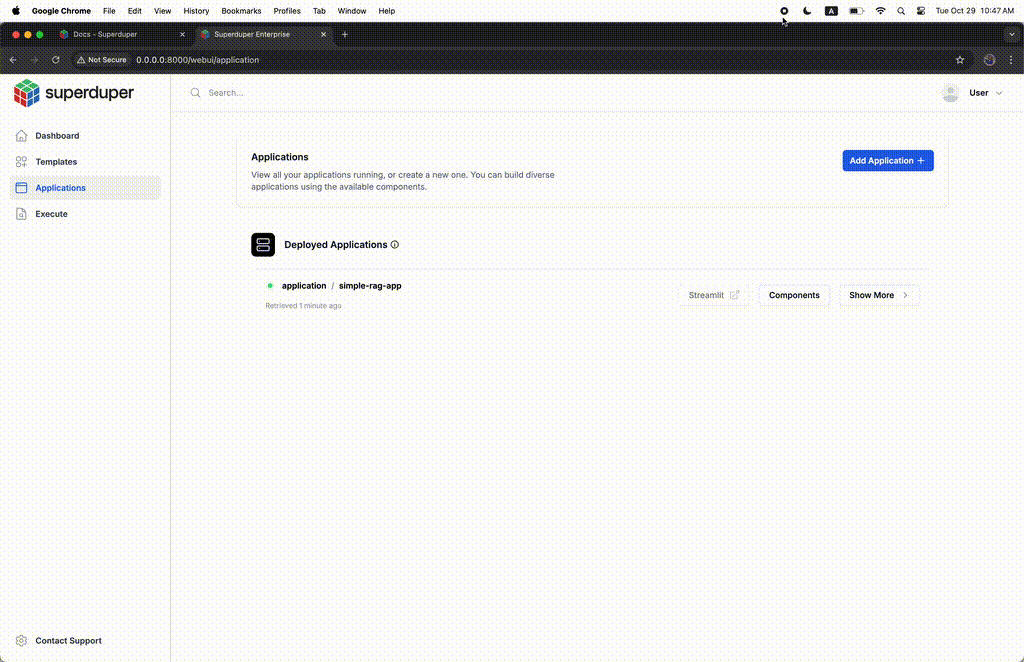
db = superduper ( 'mongodb|postgres|mysql|sqlite|duckdb|snowflake://<your-db-uri>' )Aplicar
listener = MyLLM ( 'self_hosted_llm' , architecture = 'llama-3.2' , postprocess = my_postprocess ). to_listener ( 'documents' , key = 'txt' )
db . apply ( listener )Pacote
application = Application ( 'my-analysis-app' , components = [ listener , vector_index ])
template = Template ( 'my-analysis' , component = app , substitutions = { 'documents' : 'table' })
template . export ( 'my-analysis' )Executar
query = db [ 'documents' ]. like ({ 'txt' , 'Tell me about Superduper' }, vector_index = 'my-index' ). select ()
query . execute ()Superduper may be run anywhere; you can also contact us to learn more about the enterprise platform for bringing your Superduper workflows to production at scale.
Superduper is flexible enough to support a huge range of AI techniques and paradigms. We have a range of pre-built functionality in the plugins and templates directories. Em particular, o Superduper se destaca quando a IA e os dados precisam interagir de maneira contínua e fortemente integrada. Aqui estão alguns exemplos ilustrativos, que você pode experimentar em nossos modelos:
Estamos procurando nos conectar com desenvolvedores entusiasmados para contribuir com o repertório de modelos e fluxos de trabalho pré-construídos incríveis disponíveis em SourDuper Open-Source. Participe da discussão, contribuindo com questões e solicita solicitações!
Component ) usando um modelo de programação declarativo, que se integra de perto aos dados no seu banco de dados, usando um conjunto simples de primitivas e classes base.Component inter-relacionados em um Application AI-DataComponent , Model e Application testados por batalha usando Template , dando aos desenvolvedores um ponto fácil de começar com implementações de IA difíceisApplication e criar uma segida elegante do mundo da IA para os mundos de dados de dados de dados.Model , bem como dados primários de banco de dados, para permitir a última geração de aplicativos AI-Data, incluindo todos os sabores de pesquisa vetorial, rag e muito, muito mais. Flexibilidade maciça
Combine qualquer modelo de IA baseado em Python, API do ecossistema com os bancos de dados e armazéns testados mais estabelecidos e de batalha; Snowflake, MongoDB, Postgres, MySQL, SQL Server, SQLite, BigQuery e Clickhouse são todos suportados.
Integração perfeita, evitando mlops
Remova a necessidade de implementar os MLOPs, usando os componentes de superduper declarativos e composicionais, que especificam o estado final que os modelos e dados devem atingir.
Promover a reutilização e portabilidade do código
Componentes do pacote como modelos, expondo os principais parâmetros necessários para reutilizar e comunicar aplicativos de IA em sua comunidade e organização.
Economia de custos
Implementar a pesquisa de vetores e incorporar a geração sem exigir um banco de dados vetorial dedicado. Alterne sem esforço entre modelos auto -hospedados e modelos hospedados na API, sem grandes alterações de código.
Mover para a produção sem nenhum esforço adicional
A API REST do Superduper permite que modelos instalados sejam servidos sem trabalho adicional de desenvolvimento. Para escalabilidade de grau corporativo, cofres de falhas, segurança e log, aplicativos e fluxos de trabalho criados com o SuperDuper, podem ser implantados em um clique no SuperDuper Enterprise.
main ? Estamos trabalhando em um próximo lançamento de 0.4.0 . Neste lançamento, temos:
Component aciona cálculos iniciais e cálculos dependentes de dados usando @trigger Isso permitirá uma grande diversidade de tipos Component , além do Model bem estabelecido, Listener , VectorIndex .
CDC (Captura de Data-Data)Isso permitirá que os desenvolvedores criem uma gama de funcionalidades que reagem a alterações de dados recebidas
Template para permitir unidades reutilizáveis de funcionalidade completa Os componentes salvos como instâncias Template permitirão que os usuários reimplavam facilmente suas implementações de Component e Application já implantadas e testadas, em fontes de dados alternativas e com os principais parâmetros alternados para atender aos requisitos operacionais.
Template de concreto ao projeto Essas instâncias Template podem ser aplicadas com superduper com um comando simples simples
superduper apply <template> '{"variable_1": "value_1", "variable_2": ...}'
ou:
from superduper import templates
app = template ( variable_1 = 'value_1' , variable_2 = 'value_2' , ...)
db . apply ( app ) Agora, você pode visualizar suas instâncias Component , Application e Template na interface do usuário e executar consultas usando instâncias QueryTemplate , diretamente contra o servidor REST.
superduper start
Instalação :
pip install superduper-frameworkExibir modelos pré-construídos disponíveis:
superduper lsConecte e aplique um modelo pré-construído:
( Nota: os modelos pré-criados são suportados apenas pelo Python 3.10; você pode usar todos os outros recursos no Python 3.11+. )
# e.g. 'mongodb://localhost:27017/test_db'
SUPERDUPER_DATA_BACKEND= < your-db-uri > superduper apply simple_ragExecute uma consulta ou previsão sobre os resultados:
from superduper import superduper
db = superduper ( '<your-db-uri>' ) # e.g. 'mongodb://localhost:27017/test_db'
db [ 'rag' ]. predict ( 'Tell me about superduper' )Veja e monitore tudo na interface superduper. Da linha de comando:
superduper startDepois de fazer isso, você está pronto para construir seus próprios componentes, aplicativos e modelos!
Comece copiando um modelo existente, para seu próprio ambiente de desenvolvimento:
superduper bootstrap < template_name > --destination templates/my-template Edite o notebook build.ipynb , para construir sua própria funcionalidade.
If you have any problems, questions, comments, or ideas:
[email protected] .Existem muitas maneiras de contribuir e elas não se limitam à redação do código. Congratulamo -nos com todas as contribuições como:
Consulte o nosso guia contribuinte para obter detalhes.
Obrigado a essas pessoas maravilhosas:
O Superduper é de código aberto e pretende ser um esforço da comunidade, e não seria possível sem o seu apoio e entusiasmo. Ele é distribuído nos termos da licença Apache 2.0. Qualquer contribuição feita para este projeto estará sujeita às mesmas disposições.
Estamos à procura de pessoas legais que investem no problema que estamos tentando resolver para se juntar a nós em tempo integral. Encontre papéis que estamos tentando preencher aqui!


