libaco
v.1.2.4
Libaco- 빠르고 가벼운 C 비대칭 코 루틴 라이브러리.
이 프로젝트의 코드 이름은 Arkenstone입니까?
비대칭 Coroutine & Arkenstone은 aco 라는 이유입니다.
현재 Intel386 및 X86-64의 SYS V ABI를 지원합니다.
이 프로젝트에 대한 간단한 요약은 다음과 같습니다.
위의 " 가장 빠른 "이라는 문구는 Intel386 또는 AMD64의 SYS v ABI를 준수하는 가장 빠른 컨텍스트 전환 구현을 의미합니다.
문제와 PR은 환영합니다 ???
참고 : master 대신 릴리스를 사용하여 최종 바이너리를 구축하십시오.
이 readme 외에도 https://libaco.org/docs의 문서를 방문 할 수도 있습니다. 웹 사이트의 문서 가이 readme에서 뒤쳐 질 수 있으므로 차이가있는 경우이 readme를 따르십시오.
생산 준비.
#include "aco.h"
#include <stdio.h>
// this header would override the default C `assert`;
// you may refer the "API : MACROS" part for more details.
#include "aco_assert_override.h"
void foo ( int ct ) {
printf ( "co: %p: yield to main_co: %dn" , aco_get_co (), * (( int * )( aco_get_arg ())));
aco_yield ();
* (( int * )( aco_get_arg ())) = ct + 1 ;
}
void co_fp0 () {
printf ( "co: %p: entry: %dn" , aco_get_co (), * (( int * )( aco_get_arg ())));
int ct = 0 ;
while ( ct < 6 ){
foo ( ct );
ct ++ ;
}
printf ( "co: %p: exit to main_co: %dn" , aco_get_co (), * (( int * )( aco_get_arg ())));
aco_exit ();
}
int main () {
aco_thread_init ( NULL );
aco_t * main_co = aco_create ( NULL , NULL , 0 , NULL , NULL );
aco_share_stack_t * sstk = aco_share_stack_new ( 0 );
int co_ct_arg_point_to_me = 0 ;
aco_t * co = aco_create ( main_co , sstk , 0 , co_fp0 , & co_ct_arg_point_to_me );
int ct = 0 ;
while ( ct < 6 ){
assert ( co -> is_end == 0 );
printf ( "main_co: yield to co: %p: %dn" , co , ct );
aco_resume ( co );
assert ( co_ct_arg_point_to_me == ct );
ct ++ ;
}
printf ( "main_co: yield to co: %p: %dn" , co , ct );
aco_resume ( co );
assert ( co_ct_arg_point_to_me == ct );
assert ( co -> is_end );
printf ( "main_co: destroy and exitn" );
aco_destroy ( co );
co = NULL ;
aco_share_stack_destroy ( sstk );
sstk = NULL ;
aco_destroy ( main_co );
main_co = NULL ;
return 0 ;
} # default build
$ gcc -g -O2 acosw.S aco.c test_aco_synopsis.c -o test_aco_synopsis
$ ./test_aco_synopsis
main_co: yield to co: 0x1887120: 0
co: 0x1887120: entry: 0
co: 0x1887120: yield to main_co: 0
main_co: yield to co: 0x1887120: 1
co: 0x1887120: yield to main_co: 1
main_co: yield to co: 0x1887120: 2
co: 0x1887120: yield to main_co: 2
main_co: yield to co: 0x1887120: 3
co: 0x1887120: yield to main_co: 3
main_co: yield to co: 0x1887120: 4
co: 0x1887120: yield to main_co: 4
main_co: yield to co: 0x1887120: 5
co: 0x1887120: yield to main_co: 5
main_co: yield to co: 0x1887120: 6
co: 0x1887120: exit to main_co: 6
main_co: destroy and exit
# i386
$ gcc -g -m32 -O2 acosw.S aco.c test_aco_synopsis.c -o test_aco_synopsis
# share fpu and mxcsr env
$ gcc -g -D ACO_CONFIG_SHARE_FPU_MXCSR_ENV -O2 acosw.S aco.c test_aco_synopsis.c -o test_aco_synopsis
# with valgrind friendly support
$ gcc -g -D ACO_USE_VALGRIND -O2 acosw.S aco.c test_aco_synopsis.c -o test_aco_synopsis
$ valgrind --leak-check=full --tool=memcheck ./test_aco_synopsis자세한 내용은 "빌드 및 테스트"부분을 참조하십시오.
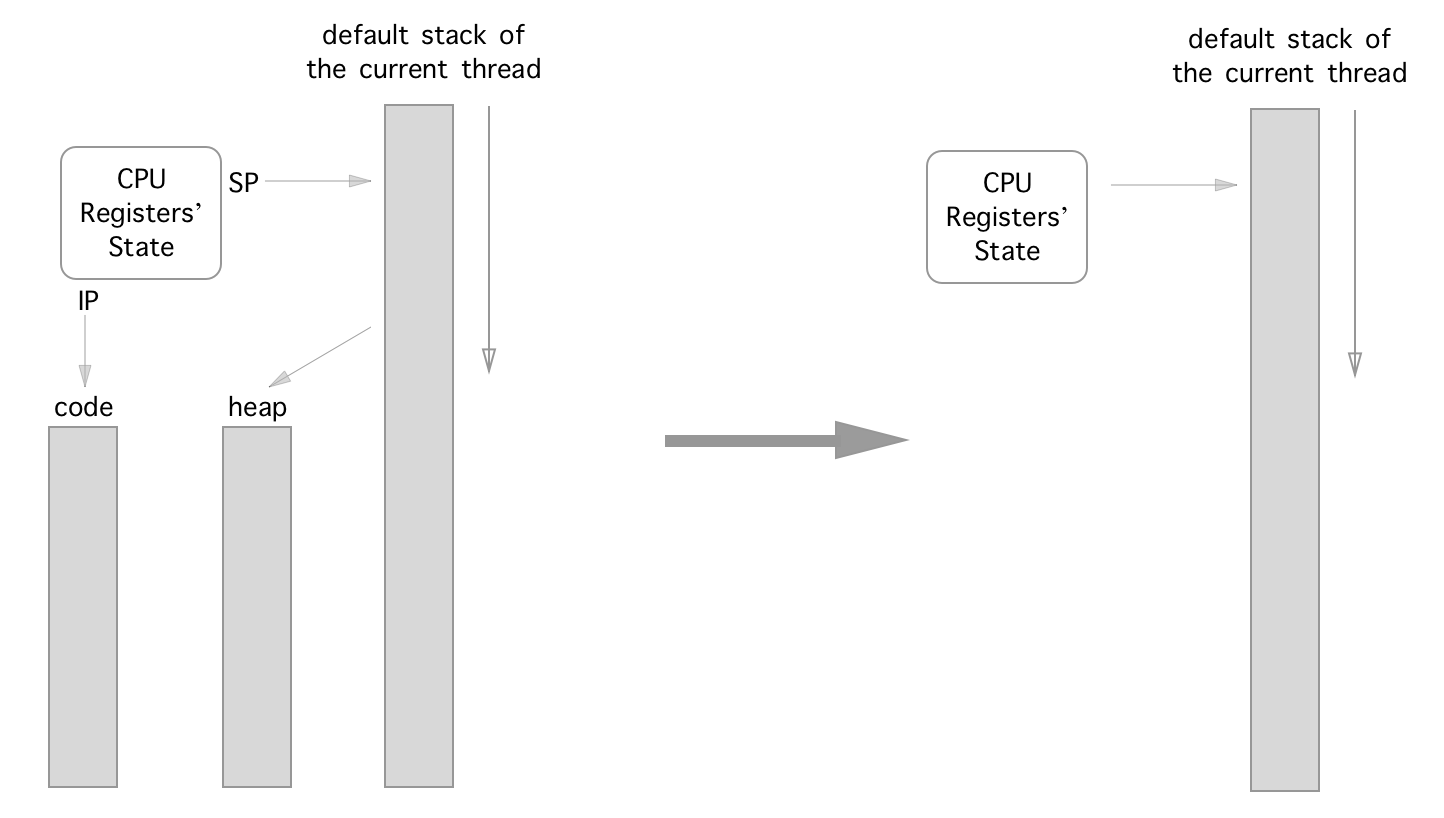
일반 실행 상태에는 4 가지 기본 요소가 있습니다 : {cpu_registers, code, heap, stack} .
코드 정보는 ({E|R})?IP 레지스터로 표시되며 힙에서 할당 된 메모리의 주소는 일반적으로 스택에 직접 또는 간접적으로 저장되므로 4 가지 요소를 2 개로 단순화 할 수 있습니다. {cpu_registers, stack} .
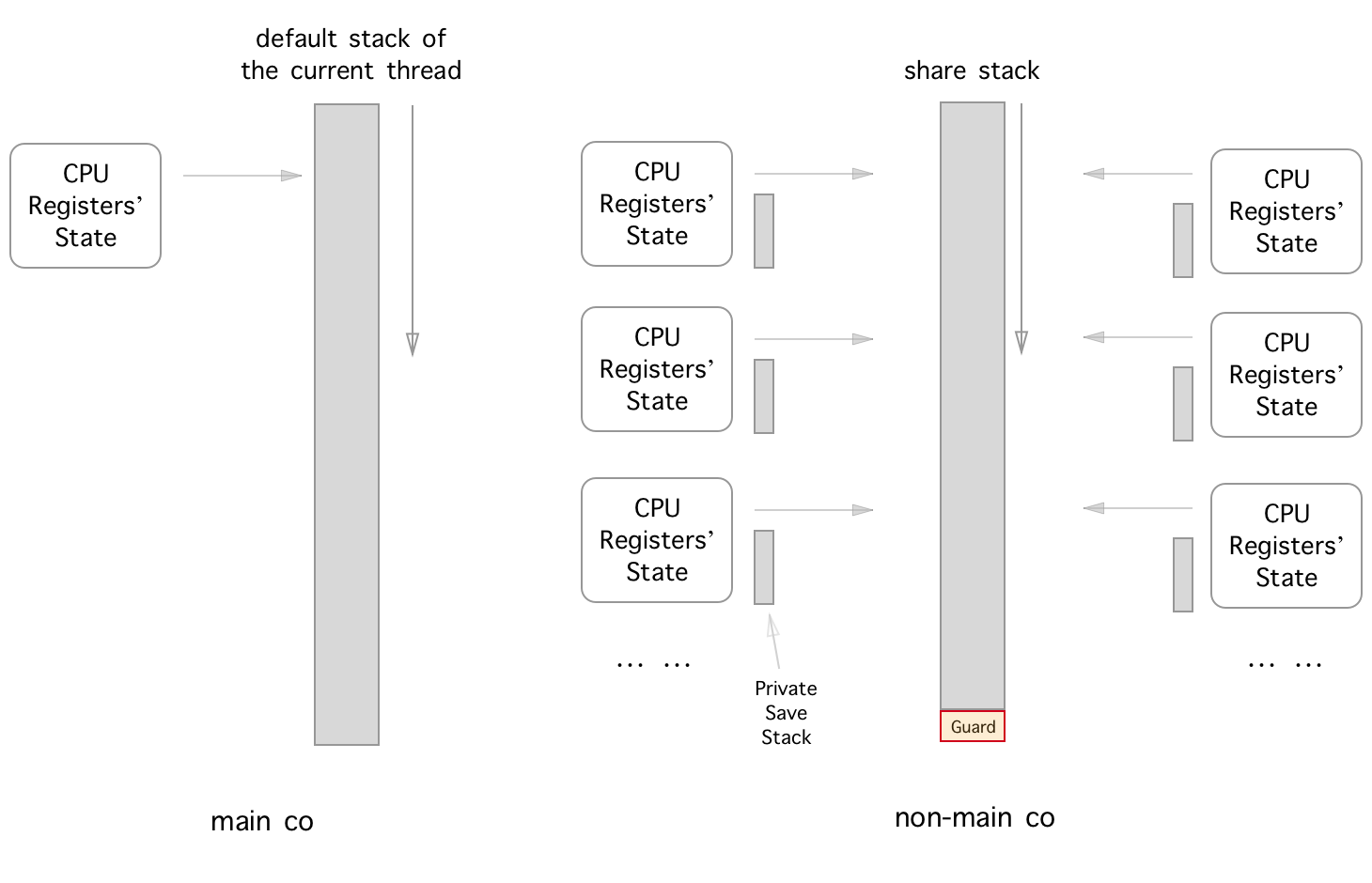
우리는 main co 현재 스레드의 기본 스택을 독점하는 코 루틴으로 정의합니다. 그리고 메인 CO 가이 스택의 유일한 사용자이기 때문에, 우리는 필요한 CPU 레지스터의 메인 CO 상태를 최대/재개 (스위치 아웃/스위치 인)로 만들 때만 저장/복원하면됩니다.
다음으로, non-main co 의 정의는 실행 스택이 현재 스레드의 기본 스택이 아닌 다른 비 메인 CO와 공유 될 수있는 스택 인 코 루틴입니다. 따라서 비 메인 공동은 전환/스위치 인 경우 실행 스택을 저장/복원하기 위해 private save stack 메모리 버퍼가 있어야합니다 (후속/선행 CO가 실행 스택으로 공유 스택을 사용/사용했기 때문에).
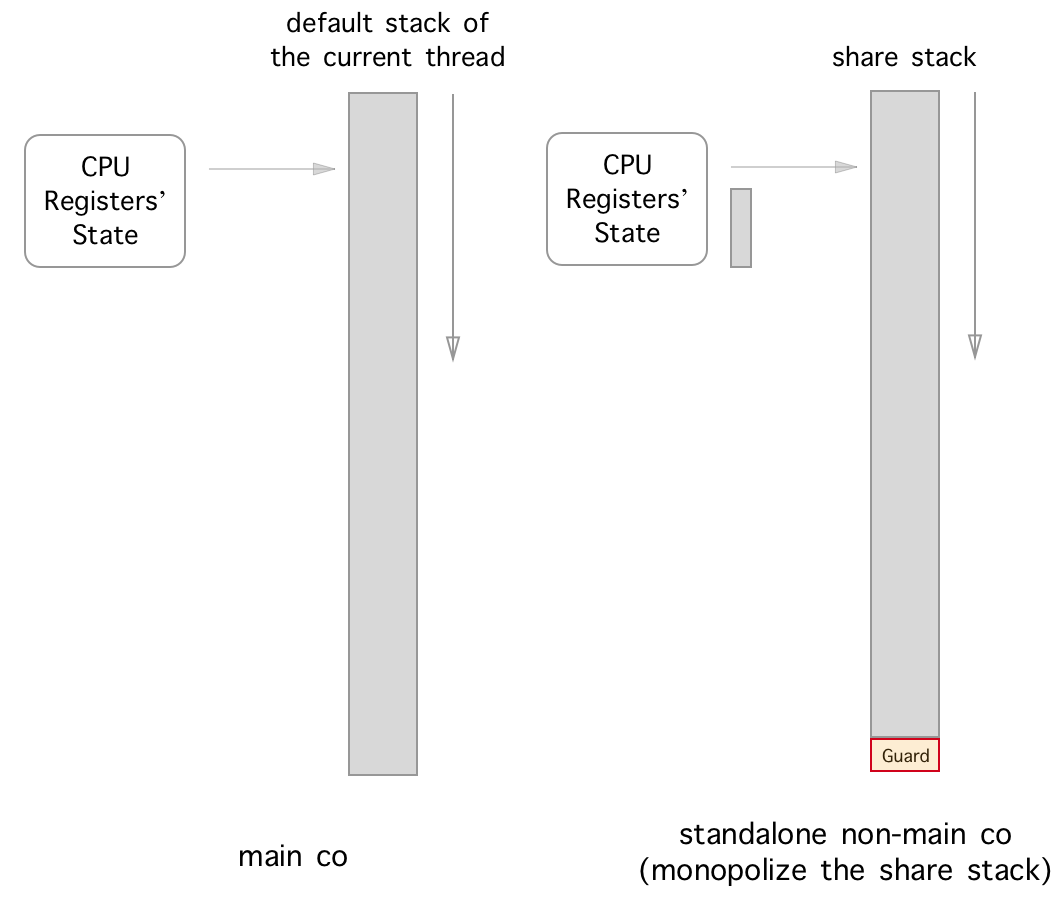
비 메인 공동의 특별한 사례가 있습니다. 즉, 우리가 Libaco에서 호출 한 standalone non-main co 입니다. 비 메인 코 루틴의 공유 스택에는 한 명의 공동 사용자 만 있습니다. 따라서 스위치 아웃/스위치 인 경우 개인 저장 스택의 물건을 저장/복원 할 필요가 없습니다.
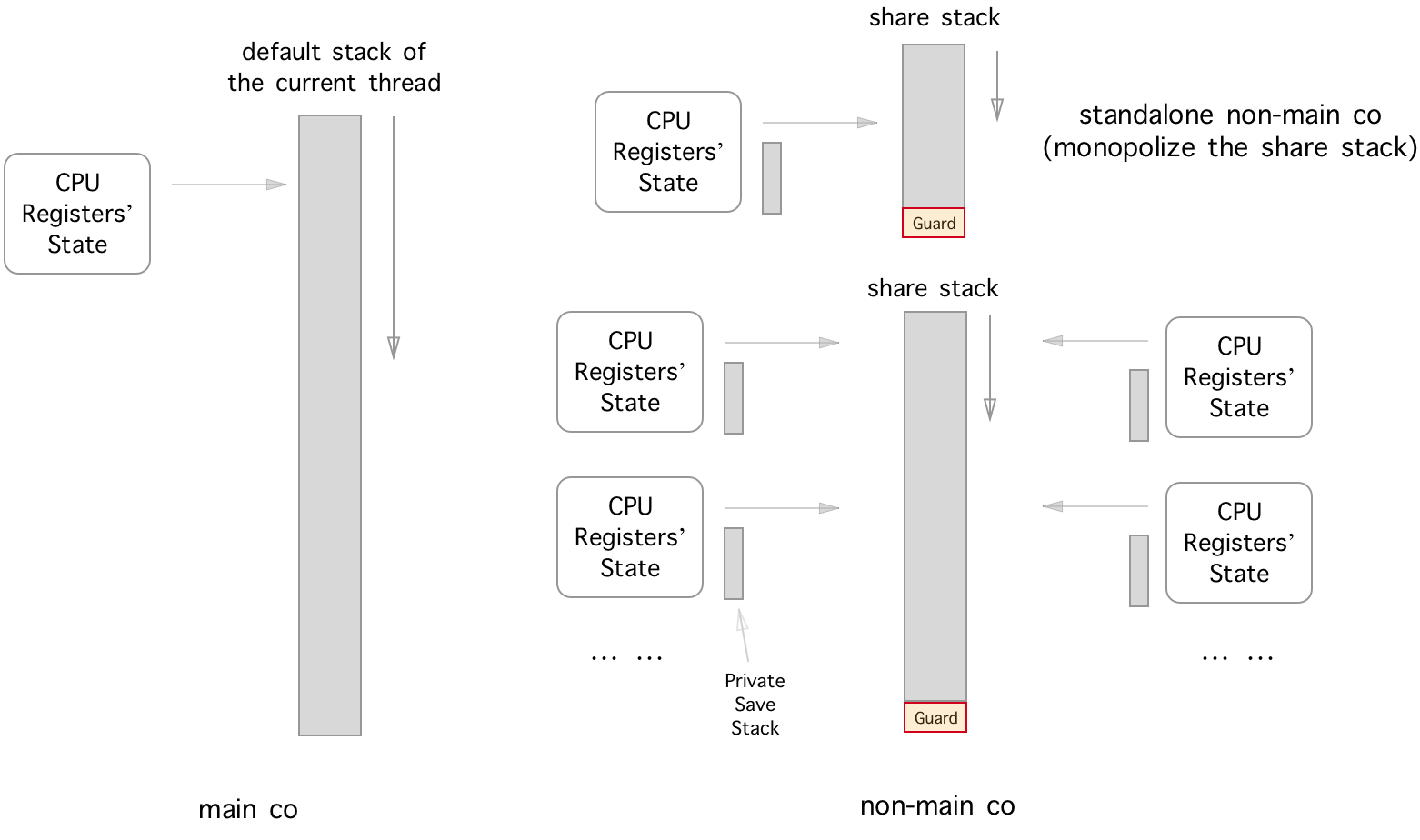
마지막으로, 우리는 Libaco의 큰 그림을 얻습니다.
Libaco의 내부에 뛰어 들거나 자신의 Coroutine 라이브러리를 구현하려는 경우 실제로 도움이 될 수있는 "정확성 증명"부분이 있습니다.
또한 자습서의 소스 코드를 읽고 다음에 벤치 마크를 읽는 것이 좋습니다. 벤치 마크 결과는 매우 인상적이고 깨달았습니다.
-m32 GCC의 -m32 옵션은 X86_64 기계에 Libaco의 i386 적용을 구축하는 데 도움이 될 수 있습니다.
ACO_CONFIG_SHARE_FPU_MXCSR_ENV 코드 중 어느 것도 FPU 및 MXCSR의 제어 단어를 변경하지 않으면 전 세계 C MACRO ACO_CONFIG_SHARE_FPU_MXCSR_ENV 정의 할 수 있습니다. 매크로가 정의되지 않으면 모든 CO는 자체 FPU 및 MXCSR 제어 단어 사본을 유지합니다. 하나의 기능이 ISO C에서 정의한 기본 환경을 사용하는 대신 자체의 특수 ENV의 특수 ENT를 설정 해야하는 것은 매우 드물기 때문에 항상 전역 에서이 매크로를 정의하는 것이 좋습니다. 그러나 확실하지 않은 경우이 매크로를 정의 할 필요는 없습니다.
ACO_USE_VALGRIND Valgrind의 도구 회원을 사용하여 응용 프로그램을 테스트하려면 Libaco에서 Valgrind의 친근한 지원을 가능하게하려면 Global C Macro ACO_USE_VALGRIND 정의해야 할 수도 있습니다. 그러나 성능 이유에 대한 최종 릴리스 빌드 에서이 매크로를 정의하는 것은 권장되지 않습니다. C 매크로 ACO_USE_VALGRIND 정의 된 Libaco 응용 프로그램을 구축하려면 Valgrind 헤더 (패키지 이름은 Centos에 "Valgrind-Devel"입니다)를 설치해야 할 수도 있습니다. (Valgrind의 회고록은 현재 독립형 CO와 잘 작동합니다. 하나 이상의 비 메인 공동에서 사용하는 공유 스택의 경우 Valgrind의 회원은 많은 허위 긍정적 보고서를 생성 할 것입니다. 자세한 내용은 "test_aco_tutorial_6.c"를 참조 할 수 있습니다.).
ACO_USE_ASAN Global C Macro ACO_USE_ASAN Libaco (GCC 및 Clang 지원)에서 주소 소독제의 친근한 지원을 가능하게합니다.
Libaco의 테스트 스위트를 구축하려면 :
$ mkdir output
$ bash make.shmake.sh : 몇 가지 자세한 옵션이 있습니다.
$bash make.sh -h
Usage: make.sh [-o < no-m32 | no-valgrind > ] [-h]
Example:
# default build
bash make.sh
# build without the i386 binary output
bash make.sh -o no-m32
# build without the valgrind supported binary output
bash make.sh -o no-valgrind
# build without the valgrind supported and i386 binary output
bash make.sh -o no-valgrind -o no-m32 요컨대, valgrind 헤더가 설치되지 않은 경우 -o no-valgrind 사용하는 경우 -o no-m32 .
MACOS에서는 MACOS의 기본 sed 및 grep 명령 make.sh GNU sed 및 grep test.sh 교체해야합니다.
$ brew install grep --with-default-names
$ brew install gnu-sed --with-default-names$ cd output
$ bash ../test.sh 이 저장소에서 test_aco_tutorial_0.c 는 libaco의 기본 사용을 보여줍니다. 이 튜토리얼에는 하나의 메인 공동과 독립형 비 메인 공동이 하나뿐입니다. 소스 코드의 의견도 매우 유용합니다.
test_aco_tutorial_1.c 비 메인 공동의 일부 통계 사용을 보여줍니다. aco_t 의 데이터 구조는 매우 명확하며 aco.h 에서 정의됩니다.
test_aco_tutorial_2.c 에는 하나의 메인 공동, 하나의 독립형 비 메인 공동 및 두 개의 비 메인 공동 (동일한 공유 스택을 가리키는)이 있습니다.
test_aco_tutorial_3.c 멀티 스레드 프로세스에서 libaco를 사용하는 방법을 보여줍니다. 기본적으로 Libaco의 한 인스턴스는 하나의 특정 스레드 내에서 작동하도록 설계되어 코 루틴 사이의 컨텍스트 전환의 최대 성능을 얻습니다. 멀티 스레드 환경에서 Libaco를 사용하려면 각 스레드에서 Libaco의 하나의 인스턴스를 작성하십시오. Libaco 내부의 스레드를 가로 질러 데이터 공유가 없으며 여러 스레드 간의 데이터 경쟁을 직접 처리해야합니다 (이 자습서에서 gl_race_aco_yield_ct 가하는 것과 같이).
Libaco의 규칙 중 하나는 Default C Style return 대신 aco_exit() 에게 전화를 걸어 비 메인 CO의 실행을 종료하는 것입니다. 그렇지 않으면 Libaco는 그러한 동작을 불법적으로 취급하고 불쾌한 CO에 대한 오류 정보를 Stderr에 즉시 로그인하고 즉시 프로세스를 중단하는 기본 보호자를 트리거합니다. test_aco_tutorial_4.c 그러한 "불쾌한 공동"상황을 보여줍니다.
또한 자신의 보호자를 정의하여 기본값을 대체 할 수 있습니다 (일부 사용자 정의 된 "마지막 단어"물건을 수행하기 위해). 그러나 어떤 경우에도, 보호자가 처형 된 후에 프로세스가 중단 될 것입니다. test_aco_tutorial_5.c 사용자 정의 된 마지막 단어 함수를 정의하는 방법을 보여줍니다.
마지막 예제는 test_aco_tutorial_6.c 의 간단한 코 루틴 스케줄러입니다.
소스 코드가 명확하고 이해하기 쉽기 때문에 Libaco의 다음 API 설명을 읽을 때 동시에 소스 코드의 해당 API 구현을 동시에 읽는 것이 매우 도움이됩니다. 또한 API 문서를 읽기 전에 모든 튜토리얼을 읽는 것이 좋습니다.
Libaco의 실제 적용을 작성하기 전에 모범 사례 부분을 읽는 것이 좋습니다 (응용 프로그램에서 Libaco의 극단적 인 성능을 진정으로 출시하는 방법에 대해서도 Libaco의 프로그래밍에 대한 통지도 있습니다).
참고 : Libaco의 버전 제어는 Sec : Semantic Versionsing 2.0.0을 따릅니다. 따라서 다음 목록의 API에는 호환성 보장이 있습니다. (목록에 API NO에 대한 그러한 보증은 없습니다.)
typedef void ( * aco_cofuncp_t )( void );
void aco_thread_init ( aco_cofuncp_t last_word_co_fp );현재 스레드에서 Libaco 환경을 초기화합니다.
FPU 및 MXCSR의 현재 제어 단어를 스레드-로컬 글로벌 변수에 저장합니다.
ACO_CONFIG_SHARE_FPU_MXCSR_ENV 정의되지 않으면 저장된 제어 단어는 새로운 CO의 FPU 및 MXCSR ( aco_create 에서)의 제어 단어를 설정하기 위해 참조 값으로 사용되며 각 CO는 나중에 컨텍스트 전환 중에 FPU 및 MXCSR 제어 단어의 자체 사본을 유지합니다.ACO_CONFIG_SHARE_FPU_MXCSR_ENV 가 정의되면 모든 CO는 FPU 및 MXCSR의 동일한 제어 단어를 공유합니다. 이 문서의 "빌드 및 테스트"부분을 참조하여 이에 대한 자세한 내용은 참조 할 수 있습니다. 그리고 "자습서"부분의 test_aco_tutorial_5.c 에서 언급 한 바와 같이, 첫 번째 인수 last_word_co_fp 가 null이 아닌 경우, last_word_co_fp 에 의해 지적 된 함수는 기본 보호기를 대체하여 프로세스가 붕괴되기 전에 "마지막 단어"를 가할 수 있습니다. 이러한 마지막 단어 함수에서 aco_get_co 사용하여 불쾌한 공동의 포인터를 얻을 수 있습니다. 자세한 내용은 test_aco_tutorial_5.c 읽을 수 있습니다.
aco_share_stack_t * aco_share_stack_new ( size_t sz ); aco_share_stack_new2(sz, 1) 와 동일합니다.
aco_share_stack_t * aco_share_stack_new2 ( size_t sz , char guard_page_enabled ); 바이트 인 sz 의 자문 메모리 크기로 새로운 공유 스택을 생성하고 두 번째 Argument guard_page_enabled 에 따라 스택 오버플로 감지에 대한 가드 페이지 (읽기 전용)가있을 수 있습니다.
첫 번째 인수 sz 0과 같은 경우 기본 크기 값 (2MB)을 사용하려면 정렬 및 예약 계산 후이 기능은 다음의 대가로 주식 스택의 최종 유효 길이를 보장합니다.
final_valid_sz >= 4096final_valid_sz >= szfinal_valid_sz % page_size == 0 if the guard_page_enabled != 0 그리고 가능한 한 sz 의 가치에 가깝습니다.
두 번째 Argument guard_page_enabled 의 값이 1 인 경우, 반환의 공유 스택에는 스택 오버 플로우 감지에 대한 하나의 읽기 전용 가드 페이지가 있으며 guard_page_enabled 의 값 0은 그러한 가드 페이지가없는 것을 의미합니다.
이 기능은 항상 유효한 공유 스택을 반환합니다.
void aco_share_stack_destroy ( aco_share_stack_t * sstk ); DEARTORY the Share Stack sstk .
sstk 파괴 할 때 공유 sstk 이있는 모든 CO가 이미 파괴되었는지 확인하십시오.
typedef void ( * aco_cofuncp_t )( void );
aco_t * aco_create ( aco_t * main_co , aco_share_stack_t * share_stack ,
size_t save_stack_sz , aco_cofuncp_t co_fp , void * arg );새 공동을 만듭니다.
생성하려는 main_co라면 전화 : aco_create(NULL, NULL, 0, NULL, NULL) . Main Co는 공유 스택이 기본 스레드 스택 인 특수 독립형 코 루틴입니다. 스레드에서 Main Co는 다른 모든 비 메인 코 루틴 이전에 만들어지고 실행하기 시작한 코 루틴입니다.
그렇지 않으면 생성하려는 비 메인 공동입니다.
main_co 미래의 컨텍스트 전환에서 CO가 aco_yield 의 메인 공동입니다. main_co 무효가되어서는 안됩니다.share_stack 당신이 만들고자하는 비 메인 CO가 향후 실행 스택으로 사용할 공유 스택의 주소입니다. share_stack 무효가되어서는 안됩니다.save_stack_sz 이 CO의 개인 저장 스택의 초기 크기를 지정합니다. 장치는 바이트입니다. 0의 값은 기본 크기 64 바이트를 사용하는 것을 의미합니다. 개인 저장 스택이 다른 CO에 차지하는 공유 스택을 산출해야 할 때 CO의 실행 스택을 유지하기에 충분히 크지 않을 때 자동 크기 조정이 발생합니다. 일반적으로 sz 의 값에 대해 전혀 걱정하지 않아야합니다. 그러나 CO의 막대한 금액 (10,000,000)이 개인 저장 스택을 지속적으로 크기로 크기로 크기로 만들 때 메모리 할당에 약간의 성능에 영향을 미칠 것입니다. 따라서 CO가 실행될 때 co->save_stack.max_cpsz 의 최대 값과 동일한 값으로 save_stack_sz 설정하는 것이 매우 현명하고 강력히 권장됩니다 (이러한 최적화에 대한 최적의 문서를 참조 할 수 있습니다).co_fp 는 CO의 입력 기능 포인터입니다. co_fp null이되어서는 안됩니다.arg 는 포인터 값이며 CO의 co->arg 로 설정 될 것입니다. CO의 입력 인수로 사용될 수 있습니다.이 기능은 항상 유효한 CO를 반환합니다. 그리고 우리는 그것이 당신이 만들고자하는 비 메인 CO라면 CO의 상태를 "init"로 지명합니다.
void aco_resume ( aco_t * co ); 발신자 Main Co의 양보하고 co 의 실행을 시작하거나 계속합니다.
이 기능의 발신자는 메인 공동이어야하며 co->main_co 여야합니다. 그리고 첫 번째 인수 co 비 메인 공동이어야합니다.
co 처음으로 재개 할 때 co->fp 가 가리키는 함수를 실행하기 시작합니다. co 이미 산출 된 경우 aco_resume 다시 시작하여 실행을 계속합니다.
aco_resume 의 호출 후, 우리는 발신자 - 메인 공동의 상태를 "수율"으로 지명합니다.
void aco_yield (); co 의 실행을 생산하고 co->main_co 재개하십시오. 이 기능의 발신자는 비 메인 공동이어야합니다. 그리고 co->main_co 무효가되어서는 안됩니다.
aco_yield 의 호출 후, 우리는 발신자의 상태를 " co "으로 지명합니다.
aco_t * aco_get_co ();현재 비 메인 공동의 포인터를 반환하십시오. 이 기능의 발신자는 비 메인 공동이어야합니다.
void * aco_get_arg (); (aco_get_co()->arg) 과 동일합니다. 또한이 기능의 발신자는 비 메인 공동이어야합니다.
void aco_exit (); 또한 aco_yield() 와 동일하게 수행하고 aco_exit() 도 co->is_end 1로 설정하여 "END"의 상태로 co 표시합니다.
void aco_destroy ( aco_t * co ); co 파괴하십시오. 인수 co 무효가되어서는 안됩니다. co 비 메인 CO 인 경우 개인 저장 스택도 파괴되었습니다.
#define ACO_VERSION_MAJOR 1
#define ACO_VERSION_MINOR 2
#define ACO_VERSION_PATCH 4 이 3 개의 매크로는 헤더 aco.h 에 정의되며 그 값은 사양을 따릅니다 : 시맨틱 버전 2.0.0.
// provide the compiler with branch prediction information
#define likely ( x ) aco_likely(x)
#define unlikely ( x ) aco_unlikely(x)
// override the default `assert` for convenience when coding
#define assert ( EX ) aco_assert(EX)
// equal to `assert((ptr) != NULL)`
#define assertptr ( ptr ) aco_assertptr(ptr)
// assert the successful return of memory allocation
#define assertalloc_bool ( b ) aco_assertalloc_bool(b)
#define assertalloc_ptr ( ptr ) aco_assertalloc_ptr(ptr) test_aco_synopsis.c와 같은 Libaco 응용 프로그램에서 기본 C "Assert"를 무시하기 위해 "aco_assert_override.h" 를 포함하도록 선택할 수 있습니다 (C "Assert"도 C MACRO 정의이기 때문에 소스 파일의 마지막 지침 목록에 있어야합니다). 기본 C "Assert"를 사용하려면 응용 프로그램 소스 파일 에이 헤더를 포함시키지 마십시오.
자세한 내용은 소스 파일 ACO_ASSERT_OVERRIDE.H를 참조하십시오.
날짜 : Sat Jun 30 UTC 2018.
기계 : C5D. AWS의 LARGE.
OS : Rhel-7.5 (Red Hat Enterprise Linux 7.5).
다음은 벤치 마크 부분에 대한 간단한 요약입니다.
$ LD_PRELOAD=/usr/lib64/libtcmalloc_minimal.so.4 ./test_aco_benchmark..no_valgrind.shareFPUenv
+build:x86_64
+build:-DACO_CONFIG_SHARE_FPU_MXCSR_ENV
+build:share fpu & mxcsr control words between coroutines
+build:undefined ACO_USE_VALGRIND
+build:without valgrind memcheck friendly support
sizeof(aco_t)=152:
comment task_amount all_time_cost ns_per_op speed
aco_create/init_save_stk_sz=64B 1 0.000 s 230.00 ns/op 4347824.79 op/s
aco_resume/co_amount=1/copy_stack_size=0B 20000000 0.412 s 20.59 ns/op 48576413.55 op/s
-> acosw 40000000 0.412 s 10.29 ns/op 97152827.10 op/s
aco_destroy 1 0.000 s 650.00 ns/op 1538461.66 op/s
aco_create/init_save_stk_sz=64B 1 0.000 s 200.00 ns/op 5000001.72 op/s
aco_resume/co_amount=1/copy_stack_size=0B 20000000 0.412 s 20.61 ns/op 48525164.25 op/s
-> acosw 40000000 0.412 s 10.30 ns/op 97050328.50 op/s
aco_destroy 1 0.000 s 666.00 ns/op 1501501.49 op/s
aco_create/init_save_stk_sz=64B 2000000 0.131 s 65.50 ns/op 15266771.53 op/s
aco_resume/co_amount=2000000/copy_stack_size=8B 20000000 0.666 s 33.29 ns/op 30043022.64 op/s
aco_destroy 2000000 0.066 s 32.87 ns/op 30425152.25 op/s
aco_create/init_save_stk_sz=64B 2000000 0.130 s 65.22 ns/op 15332218.24 op/s
aco_resume/co_amount=2000000/copy_stack_size=24B 20000000 0.675 s 33.75 ns/op 29630018.73 op/s
aco_destroy 2000000 0.067 s 33.45 ns/op 29898311.36 op/s
aco_create/init_save_stk_sz=64B 2000000 0.131 s 65.42 ns/op 15286937.97 op/s
aco_resume/co_amount=2000000/copy_stack_size=40B 20000000 0.669 s 33.45 ns/op 29891277.59 op/s
aco_destroy 2000000 0.080 s 39.87 ns/op 25084242.29 op/s
aco_create/init_save_stk_sz=64B 2000000 0.224 s 111.86 ns/op 8940010.49 op/s
aco_resume/co_amount=2000000/copy_stack_size=56B 20000000 0.678 s 33.88 ns/op 29515473.53 op/s
aco_destroy 2000000 0.067 s 33.42 ns/op 29922412.68 op/s
aco_create/init_save_stk_sz=64B 2000000 0.131 s 65.74 ns/op 15211896.70 op/s
aco_resume/co_amount=2000000/copy_stack_size=120B 20000000 0.769 s 38.45 ns/op 26010724.94 op/s
aco_destroy 2000000 0.088 s 44.11 ns/op 22669240.25 op/s
aco_create/init_save_stk_sz=64B 10000000 1.240 s 123.97 ns/op 8066542.54 op/s
aco_resume/co_amount=10000000/copy_stack_size=8B 40000000 1.327 s 33.17 ns/op 30143409.55 op/s
aco_destroy 10000000 0.328 s 32.82 ns/op 30467658.05 op/s
aco_create/init_save_stk_sz=64B 10000000 0.659 s 65.94 ns/op 15165717.02 op/s
aco_resume/co_amount=10000000/copy_stack_size=24B 40000000 1.345 s 33.63 ns/op 29737708.53 op/s
aco_destroy 10000000 0.337 s 33.71 ns/op 29666697.09 op/s
aco_create/init_save_stk_sz=64B 10000000 0.654 s 65.38 ns/op 15296191.35 op/s
aco_resume/co_amount=10000000/copy_stack_size=40B 40000000 1.348 s 33.71 ns/op 29663992.77 op/s
aco_destroy 10000000 0.336 s 33.56 ns/op 29794574.96 op/s
aco_create/init_save_stk_sz=64B 10000000 0.653 s 65.29 ns/op 15316087.09 op/s
aco_resume/co_amount=10000000/copy_stack_size=56B 40000000 1.384 s 34.60 ns/op 28902221.24 op/s
aco_destroy 10000000 0.337 s 33.73 ns/op 29643682.93 op/s
aco_create/init_save_stk_sz=64B 10000000 0.652 s 65.19 ns/op 15340872.40 op/s
aco_resume/co_amount=10000000/copy_stack_size=120B 40000000 1.565 s 39.11 ns/op 25566255.73 op/s
aco_destroy 10000000 0.443 s 44.30 ns/op 22574242.55 op/s
aco_create/init_save_stk_sz=64B 2000000 0.131 s 65.61 ns/op 15241722.94 op/s
aco_resume/co_amount=2000000/copy_stack_size=136B 20000000 0.947 s 47.36 ns/op 21114212.05 op/s
aco_destroy 2000000 0.125 s 62.35 ns/op 16039466.45 op/s
aco_create/init_save_stk_sz=64B 2000000 0.131 s 65.71 ns/op 15218784.72 op/s
aco_resume/co_amount=2000000/copy_stack_size=136B 20000000 0.948 s 47.39 ns/op 21101216.29 op/s
aco_destroy 2000000 0.125 s 62.73 ns/op 15941559.26 op/s
aco_create/init_save_stk_sz=64B 2000000 0.131 s 65.49 ns/op 15270258.18 op/s
aco_resume/co_amount=2000000/copy_stack_size=152B 20000000 1.069 s 53.44 ns/op 18714275.17 op/s
aco_destroy 2000000 0.122 s 61.05 ns/op 16378678.85 op/s
aco_create/init_save_stk_sz=64B 2000000 0.132 s 65.91 ns/op 15171336.62 op/s
aco_resume/co_amount=2000000/copy_stack_size=232B 20000000 1.190 s 59.48 ns/op 16813230.99 op/s
aco_destroy 2000000 0.123 s 61.26 ns/op 16324298.25 op/s
aco_create/init_save_stk_sz=64B 2000000 0.131 s 65.68 ns/op 15224361.30 op/s
aco_resume/co_amount=2000000/copy_stack_size=488B 20000000 1.828 s 91.40 ns/op 10941133.56 op/s
aco_destroy 2000000 0.145 s 72.56 ns/op 13781182.82 op/s
aco_create/init_save_stk_sz=64B 2000000 0.132 s 65.80 ns/op 15197461.34 op/s
aco_resume/co_amount=2000000/copy_stack_size=488B 20000000 1.829 s 91.47 ns/op 10932139.32 op/s
aco_destroy 2000000 0.149 s 74.70 ns/op 13387258.82 op/s
aco_create/init_save_stk_sz=64B 1000000 0.067 s 66.63 ns/op 15007426.35 op/s
aco_resume/co_amount=1000000/copy_stack_size=1000B 20000000 4.224 s 211.20 ns/op 4734744.76 op/s
aco_destroy 1000000 0.093 s 93.36 ns/op 10711651.49 op/s
aco_create/init_save_stk_sz=64B 1000000 0.066 s 66.28 ns/op 15086953.73 op/s
aco_resume/co_amount=1000000/copy_stack_size=1000B 20000000 4.222 s 211.12 ns/op 4736537.93 op/s
aco_destroy 1000000 0.094 s 94.09 ns/op 10627664.78 op/s
aco_create/init_save_stk_sz=64B 100000 0.007 s 70.72 ns/op 14139923.59 op/s
aco_resume/co_amount=100000/copy_stack_size=1000B 20000000 4.191 s 209.56 ns/op 4771909.70 op/s
aco_destroy 100000 0.010 s 101.21 ns/op 9880747.28 op/s
aco_create/init_save_stk_sz=64B 100000 0.007 s 66.62 ns/op 15010433.00 op/s
aco_resume/co_amount=100000/copy_stack_size=2024B 20000000 7.002 s 350.11 ns/op 2856228.03 op/s
aco_destroy 100000 0.016 s 159.69 ns/op 6262129.35 op/s
aco_create/init_save_stk_sz=64B 100000 0.007 s 65.76 ns/op 15205994.08 op/s
aco_resume/co_amount=100000/copy_stack_size=4072B 20000000 11.918 s 595.90 ns/op 1678127.54 op/s
aco_destroy 100000 0.019 s 186.32 ns/op 5367189.85 op/s
aco_create/init_save_stk_sz=64B 100000 0.006 s 63.03 ns/op 15865531.37 op/s
aco_resume/co_amount=100000/copy_stack_size=7992B 20000000 21.808 s 1090.42 ns/op 917079.11 op/s
aco_destroy 100000 0.038 s 378.33 ns/op 2643225.42 op/s
$ LD_PRELOAD=/usr/lib64/libtcmalloc_minimal.so.4 ./test_aco_benchmark..no_valgrind.standaloneFPUenv
+build:x86_64
+build:undefined ACO_CONFIG_SHARE_FPU_MXCSR_ENV
+build:each coroutine maintain each own fpu & mxcsr control words
+build:undefined ACO_USE_VALGRIND
+build:without valgrind memcheck friendly support
sizeof(aco_t)=160:
comment task_amount all_time_cost ns_per_op speed
aco_create/init_save_stk_sz=64B 1 0.000 s 273.00 ns/op 3663004.27 op/s
aco_resume/co_amount=1/copy_stack_size=0B 20000000 0.415 s 20.76 ns/op 48173877.75 op/s
-> acosw 40000000 0.415 s 10.38 ns/op 96347755.51 op/s
aco_destroy 1 0.000 s 381.00 ns/op 2624672.26 op/s
aco_create/init_save_stk_sz=64B 1 0.000 s 212.00 ns/op 4716980.43 op/s
aco_resume/co_amount=1/copy_stack_size=0B 20000000 0.415 s 20.75 ns/op 48185455.26 op/s
-> acosw 40000000 0.415 s 10.38 ns/op 96370910.51 op/s
aco_destroy 1 0.000 s 174.00 ns/op 5747123.38 op/s
aco_create/init_save_stk_sz=64B 2000000 0.131 s 65.63 ns/op 15237386.02 op/s
aco_resume/co_amount=2000000/copy_stack_size=8B 20000000 0.664 s 33.20 ns/op 30119155.82 op/s
aco_destroy 2000000 0.065 s 32.67 ns/op 30604542.55 op/s
aco_create/init_save_stk_sz=64B 2000000 0.131 s 65.33 ns/op 15305975.29 op/s
aco_resume/co_amount=2000000/copy_stack_size=24B 20000000 0.675 s 33.74 ns/op 29638360.61 op/s
aco_destroy 2000000 0.067 s 33.31 ns/op 30016633.42 op/s
aco_create/init_save_stk_sz=64B 2000000 0.131 s 65.61 ns/op 15241767.78 op/s
aco_resume/co_amount=2000000/copy_stack_size=40B 20000000 0.678 s 33.88 ns/op 29518648.08 op/s
aco_destroy 2000000 0.079 s 39.74 ns/op 25163018.30 op/s
aco_create/init_save_stk_sz=64B 2000000 0.221 s 110.73 ns/op 9030660.30 op/s
aco_resume/co_amount=2000000/copy_stack_size=56B 20000000 0.684 s 34.18 ns/op 29253416.65 op/s
aco_destroy 2000000 0.067 s 33.40 ns/op 29938840.64 op/s
aco_create/init_save_stk_sz=64B 2000000 0.131 s 65.60 ns/op 15244077.65 op/s
aco_resume/co_amount=2000000/copy_stack_size=120B 20000000 0.769 s 38.43 ns/op 26021228.41 op/s
aco_destroy 2000000 0.087 s 43.74 ns/op 22863987.42 op/s
aco_create/init_save_stk_sz=64B 10000000 1.251 s 125.08 ns/op 7994958.59 op/s
aco_resume/co_amount=10000000/copy_stack_size=8B 40000000 1.327 s 33.19 ns/op 30133654.80 op/s
aco_destroy 10000000 0.329 s 32.85 ns/op 30439787.32 op/s
aco_create/init_save_stk_sz=64B 10000000 0.674 s 67.37 ns/op 14843796.57 op/s
aco_resume/co_amount=10000000/copy_stack_size=24B 40000000 1.354 s 33.84 ns/op 29548523.05 op/s
aco_destroy 10000000 0.339 s 33.90 ns/op 29494634.83 op/s
aco_create/init_save_stk_sz=64B 10000000 0.672 s 67.19 ns/op 14882262.88 op/s
aco_resume/co_amount=10000000/copy_stack_size=40B 40000000 1.361 s 34.02 ns/op 29393520.19 op/s
aco_destroy 10000000 0.338 s 33.77 ns/op 29609577.59 op/s
aco_create/init_save_stk_sz=64B 10000000 0.673 s 67.31 ns/op 14857716.02 op/s
aco_resume/co_amount=10000000/copy_stack_size=56B 40000000 1.371 s 34.27 ns/op 29181897.80 op/s
aco_destroy 10000000 0.339 s 33.85 ns/op 29540633.63 op/s
aco_create/init_save_stk_sz=64B 10000000 0.672 s 67.24 ns/op 14873017.10 op/s
aco_resume/co_amount=10000000/copy_stack_size=120B 40000000 1.548 s 38.71 ns/op 25835542.17 op/s
aco_destroy 10000000 0.446 s 44.61 ns/op 22415961.64 op/s
aco_create/init_save_stk_sz=64B 2000000 0.132 s 66.01 ns/op 15148290.52 op/s
aco_resume/co_amount=2000000/copy_stack_size=136B 20000000 0.944 s 47.22 ns/op 21177946.19 op/s
aco_destroy 2000000 0.124 s 61.99 ns/op 16132721.97 op/s
aco_create/init_save_stk_sz=64B 2000000 0.133 s 66.36 ns/op 15068860.85 op/s
aco_resume/co_amount=2000000/copy_stack_size=136B 20000000 0.944 s 47.20 ns/op 21187541.38 op/s
aco_destroy 2000000 0.124 s 62.21 ns/op 16073322.25 op/s
aco_create/init_save_stk_sz=64B 2000000 0.131 s 65.62 ns/op 15238955.93 op/s
aco_resume/co_amount=2000000/copy_stack_size=152B 20000000 1.072 s 53.61 ns/op 18652789.74 op/s
aco_destroy 2000000 0.121 s 60.42 ns/op 16551368.04 op/s
aco_create/init_save_stk_sz=64B 2000000 0.132 s 66.08 ns/op 15132547.65 op/s
aco_resume/co_amount=2000000/copy_stack_size=232B 20000000 1.198 s 59.88 ns/op 16699389.91 op/s
aco_destroy 2000000 0.121 s 60.71 ns/op 16471465.52 op/s
aco_create/init_save_stk_sz=64B 2000000 0.133 s 66.50 ns/op 15036985.95 op/s
aco_resume/co_amount=2000000/copy_stack_size=488B 20000000 1.853 s 92.63 ns/op 10796126.04 op/s
aco_destroy 2000000 0.146 s 72.87 ns/op 13723559.36 op/s
aco_create/init_save_stk_sz=64B 2000000 0.132 s 66.14 ns/op 15118324.13 op/s
aco_resume/co_amount=2000000/copy_stack_size=488B 20000000 1.855 s 92.75 ns/op 10781572.22 op/s
aco_destroy 2000000 0.152 s 75.79 ns/op 13194130.51 op/s
aco_create/init_save_stk_sz=64B 1000000 0.067 s 66.97 ns/op 14931921.56 op/s
aco_resume/co_amount=1000000/copy_stack_size=1000B 20000000 4.218 s 210.90 ns/op 4741536.66 op/s
aco_destroy 1000000 0.093 s 93.16 ns/op 10734691.98 op/s
aco_create/init_save_stk_sz=64B 1000000 0.066 s 66.49 ns/op 15039274.31 op/s
aco_resume/co_amount=1000000/copy_stack_size=1000B 20000000 4.216 s 210.81 ns/op 4743543.53 op/s
aco_destroy 1000000 0.094 s 93.97 ns/op 10641539.58 op/s
aco_create/init_save_stk_sz=64B 100000 0.007 s 70.95 ns/op 14094724.73 op/s
aco_resume/co_amount=100000/copy_stack_size=1000B 20000000 4.190 s 209.52 ns/op 4772746.50 op/s
aco_destroy 100000 0.010 s 100.99 ns/op 9902271.51 op/s
aco_create/init_save_stk_sz=64B 100000 0.007 s 66.49 ns/op 15040038.84 op/s
aco_resume/co_amount=100000/copy_stack_size=2024B 20000000 7.028 s 351.38 ns/op 2845942.55 op/s
aco_destroy 100000 0.016 s 159.15 ns/op 6283444.42 op/s
aco_create/init_save_stk_sz=64B 100000 0.007 s 65.73 ns/op 15214482.36 op/s
aco_resume/co_amount=100000/copy_stack_size=4072B 20000000 11.879 s 593.95 ns/op 1683636.60 op/s
aco_destroy 100000 0.018 s 184.23 ns/op 5428119.00 op/s
aco_create/init_save_stk_sz=64B 100000 0.006 s 63.41 ns/op 15771072.16 op/s
aco_resume/co_amount=100000/copy_stack_size=7992B 20000000 21.808 s 1090.42 ns/op 917081.56 op/s
aco_destroy 100000 0.038 s 376.78 ns/op 2654073.13 op/s
코 루틴 라이브러리를 구현하거나 증명하기 전에 Intel386 및 X86-64의 SYS v ABI의 표준에 매우 익숙해야합니다.
아래 증거에는 IP (명령 포인터), SP (스택 포인터) 및 개인 저장 스택과 공유 스택 간 저축/복원에 대한 직접적인 설명이 없습니다. 이러한 것들은 ABI 제약 조건과 비교할 때 매우 사소하고 이해하기 쉽기 때문입니다.
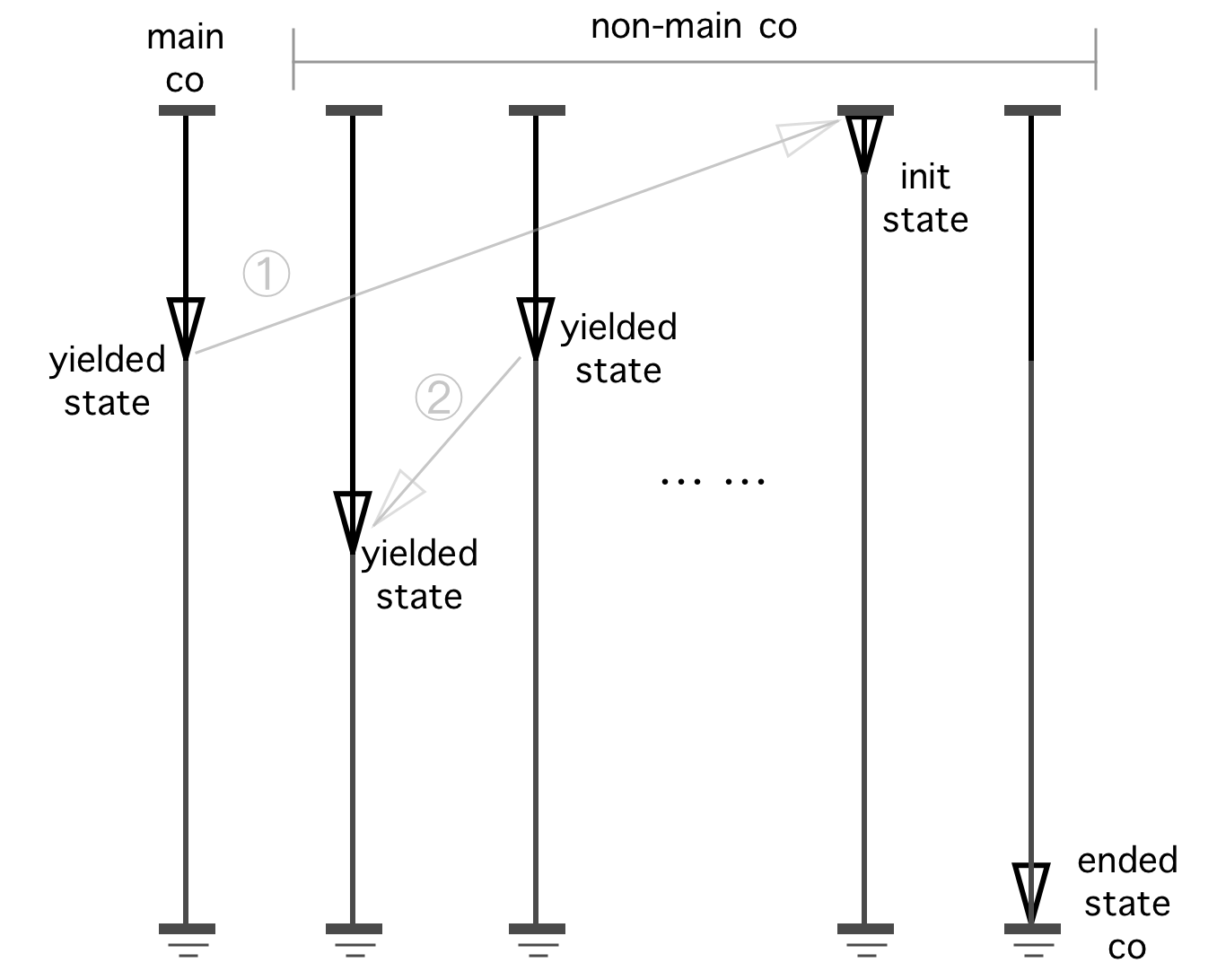
OS 스레드에서 메인 코 루틴 main_co 다른 모든 비 메인 코 루틴이하기 전에 먼저 생성되고 실행되기 시작한 코 루틴입니다.
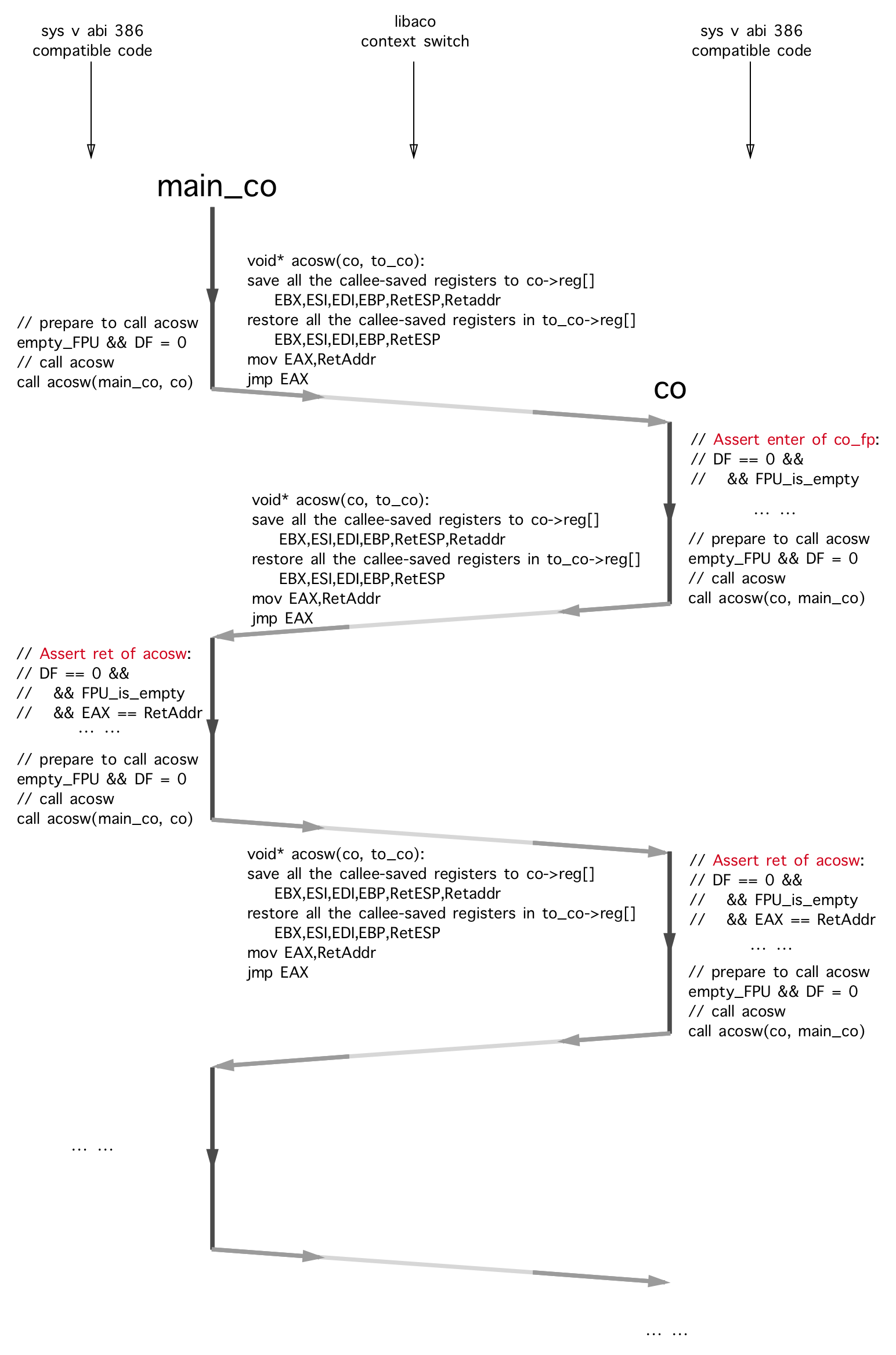
다음 다이어그램은 main_co와 co 사이의 컨텍스트 전환의 간단한 예입니다.
이 증거에서, 우리는 Intel386의 Sys v Abi와 x86-64 사이에 근본적인 차이가 없기 때문에 Intel386의 Sys v ABI에 있다고 가정합니다. 또한 코드 중 어느 것도 FPU 및 MXCSR의 제어 단어를 변경하지 않을 것이라고 가정합니다.
다음 다이어그램은 실제로 비 메인 공동 S와 하나의 메인 공동으로 무제한 수의 대칭 코 루틴의 실행 모델입니다. 비대칭 코 루틴은 대칭 코 루틴의 특별한 경우이기 때문에 괜찮습니다. 대칭 코 루틴의 정확성을 증명하는 것은 비대칭 코 루틴보다 조금 더 어려워서 더 재미있을 것입니다. (Libaco는 비대칭 코 루틴 API의 의미 론적 의미가 대칭 코 루틴보다 이해하고 사용하기가 훨씬 쉽기 때문에 현재 비대칭 코 루틴의 API 만 구현했습니다.)
메인 CO co 첫 번째 코 루틴이 실행되기 시작 하므로이 OS 스레드의 첫 번째 컨텍스트 전환은 acosw(main_co, co) 형태이어야합니다.
위의 다이어그램에는 두 종류의 상태 전송 만 존재한다는 것을 쉽게 증명할 수 있습니다.
void* acosw(aco_t* from_co, aco_t* to_co) 의 정확성을 증명하기 위해 구현은 acosw 의 호출 전후에 SYS v ABI의 제약 조건을 지속적으로 준수하는 것을 증명하는 것과 같습니다. CO의 이진 코드 ( acosw 제외)의 다른 부분이 이미 ABI를 준수했다고 가정합니다 (일반적으로 컴파일러에 의해 올바르게 생성됨).
다음은 Intel386 SYS V ABI의 기능 호출 협약에서 레지스터의 제약 조건에 대한 요약입니다.
Registers' usage in the calling convention of the Intel386 System V ABI:
caller saved (scratch) registers:
C1.0: EAX
At the entry of a function call:
could be any value
After the return of `acosw`:
hold the return value for `acosw`
C1.1: ECX,EDX
At the entry of a function call:
could be any value
After the return of `acosw`:
could be any value
C1.2: Arithmetic flags, x87 and mxcsr flags
At the entry of a function call:
could be any value
After the return of `acosw`:
could be any value
C1.3: ST(0-7)
At the entry of a function call:
the stack of FPU must be empty
After the return of `acosw`:
the stack of FPU must be empty
C1.4: Direction flag
At the entry of a function call:
DF must be 0
After the return of `acosw`:
DF must be 0
C1.5: others: xmm*,ymm*,mm*,k*...
At the entry of a function call:
could be any value
After the return of `acosw`:
could be any value
callee saved registers:
C2.0: EBX,ESI,EDI,EBP
At the entry of a function call:
could be any value
After the return of `acosw`:
must be the same as it is at the entry of `acosw`
C2.1: ESP
At the entry of a function call:
must be a valid stack pointer
(alignment of 16 bytes, retaddr and etc...)
After the return of `acosw`:
must be the same as it is before the call of `acosw`
C2.2: control word of FPU & mxcsr
At the entry of a function call:
could be any configuration
After the return of `acosw`:
must be the same as it is before the call of `acosw`
(unless the caller of `acosw` assume `acosw` may
change the control words of FPU or MXCSR on purpose
like `fesetenv`)
(Intel386의 경우 레지스터 사용량은 SYS v ABI Intel386 V1.1의 "P13- 표 2.3 : 레지스터 사용"에 정의되어 있으며 AMD64의 경우 "P23- 그림 3.4 : Sys v ABI AMD64 V1.0의 레지스터"에 있습니다).
증거:

위의 다이어그램은 첫 번째 사례입니다.
제약 조건 : C 1.0, 1.1, 1.2, 1.5 ( 만족 ✓)
아래 스크래치 레지스터는 함수를 입력 할 때 모든 값을 보유 할 수 있습니다.
EAX,ECX,EDX
XMM*,YMM*,MM*,K*...
status bits of EFLAGS,FPU,MXCSR
제약 조건 : C 1.3, 1.4 ( 만족 ✓)
FPU의 스택은 이미 비어 있어야하고 DF는 acosw(co, to_co) 호출되기 전에 이미 0이어야하므로 (CO의 이진 코드는 이미 ABI에 준수됨), 제약 1.3 및 1.4는 acosw 에 의해 준수됩니다.
제약 조건 : C 2.0, 2.1, 2.2 ( 만족 ✓)
C 2.0 & 2.1은 이미 만족 스럽습니다. 우리는 이미 아무도 FPU 및 MXCSR의 제어 단어를 변경하지 않을 것이라고 가정 했으므로 C 2.2도 만족합니다.
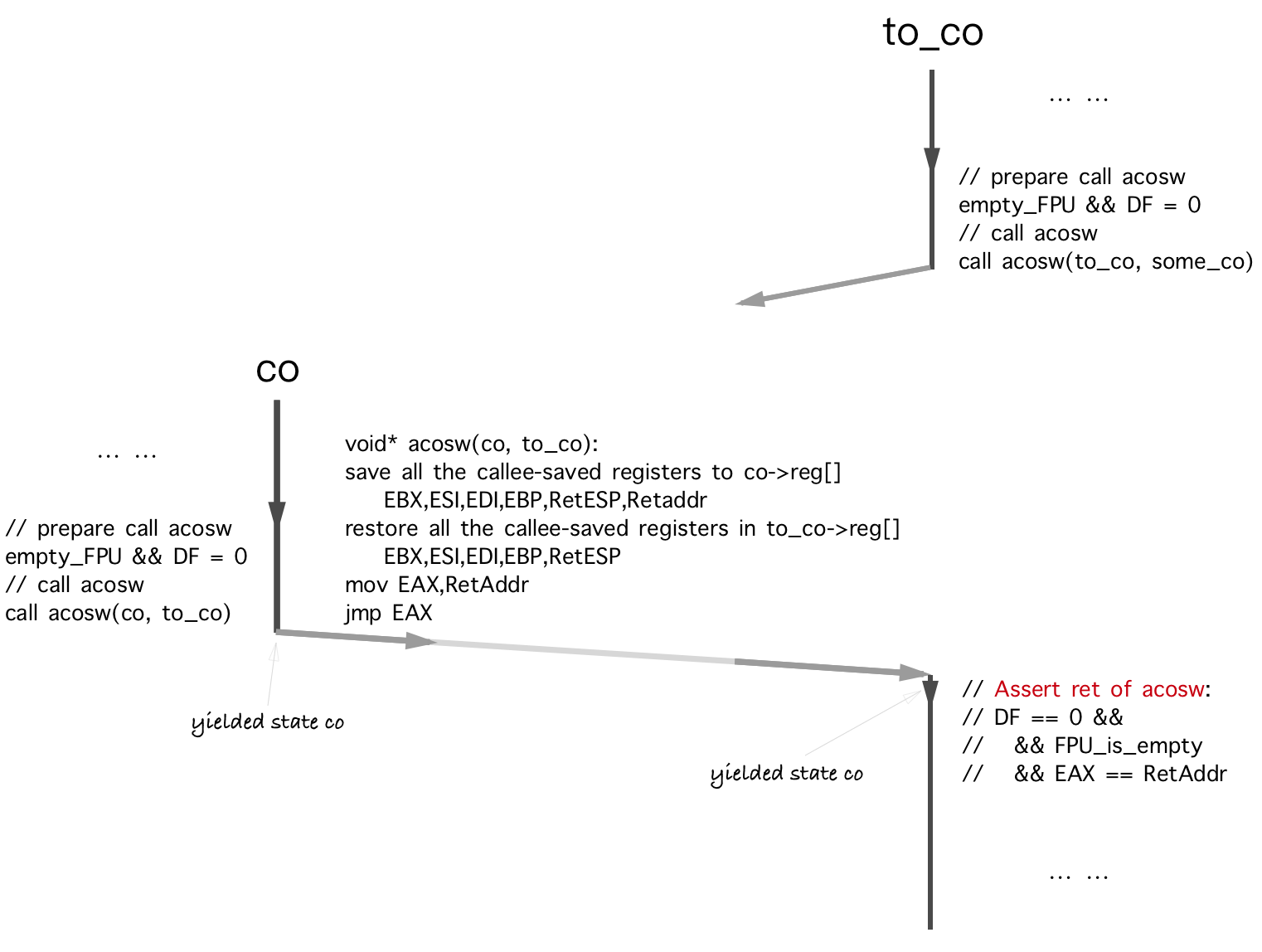
위의 다이어그램은 두 번째 사례에 대한 것입니다.
제약 조건 : C 1.0 ( 만족 ✓)
acosw TO_CO (이력서)로 돌아올 때 이미 반환 값을 보유하고 있습니다.
제약 조건 : C 1.1, 1.2, 1.5 ( 만족 ✓)
아래 스크래치 레지스터는 함수의 입력시 및 acosw 의 반환 후 값을 보유 할 수 있습니다.
ECX,EDX
XMM*,YMM*,MM*,K*...
status bits of EFLAGS,FPU,MXCSR
제약 조건 : C 1.3, 1.4 ( 만족 ✓)
FPU의 스택은 이미 비어 있어야하고 DF는 acosw(co, to_co) 호출되기 전에 이미 0이어야하므로 (CO의 이진 코드는 이미 ABI에 준수됨), 제약 1.3 및 1.4는 acosw 에 의해 준수됩니다.
제약 조건 : C 2.0, 2.1, 2.2 ( 만족 ✓)
C 2.0 & 2.1은 acosw 호출/반품 될 때 Callee 저장 레지스터의 저장 및 복원이 있기 때문에 충족됩니다. 우리는 이미 아무도 FPU 및 MXCSR의 제어 단어를 변경하지 않을 것이라고 가정 했으므로 C 2.2도 만족합니다.
스레드의 첫 번째 acosw 첫 번째 사례 여야합니다. STATE CO-> Init State Co를 생산하고 다음 acosw 위의 2 건 중 하나 여야합니다. 순차적으로, 우리는 "모든 CO가 acosw 호출 전후에 SYS v ABI의 제약을 지속적으로 준수한다"는 것을 증명할 수있다. 따라서 증거가 완료되었습니다.
System v ABI X86-64에는 Red Zone이라는 새로운 것이 있습니다.
%RSP가 지적 된 위치를 넘어서 128 바이트 영역은 예약 된 것으로 간주되며 신호 또는 인터럽트 핸들러에 의해 수정되지 않아야합니다. 따라서 함수는 기능 호출에 걸쳐 필요하지 않은 임시 데이터 에이 영역을 사용할 수 있습니다. 특히, 잎 함수는 프롤로그와 에필로그에서 스택 포인터를 조정하는 대신 전체 스택 프레임 에이 영역을 사용할 수 있습니다. 이 지역은 빨간색 영역으로 알려져 있습니다.
빨간색은 "칼리에 의해 보존되지"않기 때문에, 우리는 코 루틴 사이의 컨텍스트 전환에서 전혀 신경 쓰지 않습니다 ( acosw 는 잎 함수이기 때문에).
입력 인수 영역의 끝은 __M256 또는 __M512가 스택에 전달되는 경우 16 (32 또는 64, 32 또는 64,) 바이트 경계에 정렬해야합니다. 다시 말해, 컨트롤이 함수 진입 점으로 전송 될 때 값 (%esp + 4)은 항상 16 (32 또는 64)의 배수입니다. 스택 포인터 인 %esp는 항상 최신 할당 된 스택 프레임의 끝을 가리 킵니다.
-Intel386-Psabi-1.1 : 2.2.2 스택 프레임
스택 포인터 인 %RSP는 항상 최신 할당 된 스택 프레임의 끝을 가리 킵니다.
- SYS v ABI AMD64 버전 1.0 : 3.2.2 스택 프레임
다음은 Tencent의 Libco의 버그 예입니다. ABI는 (E|R)SP 항상 할당 된 스택 프레임의 끝을 가리켜야한다고 명시하고 있습니다. 그러나 libco의 Coctx_swap.s 파일에서 (E|R)SP 힙의 메모리를 다루는 데 사용되었습니다.
기본적으로 신호 처리기는 일반 프로세스 스택에서 호출됩니다. 신호 핸들러가 대체 스택을 사용하도록 정리할 수 있습니다. 이 작업을 수행하는 방법과 유용한시기에 대한 토론은 Sigalstack (2)을 참조하십시오.
- Man 7 신호 : 신호 배치
신호가 오면 (E|R)SP 힙의 데이터 구조를 가리키면 끔찍한 일이 발생할 수 있습니다. (GDB의 breakpoint 및 signal 명령을 사용하면 그러한 버그가 편리하게 생성 될 수 있습니다. 비록 sigalstack 사용하여 기본 신호 스택을 변경하면 문제가 완화 될 수 있지만 여전히 (E|R)SP 의 사용량은 여전히 ABI를 위반합니다).
요약하면, Libaco의 초저 성능을 얻으려면 aco_yield 가능한 작게 호출하는 시점에서 비 스탠다 론 비 메인 공동의 스택 사용을 유지하십시오. 로컬 변수가 일반적으로 공유 스택에 있기 때문에 로컬 변수의 주소를 한 CO에서 다른 CO로 전달하려면 매우주의하십시오. 이런 종류의 변수를 힙에서 할당하는 것은 항상 더 현명한 선택입니다.
자세히 5 가지 팁이 있습니다.
co_fp
/
/
f1 f2
/ /
/ f4
yield f3 f5
aco_yield 호출)은 벤치 마크 결과에 의해 이미 지시 된 바와 같이 코 루틴 간의 컨텍스트 전환 성능에 큰 영향을 미칩니다. 위의 다이어그램에서 함수 F2, F3, F4 및 F5의 스택 사용은 실행할 때 aco_yield 가 없기 때문에 컨텍스트 전환 성능에 직접적인 영향을 미치지 않지만 CO_FP 및 F1의 스택 사용은 co->save_stack.max_cpsz 의 값을 지배하며 Context 전환에 큰 영향을 미칩니다. 기능의 스택 사용을 가능한 한 낮게 유지하는 핵심은 힙에 로컬 변수 (특히 큰 변수)를 기본적으로 스택에 할당하는 대신 수명주기를 수동으로 관리하는 것입니다. GCC의 -fstack-usage 옵션은 이에 대해 매우 유용합니다.
int * gl_ptr ;
void inc_p ( int * p ){ ( * p ) ++ ; }
void co_fp0 () {
int ct = 0 ;
gl_ptr = & ct ; // line 7
aco_yield ();
check ( ct );
int * ptr = & ct ;
inc_p ( ptr ); // line 11
aco_exit ();
}
void co_fp1 () {
do_sth ( gl_ptr ); // line 16
aco_exit ();
}gl_ptr 에서 주소를 보유하고있는 주소는 CO_FP0의 7 행에서 gl_ptr 과 완전히 다른 의미를 갖고 있으며, 이러한 종류의 코드는 아마도 CO_FP1의 실행 스택을 손상시킬 것입니다. 그러나 가변 ct 와 함수 inc_p 동일한 코 루틴 컨텍스트에 있기 때문에 11 행은 괜찮습니다. 힙에 이러한 종류의 변수 (다른 코 루틴과 공유해야 함)를 할당하는 것은 단순히 그러한 문제를 해결할 수 있습니다. int * gl_ptr ;
void inc_p ( int * p ){ ( * p ) ++ ; }
void co_fp0 () {
int * ct_ptr = malloc ( sizeof ( int ));
assert ( ct_ptr != NULL );
* ct_ptr = 0 ;
gl_ptr = ct_ptr ;
aco_yield ();
check ( * ct_ptr );
int * ptr = ct_ptr ;
inc_p ( ptr );
free ( ct_ptr );
gl_ptr = NULL ;
aco_exit ();
}
void co_fp1 () {
do_sth ( gl_ptr );
aco_exit ();
}새로운 아이디어를 환영합니다!
p = malloc(sz); assertalloc_ptr(p) 과 같은 것들의 조합 인 aco_mem_new 와 같은 매크로를 추가하십시오. p = malloc(sz); assertalloc_ptr(p) .
코 루틴 객체의 재사용 성을 지원하기 위해 새 API aco_reset 추가하십시오.
다른 플랫폼 (특히 ARM & ARM64)을 지원합니다.
v1.2.4 Sun Jul 29 2018
Changed `asm` to `__asm__` in aco.h to support compiler's `--std=c99`
flag (Issue #16, proposed by Theo Schlossnagle @postwait).
v1.2.3 Thu Jul 26 2018
Added support for MacOS;
Added support for shared library build of libaco (PR #10, proposed
by Theo Schlossnagle @postwait);
Added C macro ACO_REG_IDX_BP in aco.h (PR #15, proposed by
Theo Schlossnagle @postwait);
Added global C config macro ACO_USE_ASAN which could enable the
friendly support of address sanitizer (both gcc and clang) (PR #14,
proposed by Theo Schlossnagle @postwait);
Added README_zh.md.
v1.2.2 Mon Jul 9 2018
Added a new option `-o <no-m32|no-valgrind>` to make.sh;
Correction about the value of macro ACO_VERSION_PATCH (issue #1
kindly reported by Markus Elfring @elfring);
Adjusted some noncompliant naming of identifiers (double underscore
`__`) (issue #1, kindly proposed by Markus Elfring @elfring);
Supported the header file including by C++ (issue #4, kindly
proposed by Markus Elfring @elfring).
v1.2.1 Sat Jul 7 2018
Fixed some noncompliant include guards in two C header files (
issue #1 kindly reported by Markus Elfring @elfring);
Removed the "pure" word from "pure C" statement since it is
containing assembly codes (kindly reported by Peter Cawley
@corsix);
Many updates in the README.md document.
v1.2.0 Tue Jul 3 2018
Provided another header named `aco_assert_override.h` so user
could choose to override the default `assert` or not;
Added some macros about the version information.
v1.1 Mon Jul 2 2018
Removed the requirement on the GCC version (>= 5.0).
v1.0 Sun Jul 1 2018
The v1.0 release of libaco, cheers ???
저는 풀 타임 오픈 소스 개발자입니다. 기부금의 어느 정도는 높이 평가 될 것이며 나에게 큰 격려를 줄 수 있습니다.
PayPal
PayPal.me 링크
Alipay (支付 支付 (宝 | 寶))


Libaco의 로고는 Peter Beh (Peteck)에 의해 관대하게 기증되었습니다. 로고는 CC By-ND 4.0에 따라 라이센스가 부여됩니다. libaco.org의 웹 사이트는 Peter Beh (Peteck)가 친절하게 기여합니다.
Copyright (C) 2018, sen han [email protected].
Apache 라이센스에 따라 버전 2.0.
자세한 내용은 라이센스 파일을 참조하십시오.


