30 seconds of swift code
1.0.0
30 초의 코드의 신속한 구현 : 30 초 이내에 이해할 수있는 유용한 Swift 4 스 니펫의 선별 된 컬렉션.
참고 :-이것은 원래 30 초 코드와 제휴하지 않습니다.
JavaScript Land에서 여기에 온 경우이 프로젝트가 Swift 4 사용한다는 것을 알고 있어야하므로 모든 스 니펫이 모든 시스템에서 예상대로 작동하지는 않습니다. Project 로 이동 한 다음 아래 단계를 따라 Swift 버전을 확인해야합니다. 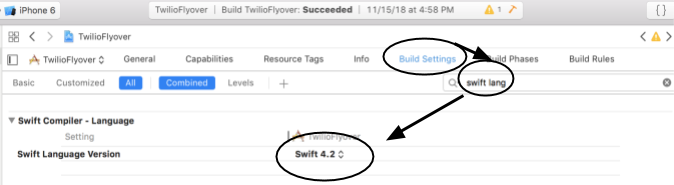
Swift 4의 최신 안정적인 릴리스를 설치하는 데 도움이 필요한 경우 Swift.org를 확인하십시오. 문제가 발생하면 stackoverflow를 확인하십시오.
이 프로젝트에는 초보자와 신규 이민자가 Swift 4에서 자신의 기술을 신속하게 확대하는 데 도움이되는 유용한 스 니펫이 많이 포함되어 있습니다.
bubbleSortfilterBoolschunkcountOccurrencesdeepFlattendifferenceduplicatesevery_nthinsertionSortfisherYatesShufflecalcMediancalcBetterMedianaveragefactorialgcdlcm1lcm2maxnminnallUniquejustKeysjustValuesbytesFromStringcapitalizeFirstcapitalizeEveryWordcountVowelslowerCaseFirstLetterOfFirstWordisLowerCaseisUpperCasepalindromeanagramdropdropRightWhilenthElementfilterNonUniquegenericFlattencommaSeparatedmostFrequentrepeatingaveragegcdlcm1lcm2maxnminnfactorialcalcMediancalcBetterMedianradiansToDegreesallUniquejustKeysjustValuesbytesFromStringcapitalizeFirstcapitalizeEveryWordcountVowelslowerCaseFirstLetterOfFirstWordisLowerCaseisUpperCasepalindromesnakesimple_snake_casefirstUniqueCharacterrepeatingrepeatingBubblesort는 인접한 요소가 잘못된 순서에있는 경우 반복적으로 비교하고 교환하는 기술을 사용하는 정렬 알고리즘입니다.
func bubbleSort ( _ inputArr : [ Int ] ) -> [ Int ] {
guard inputArr . count > 1 else {
return inputArr
}
var res = inputArr
let count = res . count
var isSwapped = false
repeat {
isSwapped = false
for index in stride ( from : 1 , to : count , by : 1 ) {
if res [ index ] < res [ index - 1 ] {
res . swapAt ( ( index - 1 ) , index )
isSwapped = true
}
}
} while isSwapped
return res
} bubbleSort ( [ 32 , 12 , 12 , 23 , 11 , 19 , 81 , 76 ] ) //[11, 12, 12, 19, 23, 32, 76, 81]
back 위로 돌아갑니다
배열을 특정 크기의 더 작은 배열로 청크합니다.
func chunk ( arr : [ Any ] , chunkSize : Int ) -> [ Any ] {
let chunks = stride ( from : 0 , to : arr . count , by : chunkSize ) . map {
Array ( arr [ $0 ..< min ( $0 + chunkSize , arr . count ) ] )
}
return chunks
} chunk ( arr : [ 2 , 4 , 6 , 8 ] , chunkSize : 1 ) //[[2], [4], [6], [8]]
chunk ( arr : [ 1 , 3 , 5 , 9 ] , chunkSize : 4 ) //[[1, 3, 5, 9]]
chunk ( arr : [ " hi " , " yo " , " bye " , " bai " ] , chunkSize : 3 ) //[["hi", "yo", "bye"], ["bai"]]
chunk ( arr : [ " young " , " scrappy " , " hungry " ] , chunkSize : 2 ) //[["young", "scrappy"], ["hungry"]]
back 위로 돌아갑니다
주어진 목록에서 모든 n 번째 요소를 반환하고 주어진 목록의 모든 n 번째 요소가 포함 된 새 목록이 작성됩니다.
func getEvery ( nth : Int , from list : [ Any ] ) {
var nthElements = [ Any ] ( )
var shiftedList = list
shiftedList . insert ( 0 , at : 0 )
for (i , element ) in shiftedList . enumerated ( ) {
if i > 0 && i . isMultiple ( of : nth ) {
nthElements . append ( element )
}
}
} getEvery ( nth : 4 , from : [ " The " , " quick " , " brown " , " fox " , " jumped " , " over " , " the " , " lazy " , " dog " ] ) //["fox", "lazy"]
getEvery ( nth : 2 , from : [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ] ) //[2, 4, 6, 8]
back 위로 돌아갑니다
부울이 아닌 모든 값을 제거하십시오.
func filterBools ( _ inputArr : [ Any ] ) -> [ Any ] {
return inputArr . compactMap { $0 as? Bool }
} filterBools ( [ false , 2 , " lol " , 3 , " a " , " s " , 34 , false , true ] ) //[false, false, true]
back 위로 돌아갑니다
배열에서 문자열의 발생을 계산합니다.
func countOccurrences ( arr : [ String ] , into : String ) -> Int {
return arr . reduce ( 0 ) { $1 == into ? $0 + 1 : $0 }
} countOccurrences ( arr : [ " FOO " , " FOO " , " BAR " ] , into : " FOO " ) //2
back 위로 돌아갑니다
깊은 재귀로 목록을 평평하게합니다.
func deepFlatten ( arr : [ AnyHashable ] ) -> [ AnyHashable ] {
var arr2 = [ AnyHashable ] ( )
for el in arr {
if let el = el as? Int {
arr2 . append ( el )
}
if let el = el as? [ Any ] {
let res = deepFlatten ( arr : el as! [ AnyHashable ] )
for i in res {
arr2 . append ( i )
}
}
}
return arr2
} deepFlatten ( arr : [ 6 , 5 , 4 , [ 3 , 2 ] , [ 1 ] ] ) //[6, 5, 4, 3, 2, 1]
back 위로 돌아갑니다
주어진 배열 모두에 포함되지 않은 리턴 요소 (즉, 하나의 배열에만 포함 된 요소는 둘 다가 아닙니다.)
func difference ( arr1 : [ AnyHashable ] , arr2 : [ AnyHashable ] ) -> Set < AnyHashable > {
return Set ( arr1 ) . symmetricDifference ( arr2 )
} difference ( arr1 : [ 2 , 4 , 6 , 8 ] , arr2 : [ 10 , 8 , 6 , 4 , 2 , 0 ] ) //10
difference ( arr1 : [ " mulan " , " moana " , " belle " , " elsa " ] , arr2 : [ " mulan " , " moana " , " belle " , " pocahontas " ] ) //elsa, pocahontas
back 위로 돌아갑니다
주어진 배열에서 중복 요소를 확인하십시오.
func duplicates ( arr1 : [ AnyHashable ] ) -> Bool {
return arr1 . count != ( Set < AnyHashable > ( arr1 ) ) . count
} duplicates ( arr1 : [ 5 , 4 , 3 , 2 ] ) //false
duplicates ( arr1 : [ " hermione " , " hermione " , " ron " , " harry " ] ) //true
back 위로 돌아갑니다
삽입 정렬 알고리즘-Ray Wenderlich https://github.com/raywenderlich/swift-algorithm-club/tree/master/insertion%20Sort.
func insertionSort ( _ array : [ Int ] ) -> [ Int ] {
var a = array // 1
for index in stride ( from : 1 , to : a . count , by : 1 ) {
var y = index
while y > 0 && a [ y ] < a [ y - 1 ] { // 3
a . swapAt ( y - 1 , y )
y -= 1
}
}
return a
} let list = [ 10 , - 1 , 3 , 9 , 2 , 27 , 8 , 5 , 1 , 3 , 0 , 26 ]
insertionSort ( list ) //[-1, 0, 1, 2, 3, 3, 5, 8, 9, 10, 26, 27]
back 위로 돌아갑니다
공식 Apple 개발자 문서 - https://developer.apple.com/documentation/swift/array/1688499-sort 링크
var integerArray = [ 5 , 8 , 2 , 3 , 656 , 9 , 1 ]
var stringArray = [ " India " , " Norway " , " France " , " Canada " , " Italy " ]
integerArray . sort ( ) //[1, 2, 3, 5, 8, 9, 656]
stringArray . sort ( ) //["Canada", "France", "India", "Italy", "Norway"]integerArray . sort ( ) //[1, 2, 3, 5, 8, 9, 656]
stringArray . sort ( ) //["Canada", "France", "India", "Italy", "Norway"]
back 위로 돌아갑니다
Fisher-Yates 알고리즘 일명 Knuth Shuffle 어레이를 셔플하면 배열이 O (n) 시간에 각 순열이 동일 할 가능성이있는 배열의 균일 한 셔플을 만듭니다.
func shuffle ( arr1 : [ AnyHashable ] ) -> [ AnyHashable ] {
var arr2 = arr1
for i in stride ( from : arr1 . count - 1 , through : 1 , by : - 1 ) {
let j = Int . random ( in : 0 ... i )
if i != j {
arr2 . swapAt ( i , j )
}
}
return arr2
} var foo = [ 1 , 2 , 3 ]
shuffle ( arr1 : foo ) //[2,3,1] , foo = [1,2,3]
back 위로 돌아갑니다
배열을 입력으로 가져 와서 유형의 평평한 배열로 변환합니다. (옵션 처리)
/// We use flat map to flatten the array and compact map to handle optionals
/// - Parameter arrays: Array of arrays to flatten
func flatten < T > ( arrays : [ [ T ? ] ] ) -> [ T ] {
return arrays . flatMap { $0 } . compactMap { $0 }
} flatten ( arrays : [ [ " a " , " b " , " c " , " d " ] , [ " e " , " f " , " g " , " y " ] ] ) // ["a", "b", "c", "d", "e", "f", "g", "y"]
flatten ( arrays : [ [ 1 , nil , 3 , 4 ] , [ 5 , 6 , 7 , 8 ] ] ) // [1, 3, 4, 5, 6, 7, 8]
back 위로 돌아갑니다
문자열 배열을 취하고 쉼표로 분리 된 입력 목록에서 각 요소와 함께 단일 문자열을 반환합니다.
/// Return the elements of `strings` separated by ", "
func commaSeparated ( _ strings : [ String ] ) -> String {
return strings . joined ( separator : " , " )
} let strs = [ " Foo " , " Bar " , " Baz " , " Qux " ]
commaSeparated ( strs ) // "Foo, Bar, Baz, Qux"
back 위로 돌아갑니다
배열을 가져 와서 배열에 나타나는 가장 빈번한 요소를 반환합니다. 배열의 요소 유형은 해시 가능을 준수해야합니다.
// Return the most frequent element that appears in the array
func mostFrequent < Type : Hashable > ( _ arr : [ Type ] ) -> Type ? {
var dict = [ Type : Int ] ( )
for element in arr {
if dict [ element ] == nil {
dict [ element ] = 1
} else {
dict [ element ] ! += 1
}
}
return dict . sorted ( by : { $0 . 1 > $1 . 1 } ) . first ? . key
} mostFrequent ( [ 1 , 2 , 5 , 4 , 1 , 9 , 8 , 7 , 4 , 5 , 1 , 5 , 1 ] ) // 1
mostFrequent ( [ " a " , " b " , " c " , " a " ] ) // "a"
mostFrequent ( [ ] ) // nil
back 위로 돌아갑니다
배열에서 평균 둘 이상의 복식을 반환합니다.
func average ( arr : [ Double ] ) -> Double {
return arr . reduce ( 0 , + ) / Double ( arr . count )
} average ( arr : [ 5 , 4 , 3 , 2 , 1 ] ) //3
back 위로 돌아갑니다
숫자의 계승을 계산합니다.
func factorial ( num : Int ) -> Int {
var fact : Int = 1
for index in stride ( from : 1 , to : num + 1 , by : 1 ) {
fact = fact * index
}
return fact
} factorial ( num : 4 ) //24
factorial ( num : 10 ) //3628800
back 위로 돌아갑니다
재귀를 사용한 두 정수 사이의 가장 큰 공통 제수를 계산합니다.
func gcd ( num1 : Int , num2 : Int ) -> Int {
let mod = num1 % num2
if mod != 0 {
return gcd ( num1 : num2 , num2 : mod )
}
return num2
} gcd ( num1 : 228 , num2 : 36 ) //12
gcd ( num1 : - 5 , num2 : - 10 )
back 위로 돌아갑니다
위의 gcd 함수를 사용하여 가장 일반적인 두 정수 중에서 가장 일반적인 배수를 반환합니다.
func lcm1 ( num1 : Int , num2 : Int ) -> Int {
return abs ( num1 * num2 ) / gcd ( num1 : num1 , num2 : num2 )
} lcm1 ( num1 : 12 , num2 : 7 ) //84
back 위로 돌아갑니다
첫 번째 LCM을 사용하여 어레이의 가장 일반적인 배수.
func lcm2 ( arr1 : [ Int ] ) -> Int {
return arr1 . reduce ( 1 ) { lcm1 ( num1 : $0 , num2 : $1 ) }
} lcm2 ( arr1 : [ 4 , 3 , 2 ] ) //12
back 위로 돌아갑니다
제공된 배열에서 최대 요소를 반환합니다.
func maxn ( arr1 : [ Int ] ) -> Int {
if let ( _ , maxValue ) = arr1 . enumerated ( ) . max ( by : { $0 . element < $1 . element } ) {
return maxValue
}
return 0
} maxn ( arr1 : [ 2 , 9 , 5 ] ) //9
[ 2 , 9 , 5 ] . max ( ) //9
back 위로 돌아갑니다
내장 .min() 함수없이 배열에서 최소 정수를 반환합니다 (결과를 비교하기 위해 예제에 사용).
func minn ( arr1 : [ Int ] ) -> Int {
var minVal = arr1 [ 0 ]
for num in arr1 {
minVal = ( num < minVal ) ? num : minVal
}
return minVal
} minn ( arr1 : [ 8 , 2 , 4 , 6 ] ) //2
[ 8 , 2 , 4 , 6 ] . min ( ) //2
back 위로 돌아갑니다
정수 배열의 중앙값을 계산하는 한 가지 방법.
func calcMedian ( arr : [ Int ] ) -> Float {
return Float ( arr . sorted ( by : < ) [ arr . count / 2 ] )
}정수 배열의 중앙값을 계산하는 더 나은 방법.
func calcBetterMedian ( arr : [ Int ] ) -> Float {
let sorted = arr . sorted ( )
if sorted . count % 2 == 0 {
return Float ( ( sorted [ ( sorted . count / 2 ) ] + sorted [ ( sorted . count / 2 ) - 1 ] ) ) / 2
}
return Float ( sorted [ ( sorted . count - 1 ) / 2 ] )
} calcBetterMedian ( arr : [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 ] ) //returns 4.5라디안에서 각도를 각도로 변환하십시오.
func radiansToDegrees ( _ angle : Double ) -> Double {
return angle * 180 / . pi
} radiansToDegrees ( 4 ) // 229.183
back 위로 돌아갑니다
모든 고유 한 값에 대한 평평한 목록을 확인하고, 목록 값이 모두 고유하고 잘못된 경우, 목록 값이 모두 고유하지 않은 경우 true를 반환합니다.
func allUnique ( arr : [ AnyHashable ] ) -> Bool {
return arr . count == Set < AnyHashable > ( arr ) . count
} allUnique ( arr : [ 5 , 4 , 3 , 2 ] ) //true
allUnique ( arr : [ " lol " , " rofl " , " lol " ] ) //false
back 위로 돌아갑니다
키 값 쌍 사전을 수용하고 키 만 키의 새로운 배열을 반환하는 함수.
func justKeys ( dict : Dictionary < AnyHashable , AnyHashable > ) -> [ AnyHashable ] {
return Array ( dict . keys )
} var dict : Dictionary < String , String > = [ " Mulan " : " Mushu " , " Anna " : " Olaf " , " Pocahontas " : " Fleeko " ]
justKeys ( dict : dict ) //[Anna, Mulan, Pocahontas]
back 위로 돌아갑니다
키 값 쌍의 사전을 받아들이고 값의 새로운 배열을 반환하는 함수.
func justValues ( dict : Dictionary < AnyHashable , AnyHashable > ) -> [ AnyHashable ] {
return Array ( dict . values )
} justValues ( dict : dict ) //[Olaf, Mushu, Fleeko]
back 위로 돌아갑니다
문자열의 바이트를 얻습니다.
func bytes ( _ str : String ) -> Int {
return str . utf8 . count
} bytes("Hello")
back 위로 돌아갑니다
문자열의 첫 글자를 대문자로하여 나머지는 동일하게 남겨 둡니다.
func capitalizeFirst ( str : String ) -> String {
var components = str . components ( separatedBy : " " )
components [ 0 ] = components [ 0 ] . capitalized
return components . joined ( separator : " " )
} capitalizeFirst(str: "i like cheesE") //I like cheesE
back 위로 돌아갑니다
문자열의 모든 단어의 첫 글자를 대문자로 만듭니다.
func capitalizeEveryWord ( str : String ) -> String {
return str . capitalized
} capitalizeEveryWord ( str : " on a scale from 1 to 10 how would you rate your pain " ) //On A Scale From...
capitalizeEveryWord ( str : " well, hello there! " ) //Well, Hello There!
back 위로 돌아갑니다
제공된 string 의 모음 number 재조정합니다.
func countVowels ( str : String ) -> Int {
var vowelCount = 0
let vowels = Set ( [ " a " , " e " , " i " , " o " , " u " ] )
for char in str . lowercased ( ) {
if vowels . contains ( " ( char ) " ) {
vowelCount += 1
}
}
return vowelCount
} countVowels ( str : " hi mom " ) //2
countVowels ( str : " aeiou " ) //5
back 위로 돌아갑니다
문자열에서 첫 번째 단어의 첫 글자를 데카 이블화합니다.
func lowerCaseFirstLetterOfFirstWord ( str : String ) -> String {
var components = str . components ( separatedBy : " " )
components [ 0 ] = components [ 0 ] . lowercased ( )
return components . joined ( separator : " " )
} lowerCaseFirstLetterOfFirstWord ( str : " Christmas Switch was a solid movie " ) //christmas Switch...
back 위로 돌아갑니다
문자열의 문자가 자본화되면 true를 반환하십시오.
func isLowerCase ( str : String ) -> Bool {
return str == str . lowercased ( )
} isLowerCase ( str : " I LOVE CHRISTMAS " ) //false
isLowerCase ( str : " <3 lol " ) //true
back 위로 돌아갑니다
문자열의 각 문자가 대문자인지 확인합니다.
func isUpperCase ( str : String ) -> Bool {
return str == str . uppercased ( )
} isUpperCase ( str : " LOLOLOL " ) //true
isUpperCase ( str : " lmao " ) //false
isUpperCase ( str : " Rofl " ) //false
back 위로 돌아갑니다
주어진 문자열이 Palindrome이고 그렇지 않으면 False 경우 True 반환합니다.
func palindrome ( str : String ) -> Bool {
return str . lowercased ( ) == String ( str . reversed ( ) ) . lowercased ( )
} palindrome ( str : " racecar " ) //true
palindrome ( str : " Madam " ) //true
palindrome ( str : " lizzie " ) //false
back 위로 돌아갑니다
주어진 두 줄이 서로 완벽한 아나그램 인 경우 True 반환합니다. 그렇지 않으면 False .
/// Return `true` if the 2 given strings are "perfect" anagrams.
/// (they consist of the same characters excluding whitespace)
func anagram ( _ str1 : String , _ str2 : String ) -> Bool {
let s1 = str1 . filter { !$0 . isWhitespace } . lowercased ( )
let s2 = str2 . filter { !$0 . isWhitespace } . lowercased ( )
return s1 . count == s2 . count && s1 . sorted ( ) == s2 . sorted ( )
} anagram ( " abcd3 " , " 3acdb " ) // true
anagram ( " 123 " , " 456 " ) // false
anagram ( " Buckethead " , " Death Cube K " ) // true
back 위로 돌아갑니다
왼쪽에서 n 요소가 제거 된 새 배열을 반환합니다.
func drop ( arr : [ AnyHashable ] , num : Int ) -> [ AnyHashable ] {
return Array ( arr . dropFirst ( num ) ) //need Array() to concert ArraySlice to Array
} drop ( arr : [ 5 , 4 , 3 , 2 , 1 , 0 ] , num : 1 )
drop ( arr : [ " Huey " , " Dewey " , " Louie " ] , num : 3 )2D 배열에서 생성 된 CSV 스트링을 반환합니다.
func arrayToCSV ( _ inputArray : [ Array < String > ] ) -> String {
var csv : String = " "
for row in inputArray {
csv . append ( row . map { " " ( $0 ) " " } . joined ( separator : " , " ) + " n " )
}
return csv
} arrayToCSV ( [ [ " a " , " b " , " c " ] , [ " d " , " e " , " f " ] , [ " g " , " h " , " i " ] ] )
//"a", "b", "c"
//"d", "e", "f"
//"g", "h", "i"주어진 함수를 뒤집은 인수로 반환합니다.
func flip < A , B , C > ( _ function : @escaping ( ( A , B ) -> C ) ) -> ( ( B , A ) -> C ) {
return { ( a , b ) in
return function ( b , a )
}
}// flip example 1
func concat ( _ alpha : String , _ beta : String ) -> String {
return alpha + beta
}
let reverseConcat = flip ( concat )
concat ( " A " , " B " ) //"AB"
reverseConcat ( " A " , " B " ) //"BA"
// flip example 2
func gt ( _ a : Int , _ b : Int ) -> Bool {
return a > b
}
let lt = flip ( gt )
gt ( 5 , 3 ) //true
lt ( 5 , 3 ) //false
gt ( 2 , 5 ) //false
lt ( 2 , 5 ) //true
back 위로 돌아갑니다
배열 끝에서 전달 된 함수가 true가 반환 될 때까지 요소를 제거합니다.
func dropRight ( arr : [ Int ] , while predicate : ( ( Int ) -> Bool ) ) -> [ Int ] {
var returnArr = arr
for item in arr . reversed ( ) {
if predicate ( item ) { break }
returnArr = returnArr . dropLast ( )
}
return returnArr
} dropRight ( arr : [ 1 , 2 , 3 , 4 , 5 ] , while : { $0 < 0 } ) //[]
dropRight ( arr : [ 1 , 2 , 3 , 4 , 5 ] , while : { $0 > 0 } ) //[1, 2, 3, 4, 5]
back 위로 돌아갑니다
목록에서 비 유니 값을 필터링합니다
func filterNonUnique ( arr : [ Any ] ) -> [ Any ] {
let set = NSOrderedSet ( array : arr )
return set . array
} filterNonUnique ( arr : [ 1 , 2 , 2 , 3 , 5 ] ) // [1, 2, 3, 5]
filterNonUnique ( arr : [ " Tim " , " Steve " , " Tim " , " Jony " , " Phil " ] ) // ["Tim", "Steve", "Jony", "Phil"]
back 위로 돌아갑니다
뱀 케이스에서 새 문자열을 반환합니다
func snake ( str : String ) -> String ? {
let pattern = " ([a-z0-9])([A-Z]) "
let regex = try ? NSRegularExpression ( pattern : pattern , options : [ ] )
let range = NSRange ( location : 0 , length : str . count )
return regex ? . stringByReplacingMatches ( in : str , options : [ ] , range : range , withTemplate : " $1_$2 " )
. lowercased ( )
. replacingOccurrences ( of : " " , with : " _ " )
. replacingOccurrences ( of : " - " , with : " _ " )
} snake ( str : " camelCase " ) // 'camel_case'
snake ( str : " some text " ) // 'some_text'
snake ( str : " some-mixed_string With spaces_underscores-and-hyphens " ) // 'some_mixed_string_with_spaces_underscores_and_hyphens'
snake ( str : " AllThe-small Things " ) // "all_the_smal_things"
back 위로 돌아갑니다
뱀 케이스에서 새 문자열을 반환합니다
func snakeCase ( _ string : String ) -> String {
let arrayOfStrings = text . components ( separatedBy : " " )
return arrayOfStrings . joined ( separator : " _ " )
} let text = " Snake case is the practice of writing compound words or phrases in which the elements are separated with one underscore character and no spaces. "
snakeCase ( text )
back 위로 돌아갑니다
문자열에서 첫 번째 고유 문자를 반환합니다
func firstUniqueCharacter ( _ str : String ) -> Character ? {
var countDict : [ Character : Int ] = [ : ]
for char in str {
countDict [ char ] = ( countDict [ char ] ?? 0 ) + 1
}
return str . filter { countDict [ $0 ] == 1 } . first
} firstUniqueCharacter ( " barbeque nation " ) //"r"
back 위로 돌아갑니다
루프를 사용하지 않고 끈 n 번 인쇄합니다.
func repeating ( _ repeatedValue : String , count : Int ) {
guard count > 0 else {
return
}
print ( repeatedValue )
repeating ( repeatedValue , count : count - 1 )
} repeating ( " Text " , count : 5 )
back 위로 돌아갑니다
바이트로 문자열 길이를 반환합니다
func stringLenghtInBytes ( string : String ) -> Int {
return ( string as NSString ) . length
} stringLenghtInBytes("Hello")
back 위로 돌아갑니다
주어진 목록에서 모든 n 번째 요소를 반환합니다.
func everyNth ( list : [ Any ] , n : Int ) -> [ Any ] {
return list . enumerated ( ) . compactMap ( { ( $0 . offset + 1 ) % n == 0 ? $0 . element : nil } )
} everyNth ( list : [ 1 , 2 , 3 , 4 , 5 , 6 ] , n : 2 ) // [ 2, 4, 6 ]
everyNth ( list : [ " a " , " b " , " c " , " d " , " e " , " f " ] , n : 3 ) // [ "c", "f" ]
back 위로 돌아갑니다
배열이 오름차순 순서로 정렬 된 경우 1, 내림차순 순서는 -1, 불충분 한 경우 0을 반환합니다.
func isSorted ( arr : [ Int ] ) -> Int {
var asc : Bool = true
var prev : Int = Int . min
for elem in arr {
if elem < prev {
asc = false
break
}
prev = elem
}
if asc {
return 1
}
var dsc : Bool = true
prev = Int . max
for elem in arr {
if elem > prev {
dsc = false
break
}
prev = elem
}
if dsc {
return - 1
}
return 0
} isSorted ( arr : [ 1 , 2 , 2 , 4 , 8 ] ) // 1
isSorted ( arr : [ 8 , 4 , 4 , 2 , 1 ] ) // -1
isSorted ( arr : [ 1 , 4 , 2 , 8 , 4 ] ) // 0배열이 오름차순 순서로 정렬 된 경우 1, 내림차순 순서 인 경우 -1, 불완전하지 않은 경우 0- 옵션 2 최단
func sortedArray ( arr : [ Int ] ) -> Int {
let sortedArr = arr . sorted ( by : { $1 > $0 } )
return arr == sortedArr ? 1 : arr == sortedArr . reversed ( ) ? - 1 : 0
}//Input sortedArray(arr: [1,2,3,4,5]) - Output 1
//Input sortedArray(arr: [5,4,3,2,1]) - Output -1
//Input sortedArray(arr: [6,2,3,4,8]) - Output 0
back 위로 돌아갑니다
Camel Case String (예 : ' apple_store ', 'Timcook')을 뱀 케이스로 변환
func camelCaseToSnake ( str : String ) -> String {
guard let regex = try ? NSRegularExpression ( pattern : " ([a-z0-9])([A-Z]) " , options : [ ] ) else {
return str
}
let range = NSRange ( location : 0 , length : str . count )
return regex . stringByReplacingMatches ( in : str , options : [ ] , range : range , withTemplate : " $1_$2 " ) . lowercased ( )
} camelCaseToSnake ( str : " appleIphoneX " )
camelCaseToSnake ( str : " camelCaseStringToSnakeCase " )
camelCaseToSnake ( str : " string " )
camelCaseToSnake ( str : String ( ) )
camelCaseToSnake ( str : " firstPullRequestForHacktoberFest?☔️? " )
back 위로 돌아갑니다
플립은 인수로 기능을 취한 다음 첫 번째 인수를 마지막으로 만듭니다.
func flip < A , B , C > ( _ f : @escaping ( A , B ) -> C ) -> ( B , A ) -> C {
return { ( b , a ) in f ( a , b ) }
} String . init ( repeating : " ? " , count : 5 ) == flip ( String . init ( repeating : count : ) ) ( 5 , " ? " ) //true
back 위로 돌아갑니다
정점의 이웃을 반환합니다
public func neighborsForIndex ( _ index : Int ) -> [ VertexType ] {
return edges [ index ] . map ( { self . vertices [ $0 . v ] } )
}
back 위로 돌아갑니다
Lizzie Siegle
압둘 하킴 아제 툰 모비
하토 스 바보 사
폴 슈 로더
빅토르 소콜 로프
Sai Sandeep Mutyala
Sören Kirchner
Alexey Ivanov
Júlio John Tavares Ramos
카밀로 안드레스 이바라 yepes
니콜라스 combe
윌리엄 스팬 펠 너
Natchanon A.


