AI 기술의 급속한 발전으로 시각 언어 모델에 대한 수요가 날로 증가하고 있지만, 높은 컴퓨팅 리소스 요구 사항으로 인해 일반 장치에 적용하는 데에는 한계가 있습니다. Downcodes의 편집자는 오늘 SmolVLM이라는 경량의 시각적 언어 모델을 소개합니다. 이 모델은 노트북 및 소비자급 GPU와 같이 리소스가 제한된 장치에서 효율적으로 실행할 수 있습니다. SmolVLM의 출현으로 더 많은 사용자가 고급 AI 기술을 경험할 수 있는 기회를 얻었고, 사용 임계값을 낮추었으며, 개발자에게 보다 편리한 연구 도구를 제공했습니다.
최근 몇 년 동안 비전 및 언어 작업에 머신러닝 모델을 적용하려는 요구가 증가하고 있지만, 대부분의 모델은 막대한 컴퓨팅 리소스를 필요로 하며 개인 디바이스에서는 효율적으로 실행되지 않습니다. 특히 노트북, 소비자 GPU, 모바일 장치와 같은 소형 장치는 시각적 언어 작업을 처리할 때 큰 어려움에 직면합니다.
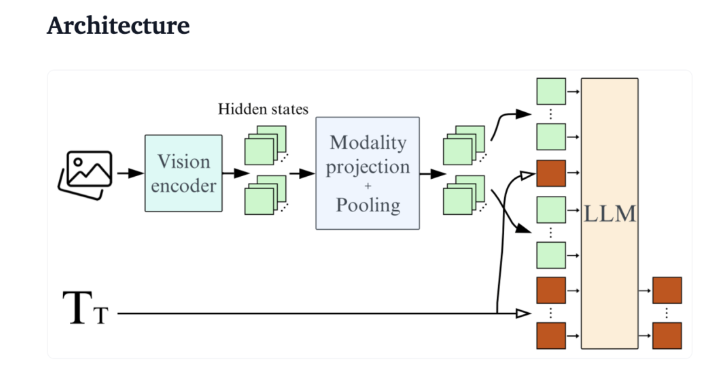
Qwen2-VL을 예로 들면, 성능은 뛰어나지만 하드웨어 요구 사항이 높아 실시간 애플리케이션에서의 유용성이 제한됩니다. 따라서 더 적은 리소스로 실행할 수 있는 경량 모델을 개발하는 것이 중요한 요구 사항이 되었습니다.
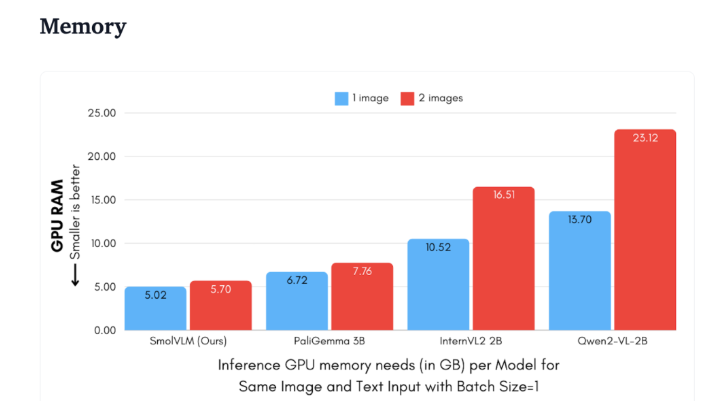
Hugging Face는 최근 장치측 추론을 위해 특별히 설계된 2B 매개변수 시각적 언어 모델인 SmolVLM을 출시했습니다. SmolVLM은 GPU 메모리 사용량 및 토큰 생성 속도 측면에서 다른 유사한 모델보다 성능이 뛰어납니다. 주요 특징은 성능 저하 없이 노트북이나 소비자급 GPU와 같은 소형 장치에서 효율적으로 실행할 수 있는 기능입니다. SmolVLM은 성능과 효율성 사이의 이상적인 균형을 찾아 이전 유사 모델에서 극복하기 어려웠던 문제를 해결합니다.
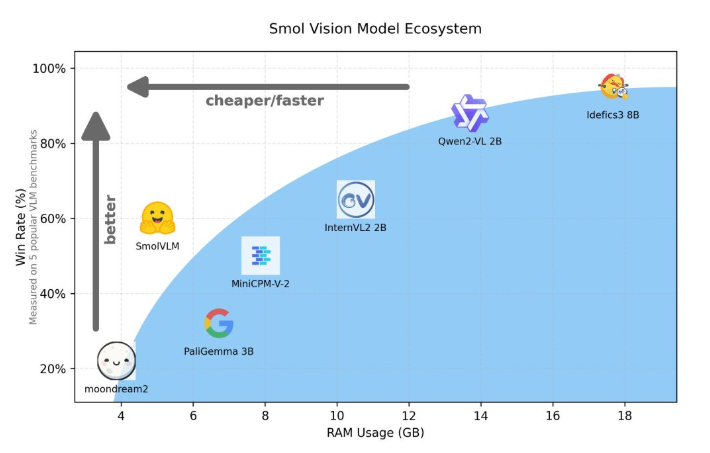
Qwen2-VL2B와 비교하여 SmolVLM은 경량 추론이 가능한 최적화된 아키텍처 덕분에 토큰을 7.5~16배 더 빠르게 생성합니다. 이러한 효율성은 최종 사용자에게 실질적인 이점을 제공할 뿐만 아니라 사용자 경험을 크게 향상시킵니다.
기술적 관점에서 SmolVLM은 효율적인 장치 측 추론을 지원하는 최적화된 아키텍처를 갖추고 있습니다. 사용자는 Google Colab에서 쉽게 세부 조정을 수행하여 실험 및 개발의 한계를 크게 낮출 수 있습니다.
작은 메모리 공간으로 인해 SmolVLM은 이전에 유사한 모델을 호스팅할 수 없었던 장치에서 원활하게 실행될 수 있습니다. 50프레임 YouTube 동영상을 테스트할 때 SmolVLM은 27.14%의 점수로 좋은 성능을 보였고 리소스 소비 측면에서 리소스 집약적인 두 모델을 능가하여 강력한 적응성과 유연성을 보여주었습니다.
SmolVLM은 시각적 언어 모델 분야에서 중요한 이정표입니다. 이 출시를 통해 일상적인 장치에서 복잡한 시각적 언어 작업을 실행할 수 있어 현재 AI 도구의 중요한 격차를 메울 수 있습니다.
SmolVLM은 속도와 효율성이 뛰어날 뿐만 아니라 개발자와 연구원에게 값비싼 하드웨어 비용 없이 시각적 언어 처리를 용이하게 하는 강력한 도구를 제공합니다. AI 기술이 계속 대중화됨에 따라 SmolVLM과 같은 모델은 강력한 기계 학습 기능에 대한 접근성을 더욱 높여줄 것입니다.
데모:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
전체적으로 SmolVLM은 경량의 시각적 언어 모델에 대한 새로운 기준을 세웠습니다. 효율적인 성능과 편리한 사용은 AI 기술의 대중화와 개발을 크게 촉진할 것입니다. 우리는 미래에도 더 유사한 혁신을 통해 AI 기술이 더 많은 사람들에게 혜택을 줄 수 있기를 기대합니다.