최근 다운코드 편집자는 소셜미디어 플랫폼 블루스카이(Bluesky)에서 대규모 데이터 스크래핑 사건이 발생했다는 사실을 알게 돼 큰 관심을 끌었다. 기계 학습 사서 Daniel van Strien은 Bluesky의 API 인터페이스를 통해 백만 개가 넘는 공개 사용자 게시물을 스크랩하여 AI 회사인 Hugging Face에 업로드했습니다. Bluesky 사용자는 플랫폼에서 그러한 행위를 명시적으로 금지하지 않았음에도 불구하고 자신의 콘텐츠가 이러한 방식으로 사용되는 데 동의하지 않았기 때문에 이러한 움직임은 논란을 불러일으켰습니다. 이번 사건은 개방형 플랫폼의 데이터 보안과 사용자 개인정보 보호 간의 모순을 부각시켰습니다.
최근 소셜 미디어 플랫폼 Bluesky는 대규모 데이터 스크랩 사고에 직면했습니다. 기계 학습 사서인 Daniel van Strien은 Bluesky의 API에서 백만 개가 넘는 공개 사용자 게시물을 스크랩하여 해당 데이터를 AI 회사인 Hugging Face에 업로드했습니다.

데이터세트에는 사용자의 분산 식별자(DID)와 사용자별 콘텐츠를 검색할 수 있는 기능 세트가 포함되어 있습니다. Van Stirling은 이 데이터 세트의 주요 목적은 소셜 미디어 동향 분석, 콘텐츠 조정 및 게시 패턴 연구 외에도 언어 모델 및 자연어 처리 개발을 위한 것이라고 말했습니다.
데이터 스크래핑 작업은 Bluesky 사용자가 자신의 콘텐츠 사용에 동의하지 않았기 때문에 광범위한 우려를 불러일으켰습니다. 플랫폼이 이러한 행위를 명시적으로 금지하지는 않지만 Fire API는 게시물, 좋아요, 팔로우, 계정 변경 사항 및 기타 정보를 포함하는 "집계된 시간순 공개 데이터 스트림"을 제공합니다. 따라서 Bluesky 콘텐츠는 이론적으로 타사 개발자에게 공개됩니다.
이에 대해 블루스카이 관계자는 “블루스카이는 인터넷의 다른 사이트와 마찬가지로 개방형 공개 소셜 네트워크다.
robots.txt 파일이 항상 외부 회사가 이러한 사이트를 크롤링하는 것을 막는 것은 아니지만 상황은 비슷합니다. 우리는 Bluesky 사용자가 자신의 데이터 사용에 동의하는지 여부를 외부 조직/개발자와 소통하고 외부 조직이 사용자의 동의를 존중할 것을 기대하는 방법을 찾고 있으며 이 목표를 달성하는 방법을 적극적으로 논의하고 있습니다. "
이 사건은 사용자들, 특히 경쟁 플랫폼 X의 새로운 AI 훈련 정책으로 인해 Bluesky로 전환한 많은 사람들 사이에서 우려를 불러일으켰습니다. 특히 Van Strain은 보고서가 게시된 직후 Hugging Face에서 데이터세트를 삭제했습니다.
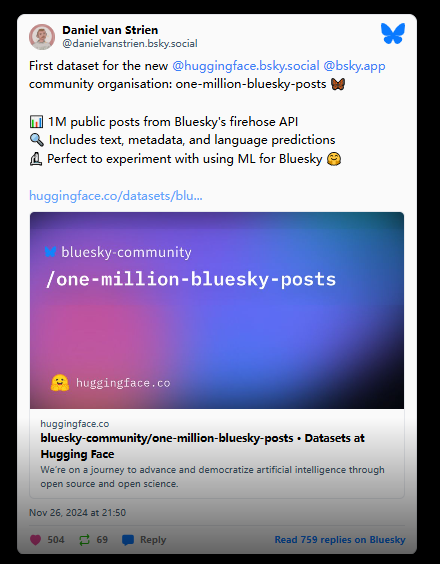
그는 Bluesky에 대해 다음과 같이 말했습니다. "저는 이 저장소에서 Bluesky 데이터를 제거했습니다. 플랫폼을 위한 도구 개발을 지원하고 싶지만 이러한 관행이 데이터 수집의 투명성과 동의 원칙을 위반한다는 것을 알고 있습니다. 이에 대해 깊이 후회합니다. 죄송합니다. ”
이번 사건으로 인해 개방형 플랫폼 데이터 사용 권한과 사용자 개인정보 보호에 대한 논의가 촉발되었습니다. Bluesky는 또한 개방성과 사용자 데이터 보안 간의 관계를 더 잘 균형잡을 수 있는 솔루션을 적극적으로 찾고 있다고 밝혔습니다. 이는 사용자의 권리와 이익을 더 잘 보호하기 위해 기술 및 정책 수준에서 공동 노력이 필요한 다른 개방형 플랫폼에도 참조 의미가 있습니다.