pygraft
1.0.0
이것은이 백서에 처음 제시된 Pygraft의 오픈 소스 구현입니다.
Pygraft는 사용자 지정 매개 변수를 기반으로 합성하면서도 사실적인 스키마 및 (KGS)를 생성하기위한 오픈 소스 파이썬 라이브러리입니다. 생성 된 리소스는 도메인-공수성이며, 즉 특정 애플리케이션 필드에 연결되어 있지 않습니다.
스키마와 KGS를 합성 할 수 있다는 것은 데이터에 민감하거나 쉽게 이용할 수없는 도메인에서 연구를 수행하는 데 중요한 이정표입니다. Pygraft는 연구원과 실무자가 원하는 사양에 대한 최소한의 지식을 제공 한 스키마와 KG를 즉시 스키마와 KG를 생성 할 수 있도록합니다.
Pygraft에는 다음과 같은 기능이 있습니다.
PyGraft의 최신 안정 버전은 PYPI에서 다운로드하여 설치할 수 있습니다.
pip install pygraft최신 버전의 pygraft는 github 소스에서 다음과 같이 직접 설치할 수 있습니다.
pip install git+https://github.com/nicolas-hbt/pygraft.git다음 버전의 pygraft에서 추가 기능이 제공됩니다. 이름을 지정하지만 몇 가지 :
우선 순위가 높습니다
중간 우선 순위
rdfs:subPropertyOf , owl:FunctionalProperty 및 owl:InverseFunctionalProperty 는 동시에 세 가지에 대한 0이 아닌 값으로 인해 일관되지 않은 KGS로 이어질 수 있습니다.우선 순위가 낮습니다
Pygraft의 기여는 다음과 같습니다.
우리가 아는 한, Pygraft는 단일 파이프 라인에서 스키마와 KG를 합성 할 수있는 최초의 발전기입니다.
생성 된 스키마 및 KG는 확장 된 RDF 및 올빼미 구조 세트로 설명되므로 세밀한 자원 설명과 일반적인 시맨틱 웹 표준을 엄격하게 준수 할 수 있습니다.
광범위한 매개 변수는 사용자가 지정할 수 있습니다. 이를 통해 특성이 다른 무한한 수의 그래프를 생성 할 수 있습니다. 매개 변수에 대한 자세한 내용은 공식 문서의 매개 변수 섹션을 참조하십시오.
높은 수준의 관점에서 볼 때 전체 Pygraft 생성 파이프 라인은 그림 1에 나와 있습니다. 특히 클래스 및 관계 생성기는 사용자 지정된 매개 변수로 초기화되고 스키마를 점차적으로 빌드하는 데 사용됩니다. 스키마의 논리적 일관성은 이후 Owlready2의 Hermit Conesaler를 사용하여 점검됩니다. 이 스키마를 기반으로 KG를 생성하는 데 관심이있는 경우 KG 생성기는 KG 관련 매개 변수로 초기화되고 이전에 생성 된 스키마와 융합하여 KG를 순차적으로 빌드합니다. 궁극적으로, 결과 Kg의 논리적 일관성은 은둔을 사용하여 (다시) 평가된다.
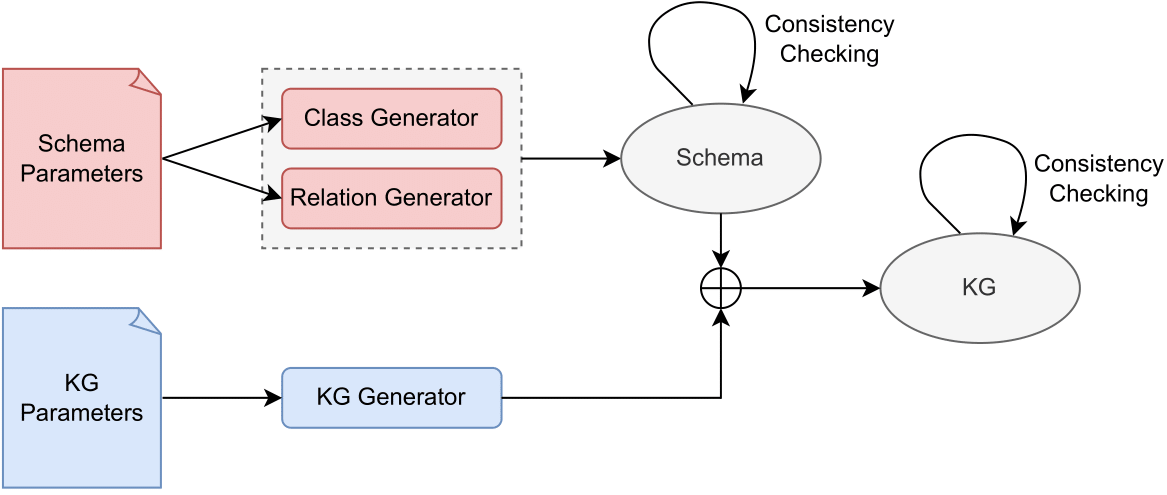
그림 1 : 파이 그래프트 개요
설치되면 pygraft는 다음과 같이로드 할 수 있습니다.
import pygraft중요한 것은 다음과 함께 모든 기능에 액세스 할 수 있습니다.
pygraft . __all__ 스키마 생성에만 관심이 있다고 가정 해 봅시다. 먼저 템플릿 구성 파일 (예 : .yaml 구성 파일 create_yaml_template() 을 검색해야합니다.
pygraft . create_yaml_template () 이제 템플릿은 현재 작업 디렉토리에서 생성되었으며 기본적으로 template.yml 로 명명되었습니다.
이 파일에는 모든 조정 가능한 매개 변수가 포함되어 있습니다. 의미에 대한 자세한 내용은 매개 변수 섹션을 확인하십시오.
단순성을 위해이 템플릿을 수정하고 기본 매개 변수 값을 고수 할 계획이 없습니다.
온톨로지 생성은 generate_schema(path) 함수를 통해 가능하며 구성 파일에 대한 상대 경로 만 필요합니다.
중요한
다음 단계에서는 스키마와 kg를 생성하기 위해 Java를 설치해야하고 $ java_home 환경 변수를 올바르게 할당해야합니다. Hermit Conesler는 현재 Java를 사용하여 실행하기 때문입니다.
우리의 경우 구성 파일은 template.yml 이라는 이름이 지정되어 있으며 현재 작업 디렉토리에 위치하므로 다음과 같습니다.
pygraft . generate_schema ( "template.yml" ) 생성 된 스키마는 output/template/schema.rdf 에서 검색 할 수 있습니다. 추가 파일은 프로세스 중에 생성됩니다 : output/template/class_info.json 및 output/template/relation_info.json . 이 파일은 각각 생성 된 스키마의 클래스와 관계에 대한 중요한 정보를 제공합니다.
이제 pygraft를 사용하여 kg을 생성하는 방법을 살펴 보겠습니다. 이 섹션에서는 이미 KG를 생성하기위한 청사진 역할을하는 스키마가 있다고 가정합니다. KG 생성과 관련된 매개 변수가 포함되어 있기 때문에 이전과 동일한 구성 파일을 사용할 수 있습니다 (스키마를 요청했기 때문에 이전에는 사용되지는 않았지만) kg을 생성합니다.
pygraft . generate_kg ( "template.yml" ) 생성 된 kg는 output/template/full_graph.rdf 에서 검색 할 수 있습니다. output/template/schema.rdf (예 : 온톨로지 정보)에서 상속 된 정보를 개인과 관련된 정보와 결합합니다.
대부분의 경우 단일 프로세스에서 스키마와 KG를 모두 생성하려고합니다. Pygraft는 발전된 두 가지 함수 generate_schema(path) 및 generate_kg(path) generate(path) 함수로이를 허용합니다.
pygraft . generate ( "template.yml" )Pygraft 저장소를 컴퓨터에 복제했다고 가정합니다.
pip install pygraft # Displaying help
python -m pygraft.main --help # Generating a schema from a local template file
python -m pygraft.main -g generate_schema -conf template.yml
# ... then browse the resulting schema in the ./output/template folder. pygraft에 기여하는 데 관심이 있습니까? 연락을 고려하십시오 : [email protected]
Pygraft를 좋아한다면 Pygraft를 다운로드하고 Github 저장소를 주연하여 개발을 홍보하고 홍보하십시오!
출판물에서 Pygraft를 사용하거나 언급하면 다음과 같은 작업을 인용하십시오.
@misc{hubert2023pygraft,
title={PyGraft: Configurable Generation of Schemas and Knowledge Graphs at Your Fingertips},
author={Nicolas Hubert and Pierre Monnin and Mathieu d'Aquin and Armelle Brun and Davy Monticolo},
year={2023},
eprint={2309.03685},
archivePrefix={arXiv},
primaryClass={cs.AI}
}


