insight chat
1.0.0
FASTAPI -FASTAPI는 표준 파이썬 유형 힌트를 기반으로 Python 3.7+를 갖춘 API를 구축하기위한 현대적이고 빠른 (고성능)입니다.
llamaindex -llamaindex는 컨텍스트 확대로부터 이익을 얻는 LLM 기반 애플리케이션의 데이터 프레임 워크입니다. 이러한 LLM 시스템은 Rag 시스템으로 불리며 "검색 된 세대"를 나타냅니다. Llamaindex는보다 정확한 텍스트 생성을 위해 LLM에 안전하고 안정적으로 주입하기 위해 개인 또는 도메인 별 데이터를보다 쉽게 수집, 구조 및 액세스 할 수있는 필수 추상화를 제공합니다.
Mongodb Atlas -Mongodb Atlas는 MongoDB를 구축하는 동일한 사람들이 개발 한 완전히 관리되는 클라우드 데이터베이스입니다.
Atlas 벡터 검색 - Atlas 벡터 검색을 통해 구조화되지 않은 데이터를 검색 할 수 있습니다. Openai 및 Hugging Face와 같은 기계 학습 모델로 벡터 임베딩을 만들고 검색 증강 생성 (RAG), 시맨틱 검색, 권장 엔진, 동적 개인화 및 기타 사용 사례를 위해 Atlas에 저장 및 색인 할 수 있습니다.
참고 : Atlas 벡터 검색을 사용하려면 KNN 인덱스를 작성해야합니다.
Atlas Search 에서 컬렉션에 대한 검색 색인을 만듭니다. "JSON 편집기"모드를 선택하고 다음 내용으로 인덱스를 설정하십시오. {
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 1536,
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
시로 설치 :
pip install poetry
poetry config virtualenvs.in-project true
poetry shell
poetry install
uvicorn app.main:app --host 127.0.0.1 --port 9080
docker build -t insight-chat .
docker run -d --name insight-chat -p 8080:8080 insight-chat




요컨대, llamaindex는 다음 패턴을 사용하여 문서 정보를 저장합니다.
문서의 텍스트는 "청크"라고도 알려진 여러 노드로 나뉩니다. 문서 ID를 기본 키로 사용하면 각 문서를 나타내는 개체 (주로 파일 이름 및 해시와 같은 메타 데이터)는 해당 문서의 노드 목록과 함께 문서 저장에 저장됩니다. 노드 ID를 기본 키로 사용하여 노드의 임베딩은 벡터 저장소에 저장됩니다.
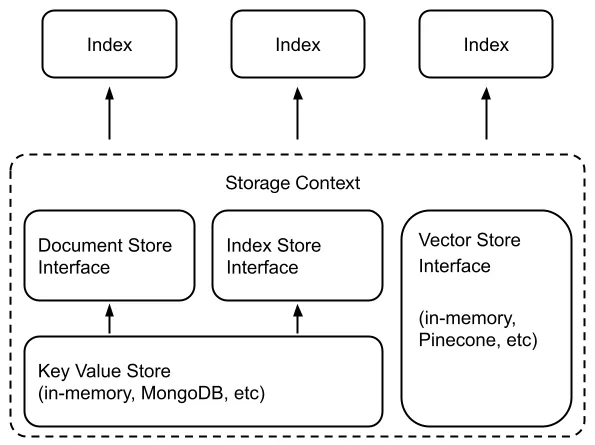
이 프로젝트에서는 매장의 3 가지 MongoDB 구현이 사용됩니다.
https://medium.com/@luoning.nici/llamaindex-in-depth-practice-how-to-build-a-build--subsystem-with-mongodb-atlas-f306bfb480
https://docs.llamaindex.ai/en/stable/index.html
https://www.mongodb.com/atlas


