InternLM XComposer
1.0.0
Internlm-xcomposer-2.5
 xcomposer2.5 기술 보고서?
xcomposer2.5 기술 보고서?영어 | 简体中文
포옹 페이스 데모에 감사드립니다 | Internlm-xcomposer-2.5의 OpenXlab 데모.
Discord와 Wechat에 우리와 함께하십시오
Internlm-xcomposer-2.5 : 장기 텍스트 입력 및 출력을 지원하는 다목적 대형 비전 언어 모델
Internlm-xcomposer2-
: 336 픽셀에서 4K HD까지의 선구적인 대규모 시력 모델 처리 해상도
Internlm-xcomposer2 : 비전 언어 대형 모델의 자유 형식 텍스트 이미지 구성 및 이해력 마스터 링
Internlm-xcomposer : 고급 텍스트 이미지 이해력 및 구성을위한 비전 언어 대형 모델
sharegpt4video : 더 나은 캡션으로 비디오 이해와 생성을 향상시킵니다
sharegpt4v : 더 나은 캡션으로 대형 멀티 모달 모델을 개선합니다
MMDU : LVLMS 용 벤치 마크 및 명령 조정 데이터 세트 이해 다중 회전 다중 이미지 대화 상자 이해
Dualfocus : 다중 모달 대형 언어 모델에 거시적 및 마이크로 관점 통합
Internlm-xcomposer-2.5는 다양한 텍스트 이미지 이해력 및 구성 응용 프로그램으로 탁월하여 단지 7B LLM 백엔드로 GPT-4V 레벨 기능을 달성합니다. IXC-2.5는 24K의 인터리브 이미지 텍스트 컨텍스트로 훈련되어 로프 외삽을 통해 96K 길이의 컨텍스트로 완벽하게 확장 될 수 있습니다. 이 긴 컨텍스트 기능을 사용하면 광범위한 입력 및 출력 컨텍스트가 필요한 작업에서 IXC-2.5가 예외적으로 잘 수행 될 수 있습니다.
초고 해상도 이해 : IXC-2.5는 IXC2-4KHD에서 제안 된 동적 해상도 솔루션을 기본 560 × 560 vit Vision 인코더로 향상시켜 모든 종횡비를 가진 고해상도 이미지를 지원합니다.
세분화 된 비디오 이해 : IXC-2.5는 비디오를 수십에서 수백 개의 프레임으로 구성된 초 고해상도 복합 사진으로 취급하여 밀도가 높은 샘플링을 통해 미세한 세부 사항을 캡처하고 각 프레임에 대한 높은 해상도를 캡처 할 수 있습니다.
멀티 턴 다중 이미지 대화 : IXC-2.5는 자유 형식의 멀티 턴 다중 이미지 대화를 지원하여 다중 라운드 대화에서 자연스럽게 인간과 상호 작용할 수 있습니다.
웹 페이지 크래프트 : IXC-2.5는 텍스트 이미지 지침에 따라 소스 코드 (HTML, CSS 및 JavaScript)를 작성하여 웹 페이지를 만들기 위해 쉽게 적용될 수 있습니다.
고품질 텍스트 이미지 기사 작성 : IXC-2.5는 특별히 설계된 COT (CAT) 및 DPO (Direct Preverence Optimization) 기술을 활용하여 서면 컨텐츠의 품질을 크게 향상시킵니다.
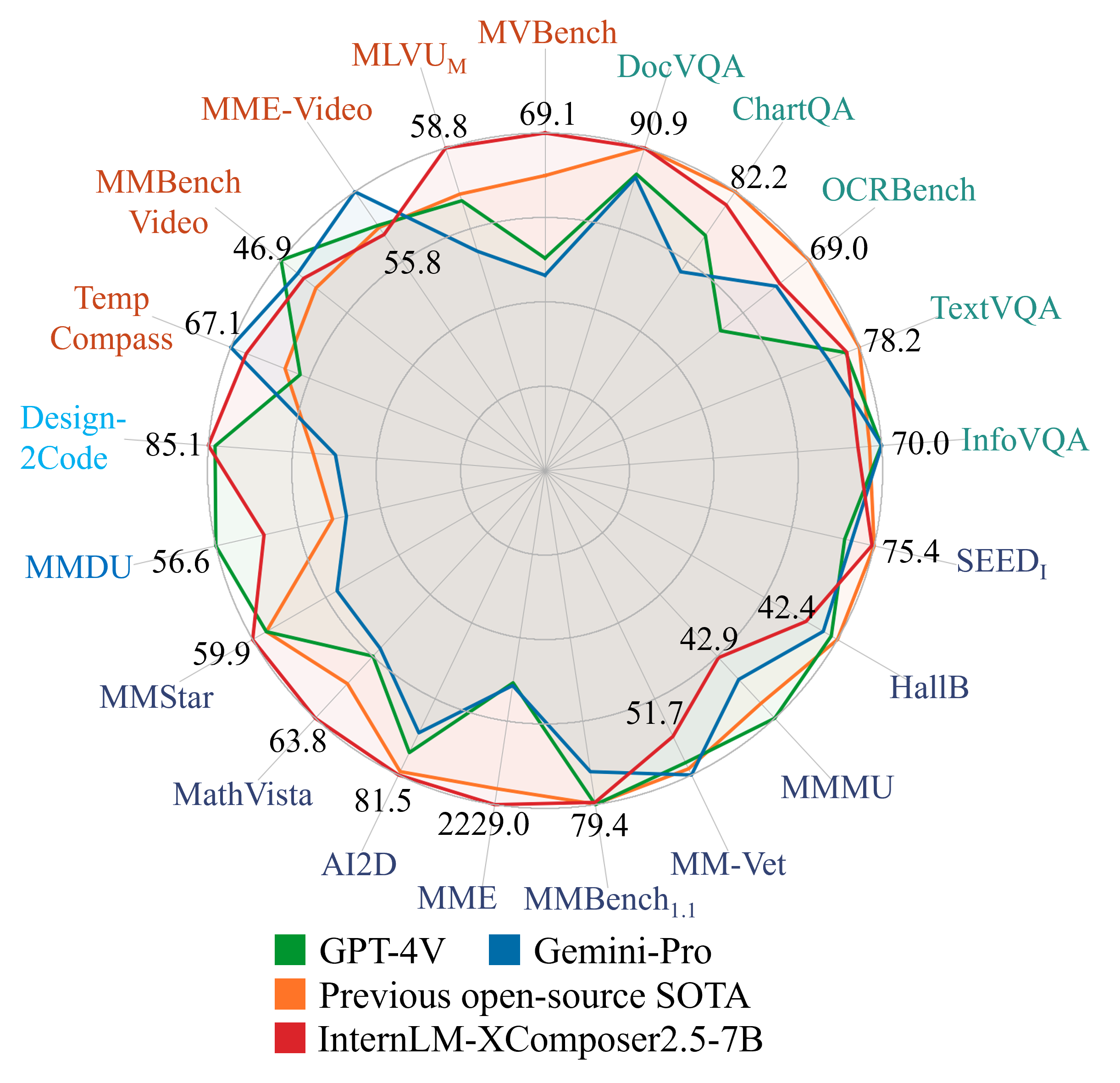
멋진 성능 : IXC-2.5는 28 개의 벤치 마크에서 평가되어 16 개의 벤치 마크에서 기존 오픈 소스 최첨단 모델을 능가했습니다. 또한 16 개의 주요 작업에서 GPT-4V 및 Gemini Pro와 긴밀히 경쟁하거나 경쟁합니다.
자세한 내용은 기술 보고서를 참조하십시오.
최상의 경험을 보려면 비디오를 즐기면서 오디오를 켜십시오.
YouTube 비디오
중국어 버전의 데모는 중국 데모를 참조하십시오.
2024.07.15 ??? ModelScope Swift는 미세 조정 및 추론을 위해 InternLM-Xcomposer2.5-7B를 지원합니다.2024.07.15 ??? LMDEPOLY는 4 비트 양자화 및 추론을 위해 InternLM-Xcomposer2.5-7B를 지원합니다.2024.07.15 ??? Internlm-xcomposer2.5-7B-4 비트가 공개적으로 제공됩니다.2024.07.03 ??? Internlm-xcomposer2.5-7b가 공개적으로 제공됩니다.2024.07.01 ??? sharegpt4v는 ECCV2024에 의해 허용됩니다.2024.04.22 ??? Internlm-xcomposer2-VL-7B-4KHD-7B 의 FINETUNE 코드는 공개적으로 제공됩니다.2024.04.09 ??? Internlm-xcomposer2-4KHD-7B 및 평가 코드는 공개적으로 제공됩니다.2024.04.09 ??? Internlm-xcomposer2-VL-1.8b가 공개적으로 제공됩니다.2024.02.22 ??? 우리는 MLLM 내에 매크로 및 마이크로 관점을 통합하기위한 프레임 워크 인 Dualfocus를 발표하여 비전 언어 작업 성능을 향상시킵니다.2024.02.06 ??? Internlm-xcomposer2-7B-4 비트 및 Internlm-Xcomposer-VL2-7B-4 비트는 포옹 페이스 및 모델 코프 에서 공개적으로 제공됩니다.2024.02.02 ??? Internlm-xcomposer2-VL-7B 의 Finetune 코드는 공개적으로 제공됩니다.2024.01.26 ??? Internlm-xcomposer2-VL-7B 의 평가 코드는 공개적으로 제공됩니다.2024.01.26 ??? Internlm-xcomposer2-7b 및 Internlm-xcomposer-VL2-7B는 포옹 페이스 및 ModelScope 에서 공개적으로 제공됩니다.2024.01.26 ??? Internlm-Xcomposer2 시리즈에 대한 자세한 내용은 기술 보고서를 발표합니다.2023.11.22 ??? 우리는 GPT4- vision과 우수한 대형 멀티 모달 모델 인 ShareGPT4V-7B에 의해 생성 된 대규모 서술 적 이미지 텍스트 데이터 세트 인 ShareGPT4V를 해제합니다.2023.10.30 ??? Internlm-xcomposer-VL은 Q- 벤치와 작은 LVLM에서 상위 1 위를 달성했습니다.2023.10.19 ??? 다중 GPU에 대한 추론 지원. 두 개의 4090 GPU가 데모를 배포하기에 충분합니다.2023.10.12 ??? 4 비트 데모는 지원되며 모델 파일은 포옹 및 ModelScope에서 사용할 수 있습니다.2023.10.8 ??? Internlm-xcomposer-7b 및 Internlm-xcomposer-VL-7B는 ModelScope 에서 공개적으로 제공됩니다.2023.9.27 ??? Internlm-xcomposer-VL-7B 의 평가 코드는 공개적으로 제공됩니다.2023.9.27 ??? Internlm-xcomposer-7b 및 Internlm-xcomposer-VL-7B는 포옹 얼굴 에서 공개적으로 제공됩니다.2023.9.27 ??? 모델 시리즈의 자세한 내용은 기술 보고서를 발표합니다. | 모델 | 용법 | 변압기 (HF) | ModelScope (HF) | 출시일 |
|---|---|---|---|---|
| Internlm-xcomposer-2.5 | 비디오 이해, 다중 이미지 멀티 튜닝 대화, 4K 해상도 이해, 웹 크래프트, 기사 제작, 벤치 마크 | ? Internlm-xcomposer2.5 | Internlm-xcomposer2.5 | 2024-07-03 |
| Internlm-xcomposer2-4KHD | 4K 해상도 이해, 벤치 마크, VL-Chat | ? Internlm-xcomposer2-4KHD-7B | Internlm-xcomposer2-4KHD-7B | 2024-04-09 |
| Internlm-xcomposer2-VL-1.8b | 벤치 마크, VL-Chat | ? Internlm-xcomposer2-VL-1_8B | Internlm-xcomposer2-VL-1_8b | 2024-04-09 |
| Internlm-xcomposer2 | 텍스트 이미지 구성 | ? Internlm-xcomposer2-7b | Internlm-xcomposer2-7b | 2024-01-26 |
| internlm-xcomposer2-vl | 벤치 마크, VL-Chat | ? Internlm-xcomposer2-VL-7B | Internlm-xcomposer2-VL-7b | 2024-01-26 |
| Internlm-xcomposer2-4 비트 | 텍스트 이미지 구성 | ? Internlm-xcomposer2-7B-4 비트 | Internlm-xcomposer2-7B-4 비트 | 2024-02-06 |
| Internlm-xcomposer2-VL-4 비트 | 벤치 마크, VL-Chat | ? Internlm-xcomposer2-VL-7B-4 비트 | Internlm-xcomposer2-VL-7B-4 비트 | 2024-02-06 |
| Internlm-xcomposer | 텍스트 이미지 구성, VL-Chat | ? Internlm-xcomposer-7b | Internlm-xcomposer-7b | 2023-09-26 |
| Internlm-xcomposer-4 비트 | 텍스트 이미지 구성, VL-Chat | ? Internlm-xcomposer-7b-4 비트 | Internlm-xcomposer-7b-4 비트 | 2023-09-26 |
| Internlm-xcomposer-vl | 기준 | ? Internlm-xcomposer-VL-7B | Internlm-xcomposer-VL-7B | 2023-09-26 |
우리는 이미지 벤치 마크 MMDU, MMSTAR, RealWorlDQA, Design2Code, DocVQA, Infographics VQA, TextVQA, ChartQA, Ocrbench, DeepFrom, WTQ, MOMRC, Tabfacta, MMMU, Ai2d, MME MMBENCH-CN, SEED-BENCH, HOLLUSIONBENCH, MM-VET 및 비디오 벤치 마크 MVBENCH, MLVU, VIDEO-MME, MMBENCH-VIEDO, TEMPCOMPARSE
평가 세부 사항을 참조하십시오.
| mvbench | MLVU | MME- 비디오 | Mmbench-Video | 온도 | docvqa | 차트 vqa | infovqa | TextVqa | OCRBENCH | Deepform | WTQ | VisualMrc | tabfact | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| videochat2 | Internvl1.5 | 리바 | Internvl1.5 | Qwen-VL | Internvl1.5 | Internvl1.5 | Internvl1.5 | Internvl1.5 | GLM-4V | docowl 1.5 | docowl 1.5 | docowl 1.5 | docowl 1.5 | |
| 7b | 26b | 34b | 26b | 7b | 26b | 26b | 26b | 26b | 9b | 8b | 8b | 8b | 8b | |
| 60.4 | 50.4 | 59.0 | 42.0 | 52.9 | 90.9 | 83.8 | 72.5 | 80.6 | 77.6 | 68.8 | 40.6 | 246.4 | 80.2 | |
| GPT-4V | 43.5 | 49.2 | 59.9 | 56.0 | --- | 88.4 | 78.5 | 75.1 | 78.0 | 51.6 | --- | --- | --- | --- |
| 쌍둥이 자리 프로 | --- | --- | 75.0 | 49.3 | 67.1 | 88.1 | 74.1 | 75.2 | 74.6 | 68.0 | --- | --- | --- | --- |
| 우리 것 | 69.1 | 58.8 | 55.8 | 46.9 | 90.9 | 82.2 | 69.9 | 78.2 | 69.0 | 71.2 | 53.6 | 307.5 | 85.2 |
| mvbench | MLVU | MME- 비디오 | Mmbench-Video | 온도 | docvqa | 차트 vqa | infovqa | TextVqa | OCRBENCH | Deepform | WTQ | VisualMrc | tabfact | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| videochat2 | Internvl1.5 | 리바 | Internvl1.5 | Qwen-VL | Internvl1.5 | Internvl1.5 | Internvl1.5 | Internvl1.5 | GLM-4V | docowl 1.5 | docowl 1.5 | docowl 1.5 | docowl 1.5 | |
| 7b | 26b | 34b | 26b | 7b | 26b | 26b | 26b | 26b | 9b | 8b | 8b | 8b | 8b | |
| 60.4 | 50.4 | 59.0 | 42.0 | 58.4 | 90.9 | 83.8 | 72.5 | 80.6 | 77.6 | 68.8 | 40.6 | 246.4 | 80.2 | |
| GPT-4V | 43.5 | 49.2 | 59.9 | 56.0 | --- | 88.4 | 78.5 | 75.1 | 78.0 | 51.6 | --- | --- | --- | --- |
| 쌍둥이 자리 프로 | --- | --- | 75.0 | 49.3 | 70.6 | 88.1 | 74.1 | 75.2 | 74.6 | 68.0 | --- | --- | --- | --- |
| 우리 것 | 69.1 | 58.8 | 55.8 | 46.9 | 67.1 | 90.9 | 82.2 | 69.9 | 78.2 | 69.0 | 71.2 | 53.6 | 307.5 | 85.2 |
코드를 실행하기 전에 환경을 설정하고 필요한 패키지를 설치했는지 확인하십시오. 위의 요구 사항을 충족 한 다음 종속 라이브러리를 설치하십시오. 설치 지침을 참조하십시오
Internlm-xcomposer-2.5와 함께 사용하는 방법을 보여주는 간단한 예를 제공합니다. 변압기.
import torch
from transformers import AutoModel , AutoTokenizer
torch . set_grad_enabled ( False )
# init model and tokenizer
model = AutoModel . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , torch_dtype = torch . bfloat16 , trust_remote_code = True ). cuda (). eval (). half ()
tokenizer = AutoTokenizer . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , trust_remote_code = True )
model . tokenizer = tokenizer
query = 'Here are some frames of a video. Describe this video in detail'
image = [ './examples/liuxiang.mp4' ,]
with torch . autocast ( device_type = 'cuda' , dtype = torch . float16 ):
response , his = model . chat ( tokenizer , query , image , do_sample = False , num_beams = 3 , use_meta = True )
print ( response )
#The video opens with a shot of an athlete, dressed in a red and yellow uniform with the word "CHINA" emblazoned across the front, preparing for a race.
#The athlete, Liu Xiang, is seen in a crouched position, focused and ready, with the Olympic rings visible in the background, indicating the prestigious setting of the Olympic Games. As the race commences, the athletes are seen sprinting towards the hurdles, their determination evident in their powerful strides.
#The camera captures the intensity of the competition, with the athletes' numbers and times displayed on the screen, providing a real-time update on their performance. The race reaches a climax as Liu Xiang, still in his red and yellow uniform, triumphantly crosses the finish line, his arms raised in victory.
#The crowd in the stands erupts into cheers, their excitement palpable as they witness the athlete's success. The video concludes with a close-up shot of Liu Xiang, still basking in the glory of his victory, as the Olympic rings continue to symbolize the significance of the event.
query = 'tell me the athlete code of Liu Xiang'
image = [ './examples/liuxiang.mp4' ,]
with torch . autocast ( device_type = 'cuda' , dtype = torch . float16 ):
response , _ = model . chat ( tokenizer , query , image , history = his , do_sample = False , num_beams = 3 , use_meta = True )
print ( response )
#The athlete code of Liu Xiang, as displayed on his uniform in the video, is "1363". import torch
from transformers import AutoModel , AutoTokenizer
torch . set_grad_enabled ( False )
# init model and tokenizer
model = AutoModel . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , torch_dtype = torch . bfloat16 , trust_remote_code = True ). cuda (). eval (). half ()
tokenizer = AutoTokenizer . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , trust_remote_code = True )
model . tokenizer = tokenizer
query = 'Image1 <ImageHere>; Image2 <ImageHere>; Image3 <ImageHere>; I want to buy a car from the three given cars, analyze their advantages and weaknesses one by one'
image = [ './examples/cars1.jpg' ,
'./examples/cars2.jpg' ,
'./examples/cars3.jpg' ,]
with torch . autocast ( device_type = 'cuda' , dtype = torch . float16 ):
response , his = model . chat ( tokenizer , query , image , do_sample = False , num_beams = 3 , use_meta = True )
print ( response )
#To analyze the advantages and disadvantages of each car, we need to consider factors such as brand reputation, performance, design, cost, and maintenance.
#1. Mercedes-Benz: - Advantages: Known for its luxury and reliability, the Mercedes-Benz brand offers a high level of comfort, advanced technology, and superior craftsmanship. The vehicle in the image appears to be an SUV, which is versatile for both city driving and off-road conditions. - Disadvantages: Typically, Mercedes-Benz vehicles are more expensive compared to other brands, and they may require more frequent maintenance due to their luxury status.
#2. Bugatti: - Advantages: Bugatti is renowned for producing some of the fastest and most powerful cars in the world. The vehicle in the image is a sports car, likely offering an exhilarating driving experience with its high-performance engine and advanced aerodynamics. - Disadvantages: Bugatti cars are extremely expensive, making them less accessible to the average consumer. They also require specialized knowledge for maintenance and may not be suitable for everyday driving due to their high-performance nature.
#3. BMW: - Advantages: BMW is a well-respected manufacturer known for its innovative engineering and design. The car in the image appears to be an electric vehicle (EV), which offers advantages such as lower emissions, reduced noise pollution, and potentially lower operating costs. - Disadvantages: EVs like the one in the image may have a shorter range compared to traditional gasoline-powered vehicles, limiting their suitability for long-distance travel.
#Additionally, the initial cost of purchasing an EV can be higher than that of a conventional car. In conclusion, each car has its own set of advantages and disadvantages. The Mercedes-Benz offers luxury and versatility, the Bugatti provides high performance and exclusivity, and the BMW represents innovation in electric vehicle technology. The choice ultimately depends on the buyer's priorities, such as comfort, performance, environmental impact, and budget.
query = 'Image4 <ImageHere>; How about the car in Image4'
image . append ( './examples/cars4.jpg' )
with torch . autocast ( device_type = 'cuda' , dtype = torch . float16 ):
response , _ = model . chat ( tokenizer , query , image , do_sample = False , num_beams = 3 , history = his , use_meta = True )
print ( response )
#The car in Image4 is a red sports car, which appears to be a Ferrari. Ferrari is a renowned Italian manufacturer known for producing some of the most iconic and high-performance sports cars in the world. - Advantages: Ferrari vehicles are synonymous with speed, luxury, and engineering excellence.
#The car in the image likely offers an exhilarating driving experience with its powerful engine, advanced aerodynamics, and high-quality craftsmanship. The red color adds to the car's aesthetic appeal, making it stand out on the road. - Disadvantages: Ferrari cars are extremely expensive, making them less accessible to the average consumer.
#They also require specialized knowledge for maintenance and may not be suitable for everyday driving due to their high-performance nature. In conclusion, the Ferrari in Image4 represents a pinnacle of automotive engineering and design, offering unmatched performance and luxury.
#However, its high cost and specialized maintenance requirements make it less practical for everyday use compared to the other vehicles in the images. import torch
from transformers import AutoModel , AutoTokenizer
torch . set_grad_enabled ( False )
# init model and tokenizer
model = AutoModel . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , torch_dtype = torch . bfloat16 , trust_remote_code = True ). cuda (). eval (). half ()
tokenizer = AutoTokenizer . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , trust_remote_code = True )
model . tokenizer = tokenizer
query = 'Analyze the given image in a detail manner'
image = [ './examples/dubai.png' ]
with torch . autocast ( device_type = 'cuda' , dtype = torch . float16 ):
response , _ = model . chat ( tokenizer , query , image , do_sample = False , num_beams = 3 , use_meta = True )
print ( response )
#The infographic is a visual representation of various facts about Dubai. It begins with a statement about Palm Jumeirah, highlighting it as the largest artificial island visible from space. It then provides a historical context, noting that in 1968, there were only a few cars in Dubai, contrasting this with the current figure of more than 1.5 million vehicles.
#The infographic also points out that Dubai has the world's largest Gold Chain, with 7 of the top 10 tallest hotels located there. Additionally, it mentions that the crime rate is near 0%, and the income tax rate is also 0%, with 20% of the world's total cranes operating in Dubai. Furthermore, it states that 17% of the population is Emirati, and 83% are immigrants.
#The Dubai Mall is highlighted as the largest shopping mall in the world, with 1200 stores. The infographic also notes that Dubai has no standard address system, with no zip codes, area codes, or postal services. It mentions that the Burj Khalifa is so tall that its residents on top floors need to wait longer to break fast during Ramadan.
#The infographic also includes information about Dubai's climate-controlled City, with the Royal Suite at Burj Al Arab costing $24,000 per night. Lastly, it notes that the net worth of the four listed billionaires is roughly equal to the GDP of Honduras. import torch
from transformers import AutoModel , AutoTokenizer
torch . set_grad_enabled ( False )
# init model and tokenizer
model = AutoModel . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , torch_dtype = torch . bfloat16 , trust_remote_code = True ). cuda (). eval (). half ()
tokenizer = AutoTokenizer . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , trust_remote_code = True )
model . tokenizer = tokenizer
query = 'A website for Research institutions. The name is Shanghai AI lab. Top Navigation Bar is blue.Below left, an image shows the logo of the lab. In the right, there is a passage of text below that describes the mission of the laboratory.There are several images to show the research projects of Shanghai AI lab.'
with torch . autocast ( device_type = 'cuda' , dtype = torch . float16 ):
response = model . write_webpage ( query , seed = 202 , task = 'Instruction-aware Webpage Generation' , repetition_penalty = 3.0 )
print ( response )
# see the Instruction-aware Webpage Generation.html 여기에서 웹 페이지 결과에 대한 지침을 참조하십시오.
import torch
from transformers import AutoModel , AutoTokenizer
torch . set_grad_enabled ( False )
# init model and tokenizer
model = AutoModel . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , torch_dtype = torch . bfloat16 , trust_remote_code = True ). cuda (). eval (). half ()
tokenizer = AutoTokenizer . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , trust_remote_code = True )
model . tokenizer = tokenizer
## the input should be a resume in markdown format
query = './examples/resume.md'
with torch . autocast ( device_type = 'cuda' , dtype = torch . float16 ):
response = model . resume_2_webpage ( query , seed = 202 , repetition_penalty = 3.0 )
print ( response )여기에서 이력서에 대한 이력서를 참조하십시오.
import torch
from transformers import AutoModel , AutoTokenizer
torch . set_grad_enabled ( False )
# init model and tokenizer
model = AutoModel . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , torch_dtype = torch . bfloat16 , trust_remote_code = True ). cuda (). eval (). half ()
tokenizer = AutoTokenizer . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , trust_remote_code = True )
model . tokenizer = tokenizer
query = 'Generate the HTML code of this web image with Tailwind CSS.'
image = [ './examples/screenshot.jpg' ]
with torch . autocast ( device_type = 'cuda' , dtype = torch . float16 ):
response = model . screen_2_webpage ( query , image , seed = 202 , repetition_penalty = 3.0 )
print ( response )웹 페이지 결과에서 스크린 샷을 확인하십시오.
import torch
from transformers import AutoModel , AutoTokenizer
torch . set_grad_enabled ( False )
# init model and tokenizer
model = AutoModel . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , torch_dtype = torch . bfloat16 , trust_remote_code = True ). cuda (). eval (). half ()
tokenizer = AutoTokenizer . from_pretrained ( 'internlm/internlm-xcomposer2d5-7b' , trust_remote_code = True )
model . tokenizer = tokenizer
query = '阅读下面的材料,根据要求写作。 电影《长安三万里》的出现让人感慨,影片并未将重点全落在大唐风华上,也展现了恢弘气象的阴暗面,即旧门阀的资源垄断、朝政的日益衰败与青年才俊的壮志难酬。高适仕进无门,只能回乡>沉潜修行。李白虽得玉真公主举荐,擢入翰林,但他只是成为唐玄宗的御用文人,不能真正实现有益于朝政的志意。然而,片中高潮部分《将进酒》一节,人至中年、挂着肚腩的李白引众人乘仙鹤上天,一路从水面、瀑布飞升至银河进入仙>宫,李白狂奔着与仙人们碰杯,最后大家纵身飞向漩涡般的九重天。肉身的微贱、世路的“天生我材必有用,坎坷,拘不住精神的高蹈。“天生我材必有用,千金散尽还复来。” 古往今来,身处闲顿、遭受挫折、被病痛折磨,很多人都曾经历>了人生的“失意”,却反而成就了他们“诗意”的人生。对正在追求人生价值的当代青年来说,如何对待人生中的缺憾和困顿?诗意人生中又有怎样的自我坚守和自我认同?请结合“失意”与“诗意”这两个关键词写一篇文章。 要求:选准角度,确定>立意,明确文体,自拟标题;不要套作,不得抄袭;不得泄露个人信息;不少于 800 字。'
with torch . autocast ( device_type = 'cuda' , dtype = torch . float16 ):
response = model . write_artical ( query , seed = 8192 )
print ( response )
#诗意人生,贵在坚守
#《菜根谭》有云:“闲时要有吃紧的心思,忙里要留吃闲工夫。”人生在世,总有失意之时,当面对缺憾和困顿,诗意地生活着才能为人生增添一抹亮色。何谓诗意地生活? 所谓诗意地生活,便是在于坚守本心、直面遗憾、超越自我,在失意中寻找人生价值。
#诗意地生活,需坚守本心,淡然处之。
#陶渊明曾执意辞去彭泽县令,归隐田园,“采菊东篱下,悠然见南山”,在山水间寄情自娱;王维面对仕途失意,终日沉醉于诗酒之中,“兴来每独往,胜事空自知”,在诗酒中闲逸自如;李白仕途不顺,被赐金放还,但他依旧豪气干云,“天生我才必有用,千金散尽还复来”,在失意中坦然豁达。坚守本心,便能在遭遇失意之时守住自己的精神家园,让生活充满诗意。反之,若不能坚守本心,而只是一味迎合世俗以求得升迁,那纵使身居高位,亦会丧失生活的乐趣。
#诗意地生活,需直面遗憾,超越自我。
#“西塞山前白鹭飞,桃花流水鳜鱼肥。青箬笠,绿柳枝,半斤酒,一纶丝。五湖四海皆如此,何妨到此处归。”白居易的《渔歌子》写出了多少人的愿望:没有权势纷扰,没有贫困凄凉,只有青山绿水、白鹭鸥鸟作伴,如此自由自在的生活令人神往。然而,白居易却并没有因此真的归隐山林,而是直面人生,超越自我,写下了一首首诗意而富有现实关怀的作品。如果白居易只顾逃避人生,那又怎会拥有“大弦嘈嘈如急雨,小弦切切如私语”的绝美比喻呢?如果白居易只顾归隐山林,那又怎会写出“此曲只应天上有,人间哪得配白居易”这样的诗句呢?
#诗意地生活,需直面遗憾,坚守本心。
#李文波患有渐冻症,医生说他活不过五年,但他没有因此放弃对音乐的热爱,而是与病魔作斗争,演奏出美妙的乐曲;孙家林自幼患有脑瘫,但他不甘于命运的捉弄,终成全国最美教师;史铁生饱受疾病折磨,但他仍能发出“我常常在我的心头清点,我有什么?”的叩问,并由此走上文学道路,为后世留下丰厚的文化遗产。这些人没有逃避,而是选择直面人生的缺憾,在坚守本心的同时超越自我,最终实现了自己的价值。
#诗意地生活,是于失意中坚守本心,于缺憾中超越自我。当面对人生的缺憾与挫折,坚守本心、超越自我的同时,也必将书写属于自己的辉煌篇章。
#愿你我都能诗意地生活着!
query = 'Please write a blog based on the title: French Pastries: A Sweet Indulgence'
with torch . autocast ( device_type = 'cuda' , dtype = torch . float16 ):
response = model . write_artical ( query , seed = 8192 )
print ( response )
#French Pastries: A Sweet Indulgence
#The French are well known for their love of pastries, and it’s a love that is passed down through generations. When one visits France, they are treated to an assortment of baked goods that can range from the delicate macaron to the rich and decadent chocolate mousse. While there are many delicious types of pastries found in France, five stand out as being the most iconic. Each of these pastries has its own unique qualities that make it special.
#1. Croissant
#One of the most famous pastries from France is the croissant. It is a buttery, flaky pastry that is best enjoyed fresh from the bakery. The dough is laminated with butter, giving it its signature layers. Croissants are typically eaten for breakfast or brunch, often accompanied by coffee or hot chocolate.
#2. Macaron
#The macaron is a small, delicate French confection made from almond flour, powdered sugar, and egg whites. The macaron itself is sandwiched with a ganache or jam filling. They come in a variety of colors and flavors, making them a popular choice for both casual snacking and upscale desserts.
#3. Madeleine
#The madeleine is a small shell-shaped cake that is light and sponge-like. It is often flavored with lemon or orange zest and sometimes dipped in chocolate. Madeleines are perfect for an afternoon snack with tea or coffee.
#4. Éclair
#The éclair is a long, thin pastry filled with cream and topped with chocolate glaze. It is a classic French treat that is both sweet and satisfying. Éclairs can be found in bakeries all over France and are often enjoyed with a cup of hot chocolate.
#5. Tarte Tatin
#The tarte Tatin is an apple tart that is known for its caramelized apples and puff pastry crust. It is named after the Tatin sisters who created the recipe in the late 19th century. Tarte Tatin is best served warm with a scoop of vanilla ice cream.
#These pastries are just a few of the many delicious treats that France has to offer. Whether you are a seasoned traveler or a first-time visitor, indulging in French pastries is a must-do activity. So go ahead, treat yourself—you deserve it! 여러 GPU가 있지만 각 GPU의 메모리 크기로 전체 모델을 수용하기에 충분하지 않은 경우 모델을 여러 GPU로 분할 할 수 있습니다. 먼저, 명령을 사용하여 accelerate 설치하십시오 : pip install accelerate . 그런 다음 채팅의 다음 스크립트를 실행하십시오.
# chat with 2 GPUs
python example_code/example_chat.py --num_gpus 2
Internlm-xcomposer2d5 모델 추론 최적화가 필요한 경우 lmdeploy를 사용하는 것이 좋습니다.
다음 하위 섹션에서는 예제로 InternLM-Xcomposer2D5-7B 모델과 함께 LMDEPLOY 사용을 소개합니다.
우선, pip install lmdeploy 와 함께 PYPI 패키지를 설치하십시오. 기본적으로 Cuda 12.x에 따라 다릅니다. Cuda 11.x 환경은 설치 안내서를 참조하십시오.
from lmdeploy import pipeline
from lmdeploy . vl import load_image
pipe = pipeline ( 'internlm/internlm-xcomposer2d5-7b' )
image = load_image ( 'examples/dubai.png' )
response = pipe (( 'describe this image' , image ))
print ( response . text )다중 이미지 추론 또는 다중 전환 채팅을 포함한 VLM 파이프 라인 사용에 대한 자세한 내용은이 안내서를 개요하십시오.
우리는 메모리 요구 사항을 줄이기 위해 LMDEPLOY를 통해 4 비트 양자 모델을 제공합니다. 메모리 사용 비교는 여기를 참조하십시오.
from lmdeploy import TurbomindEngineConfig , pipeline
from lmdeploy . vl import load_image
engine_config = TurbomindEngineConfig ( model_format = 'awq' )
pipe = pipeline ( 'internlm/internlm-xcomposer2d5-7b-4bit' , backend_config = engine_config )
image = load_image ( 'examples/dubai.png' )
response = pipe (( 'describe this image' , image ))
print ( response . text ) 사용자가 웹 UI 데모를 구축 할 수있는 코드를 제공합니다. gradio==4.13.0 사용하십시오
채팅 / 구성을 위해 아래 명령을 실행하십시오.
# For Multimodal Chat
python gradio_demo/gradio_demo_chat.py
# For Free-form Text-Image Composition
python gradio_demo/gradio_demo_composition.py
UI 데모의 사용자 지침은 여기에 나와 있습니다. 모델의 기본 폴더를 변경하려면 --code_path=new_folder 옵션을 사용하십시오.
연구에 유용한 모델 / 코드 / 서류를 찾으면주고 인용을 고려하십시오, thx :)
@article { internlmxcomposer2_5 ,
title = { InternLM-XComposer-2.5: A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output } ,
author = { Pan Zhang and Xiaoyi Dong and Yuhang Zang and Yuhang Cao and Rui Qian and Lin Chen and Qipeng Guo and Haodong Duan and Bin Wang and Linke Ouyang and Songyang Zhang and Wenwei Zhang and Yining Li and Yang Gao and Peng Sun and Xinyue Zhang and Wei Li and Jingwen Li and Wenhai Wang and Hang Yan and Conghui He and Xingcheng Zhang and Kai Chen and Jifeng Dai and Yu Qiao and Dahua Lin and Jiaqi Wang } ,
journal = { arXiv preprint arXiv:2407.03320 } ,
year = { 2024 }
} @article { internlmxcomposer2_4khd ,
title = { InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD } ,
author = { Xiaoyi Dong and Pan Zhang and Yuhang Zang and Yuhang Cao and Bin Wang and Linke Ouyang and Songyang Zhang and Haodong Duan and Wenwei Zhang and Yining Li and Hang Yan and Yang Gao and Zhe Chen and Xinyue Zhang and Wei Li and Jingwen Li and Wenhai Wang and Kai Chen and Conghui He and Xingcheng Zhang and Jifeng Dai and Yu Qiao and Dahua Lin and Jiaqi Wang } ,
journal = { arXiv preprint arXiv:2404.06512 } ,
year = { 2024 }
} @article { internlmxcomposer2 ,
title = { InternLM-XComposer2: Mastering Free-form Text-Image Composition and Comprehension in Vision-Language Large Model } ,
author = { Xiaoyi Dong and Pan Zhang and Yuhang Zang and Yuhang Cao and Bin Wang and Linke Ouyang and Xilin Wei and Songyang Zhang and Haodong Duan and Maosong Cao and Wenwei Zhang and Yining Li and Hang Yan and Yang Gao and Xinyue Zhang and Wei Li and Jingwen Li and Kai Chen and Conghui He and Xingcheng Zhang and Yu Qiao and Dahua Lin and Jiaqi Wang } ,
journal = { arXiv preprint arXiv:2401.16420 } ,
year = { 2024 }
} @article { internlmxcomposer ,
title = { InternLM-XComposer: A Vision-Language Large Model for Advanced Text-image Comprehension and Composition } ,
author = { Pan Zhang and Xiaoyi Dong and Bin Wang and Yuhang Cao and Chao Xu and Linke Ouyang and Zhiyuan Zhao and Shuangrui Ding and Songyang Zhang and Haodong Duan and Wenwei Zhang and Hang Yan and Xinyue Zhang and Wei Li and Jingwen Li and Kai Chen and Conghui He and Xingcheng Zhang and Yu Qiao and Dahua Lin and Jiaqi Wang } ,
journal = { arXiv preprint arXiv:2309.15112 } ,
year = { 2023 }
}이 코드는 Apache-2.0에 따라 라이센스가 부여되며 모델 가중치는 학업 연구를 위해 완전히 열려 있으며 무료 상업용 사용을 허용합니다. 상업용 라이센스를 신청하려면 신청서 (영어)/申请表 (中文)을 작성하십시오. 다른 질문이나 공동 작업은 [email protected]으로 문의하십시오.


