lang2sql
1.0.0
이 repo는 Opneai API와 함께 SQL 코드 생성기에 자연 언어를 설정하기위한 단계별 안내서와 템플릿을 제공합니다.
튜토리얼은 Medium에서도 제공됩니다.
마지막 업데이트 : 2024 년 1 월 7 일
자연어 모델, 특히 LLM (Lange Language Model)의 빠른 개발은 다양한 분야에 대한 수많은 가능성을 제시했습니다. 가장 일반적인 응용 프로그램 중 하나는 코딩에 LLM을 사용하는 것입니다. 예를 들어, OpenAi의 ChatGpt와 Meta의 코드 라마는 코드 생성기에게 최첨단 자연 언어를 제공하는 LLM입니다. 잠재적 인 사용 사례 중 하나는 SQL 코드 생성기에 대한 자연 언어로, 비 기술적 전문가에게 간단한 데이터 요청을 제공하고 데이터 팀이보다 데이터 집약적 인 작업에 집중할 수 있기를 바랍니다. 이 자습서는 OpenAI API를 사용하여 SQL 코드 생성기를위한 언어 설정에 중점을 둡니다.
가능한 응용 프로그램 중 하나는 관련 데이터가있는 사용자 쿼리에 응답 할 수있는 챗봇입니다 (그림 1). 챗봇은 다음 단계를 수행하는 파이썬 응용 프로그램을 사용하여 슬랙 채널과 통합 될 수 있습니다.
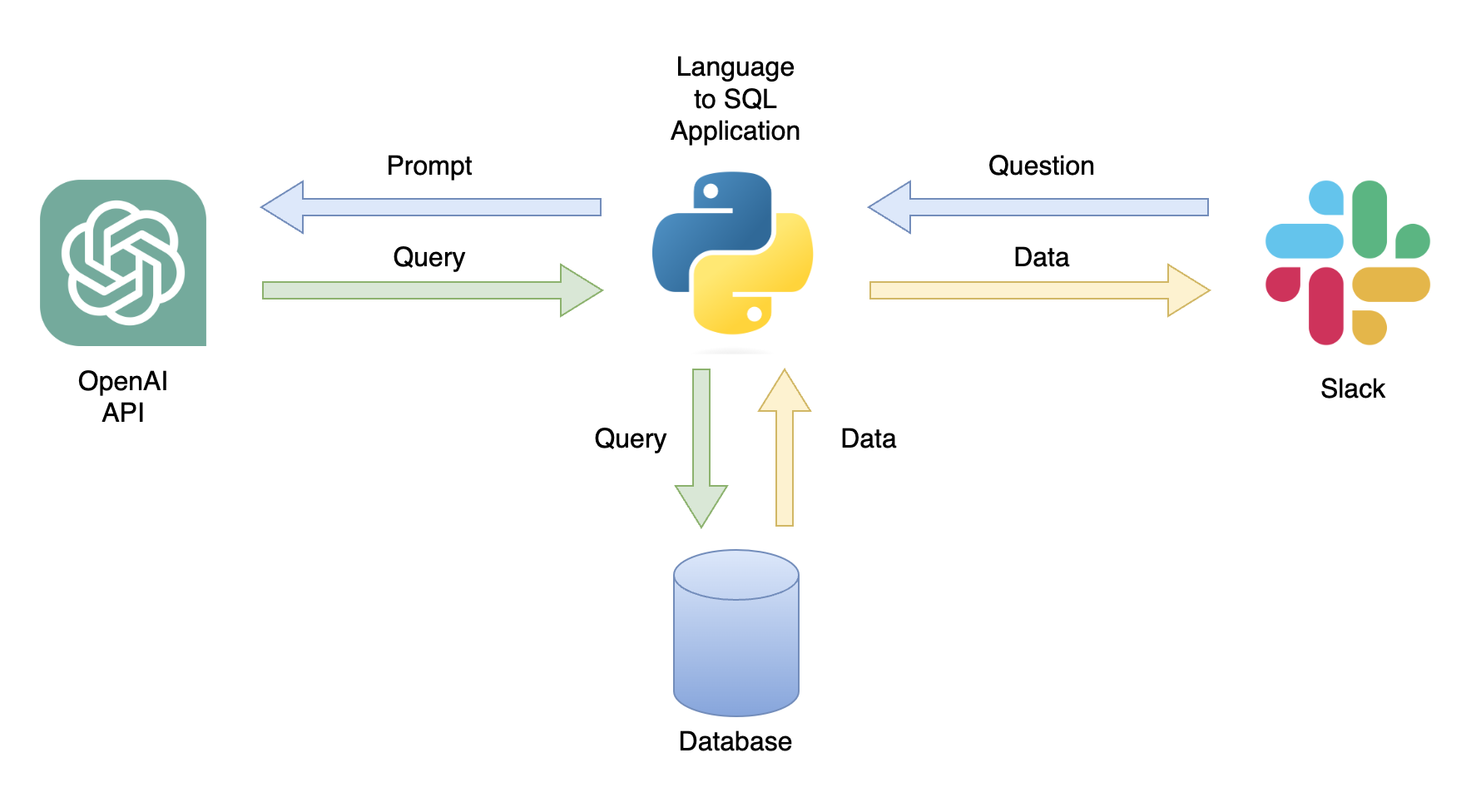
이 튜토리얼에서는 사용자 질문을 SQL 쿼리로 변환하는 단계별 파이썬 응용 프로그램을 작성합니다.
이 자습서는 OpenAI API를 사용하여 일반적인 질문을 SQL 쿼리로 변환하는 파이썬 응용 프로그램을 설정하는 방법에 대한 단계별 안내서를 제공합니다. 여기에는 다음 기능이 포함됩니다.
아래의 그림 2는 SQL 코드 생성기에 대한 간단한 언어의 일반적인 아키텍처를 설명합니다.
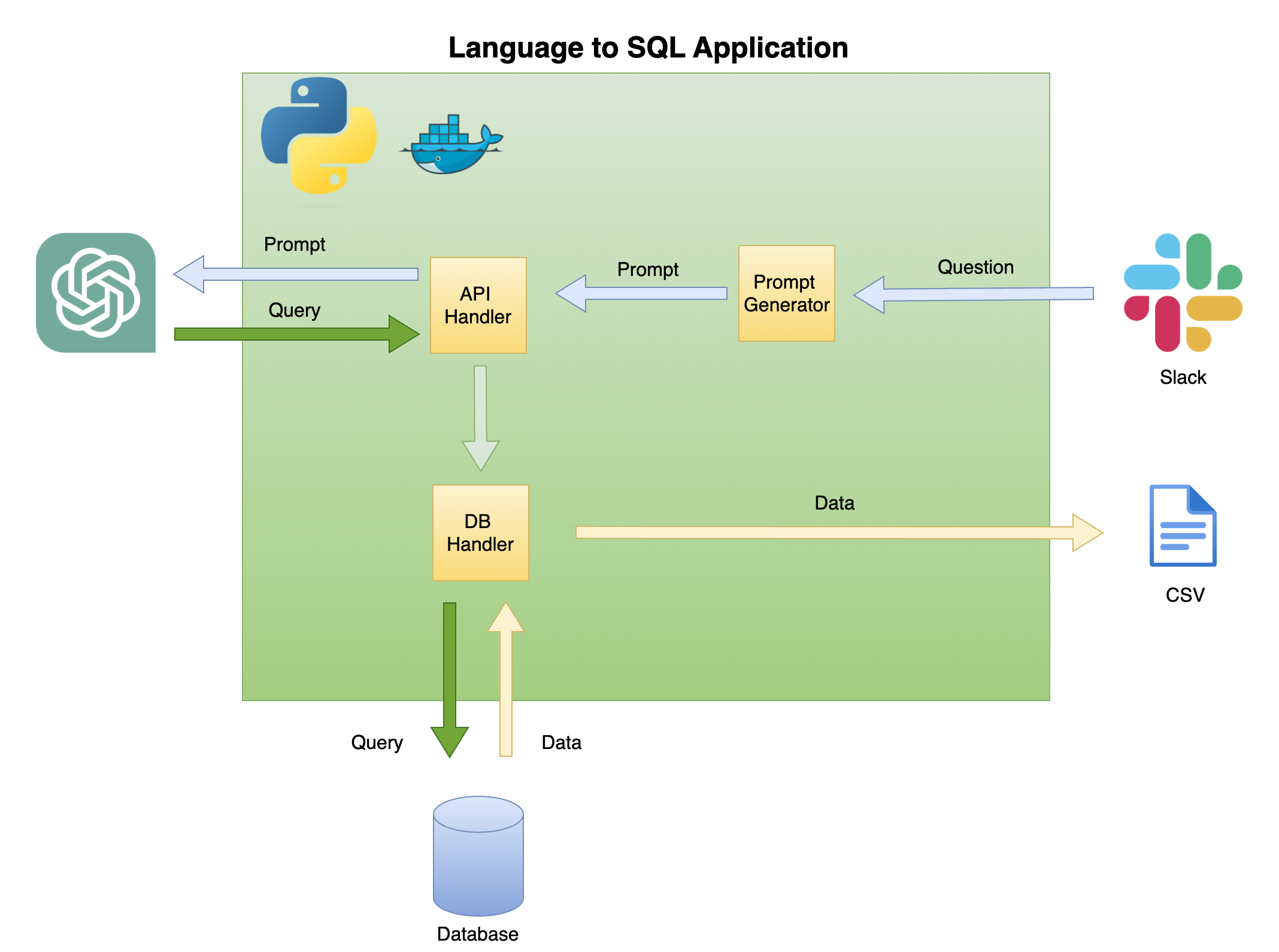
이 튜토리얼의 범위와 초점은 녹색 상자에 있습니다. 다음 기능을 구축합니다.
프롬프트에 대한 질문 - 질문을 신속한 형식으로 변환합니다.
API 핸들러 - OpenAI API와 함께 작동하는 기능 :
DB 핸들러 - SQL 쿼리를 데이터베이스로 보내고 필요한 데이터를 반환하는 함수
이 튜토리얼의 주요 전제 조건은 Python에 대한 기본 지식입니다. 여기에는 다음 기능이 포함됩니다.
또한 SQL에 대한 기본 지식과 OpenAI API에 대한 액세스가 필요합니다.
필요하지는 않지만 Docker에 대한 기본 지식을 갖는 것이 도움이됩니다. 튜토리얼은 VSCODE의 DEV 컨테이너 확장을 사용하여 Dockerized 환경에서 만들어 졌기 때문에 도움이됩니다. Docker 또는 Extension에 대한 경험이없는 경우 가상 환경을 만들고 필요한 라이브러리를 설치하여 튜토리얼을 실행할 수 있습니다 (아래 설명대로). 신속한 엔지니어링 및 OpenAI API에 대한 지식도 유익합니다.
VSCODE 및 DEV 컨테이너 확장으로 Python Dockerized 환경 설정에 대한 자세한 자습서를 만들었습니다.
https://github.com/ramikrispin/vscode-python
자연 언어 대 SQL 코드 생성을 설정하려면 다음 Python 라이브러리를 사용합니다.
pandas - 프로세스 전체에서 데이터를 처리합니다duckdb 데이터베이스로 작업을 시뮬레이션합니다openai OpenAI API와 함께 작업합니다time 및 os CSV 파일 및 형식 필드로드하려면이 저장소에는 VSCODE의 튜토리얼 요구 사항과 DEV 컨테이너 확장 기능을 갖춘 Dockerized 환경을 시작하는 데 필요한 설정이 포함되어 있습니다. 자세한 내용은 다음 섹션에서 확인할 수 있습니다.
또는 사용 가상 환경 섹션의 지침을 사용하여 아래 지침에 따라 가상 환경을 설정하고 튜토리얼 요구 사항을 설치할 수 있습니다.
이 튜토리얼은 VSCODE 및 DEV 컨테이너 확장 기능을 갖춘 대형 환경 내부에서 구축되었습니다. VSCODE로 실행하려면 DEV 컨테이너 확장을 설치하고 Docker Desktop (또는 해당)을 열어야합니다. 환경의 설정은 .devcontainer 폴더에서 사용할 수 있습니다.
.── .devcontainer
├── Dockerfile
├── Dockerfile.dev
├── devcontainer.json
├── install_dependencies_core.sh
├── install_dependencies_other.sh
├── install_quarto.sh
├── requirements_core.txt
├── requirements_openai.txt
└── requirements_transformers.txt
devcontainer.json 에는이 dockerized 환경에 대한 빌드 지침 및 VSCODE 설정이 있습니다.
{
"name" : " lang2sql " ,
"build" : {
"dockerfile" : " Dockerfile " ,
"args" : {
"ENV_NAME" : " lang2sql " ,
"PYTHON_VER" : " 3.10 " ,
"METHOD" : " openai " ,
"QUARTO_VER" : " 1.3.450 "
},
"context" : " . "
},
"customizations" : {
"settings" : {
"python.defaultInterpreterPath" : " /opt/conda/envs/lang2sql/bin/python " ,
"python.selectInterpreter" : " /opt/conda/envs/lang2sql/bin/python "
},
"vscode" : {
"extensions" : [
" quarto.quarto " ,
" ms-azuretools.vscode-docker " ,
" ms-python.python " ,
" ms-vscode-remote.remote-containers " ,
" yzhang.markdown-all-in-one " ,
" redhat.vscode-yaml " ,
" ms-toolsai.jupyter "
]
}
},
"remoteEnv" : {
"OPENAI_KEY" : " ${localEnv:OPENAI_KEY} "
}
}
여기서 build 인수는 docker build 방법을 정의하고 빌드에 대한 인수를 설정합니다. 이 경우 Python 버전을 3.10 으로 설정하고 Conda Virtual Environment를 ang2sql 로 설정했습니다. 이 METHOD 인수는 환경 유형 - openai 정의하여 OpenAI API를 사용 하여이 자습서의 요구 사항 transformers 를 설치하기위한 OpenAI 또는 HuggingFaces API (이 튜토리얼의 범위를 벗어난)를 설정합니다.
remoteEnv 인수는 환경 변수를 설정할 수 있습니다. OpenAI API 키를 설정하는 데 사용합니다. 이 경우 변수를 OPENAI_KEY 로 로컬로 설정하고 localEnv 인수를 사용하여로드하고 있습니다.
VScode 및 Docker를 사용하여 Python 개발 환경 설정에 대해 자세히 알아 보려면이 자습서를 확인하십시오.
튜토리얼 Dockerized 환경을 사용하지 않는 경우 아래 스크립트를 사용하여 명령 줄에서 로컬 가상 환경을 만들 수 있습니다.
ENV_NAME=openai_api
PYTHON_VER=3.10
conda create -y --name $ENV_NAME python= $PYTHON_VER
conda activate $ENV_NAME
pip3 install -r ./.devcontainer/requirements_core.txt
pip3 install -r ./.devcontainer/requirements_openai.txt
참고 : 나는 conda 사용했으며 다른 바이러스 환경 방법과도 잘 작동해야합니다.
우리는 ENV_NAME 및 PYTHON_VER 변수를 사용하여 가상 환경과 Python 버전을 각각 설정합니다.
환경이 올바르게 설정되어 있는지 확인하려면 conda list 사용하여 필요한 파이썬 라이브러리가 설치되어 있는지 확인하십시오. 아래 출력을 기대해야합니다.
(openai_api) root@0ca5b8000cd5:/workspaces/lang2sql# conda list
# packages in environment at /opt/conda/envs/openai_api:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 51_gnu
aiohttp 3.9.0 pypi_0 pypi
aiosignal 1.3.1 pypi_0 pypi
asttokens 2.4.1 pypi_0 pypi
async-timeout 4.0.3 pypi_0 pypi
attrs 23.1.0 pypi_0 pypi
bzip2 1.0.8 hfd63f10_2
ca-certificates 2023.08.22 hd43f75c_0
certifi 2023.11.17 pypi_0 pypi
charset-normalizer 3.3.2 pypi_0 pypi
comm 0.2.0 pypi_0 pypi
contourpy 1.2.0 pypi_0 pypi
cycler 0.12.1 pypi_0 pypi
debugpy 1.8.0 pypi_0 pypi
decorator 5.1.1 pypi_0 pypi
duckdb 0.9.2 pypi_0 pypi
exceptiongroup 1.2.0 pypi_0 pypi
executing 2.0.1 pypi_0 pypi
fonttools 4.45.1 pypi_0 pypi
frozenlist 1.4.0 pypi_0 pypi
gensim 4.3.2 pypi_0 pypi
idna 3.5 pypi_0 pypi
ipykernel 6.26.0 pypi_0 pypi
ipython 8.18.0 pypi_0 pypi
jedi 0.19.1 pypi_0 pypi
joblib 1.3.2 pypi_0 pypi
jupyter-client 8.6.0 pypi_0 pypi
jupyter-core 5.5.0 pypi_0 pypi
kiwisolver 1.4.5 pypi_0 pypi
ld_impl_linux-aarch64 2.38 h8131f2d_1
libffi 3.4.4 h419075a_0
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h998d150_0
matplotlib 3.8.2 pypi_0 pypi
matplotlib-inline 0.1.6 pypi_0 pypi
multidict 6.0.4 pypi_0 pypi
ncurses 6.4 h419075a_0
nest-asyncio 1.5.8 pypi_0 pypi
numpy 1.26.2 pypi_0 pypi
openai 0.28.1 pypi_0 pypi
openssl 3.0.12 h2f4d8fa_0
packaging 23.2 pypi_0 pypi
pandas 2.0.0 pypi_0 pypi
parso 0.8.3 pypi_0 pypi
pexpect 4.8.0 pypi_0 pypi
pillow 10.1.0 pypi_0 pypi
pip 23.3.1 py310hd43f75c_0
platformdirs 4.0.0 pypi_0 pypi
prompt-toolkit 3.0.41 pypi_0 pypi
psutil 5.9.6 pypi_0 pypi
ptyprocess 0.7.0 pypi_0 pypi
pure-eval 0.2.2 pypi_0 pypi
pygments 2.17.2 pypi_0 pypi
pyparsing 3.1.1 pypi_0 pypi
python 3.10.13 h4bb2201_0
python-dateutil 2.8.2 pypi_0 pypi
pytz 2023.3.post1 pypi_0 pypi
pyzmq 25.1.1 pypi_0 pypi
readline 8.2 h998d150_0
requests 2.31.0 pypi_0 pypi
scikit-learn 1.3.2 pypi_0 pypi
scipy 1.11.4 pypi_0 pypi
setuptools 68.0.0 py310hd43f75c_0
six 1.16.0 pypi_0 pypi
smart-open 6.4.0 pypi_0 pypi
sqlite 3.41.2 h998d150_0
stack-data 0.6.3 pypi_0 pypi
threadpoolctl 3.2.0 pypi_0 pypi
tk 8.6.12 h241ca14_0
tornado 6.3.3 pypi_0 pypi
tqdm 4.66.1 pypi_0 pypi
traitlets 5.13.0 pypi_0 pypi
tzdata 2023.3 pypi_0 pypi
urllib3 2.1.0 pypi_0 pypi
wcwidth 0.2.12 pypi_0 pypi
wheel 0.41.2 py310hd43f75c_0
xz 5.4.2 h998d150_0
yarl 1.9.3 pypi_0 pypi
zlib 1.2.13 h998d150_0
OpenAI API를 사용하여 Text-DavInci-003 엔진을 사용하여 Chatgpt에 액세스 할 것입니다. 이를 위해서는 활성 OpenAI 계정 및 API 키가 필요했습니다. 아래 링크의 지침에 따라 계정 및 API 키를 설정하는 것이 간단합니다.
https://openai.com/product
API 및 키에 대한 액세스를 설정하면 .zshrc 파일 (또는 쉘 시스템에 환경 변수를 저장하는 데 사용하는 다른 형식)에 키를 환경 변수로 추가하는 것이 좋습니다. OPENAI_KEY 환경 변수에 API 키를 저장했습니다. 설득력있는 이유로 동일한 명명 규칙을 사용하는 것이 좋습니다.
.zshrc 파일 (또는 동등한)에서 변수를 설정하려면 아래 줄을 파일에 추가하십시오.
export OPENAI_KEY= " YOUR_API_KEY " VSCODE를 사용하거나 터미널에서 실행중인 경우 .zshrc 파일에 변수를 추가 한 후 세션을 다시 시작해야합니다.
데이터베이스 기능을 시뮬레이션하기 위해 시카고 범죄 데이터 세트를 사용합니다. 이 데이터 세트는 2001 년부터 시카고시에 기록 된 범죄에 관한 심층적 인 정보를 제공합니다. 8 백만 개의 기록과 22 개의 열이있는 데이터 세트에는 범죄 분류, 위치, 시간, 결과 등과 같은 정보가 포함되어 있습니다. 데이터는 시카고 데이터 포털에서 다운로드 할 수 있습니다. 데이터를 Pandas 데이터 프레임으로 로컬로 저장하고 DuckDB를 사용하여 SQL 쿼리를 시뮬레이션하므로 지난 3 년 동안 데이터의 하위 집합을 다운로드합니다.
API에서 데이터를 가져 오거나 CSV 파일을 다운로드 할 수 있습니다. 스크립트를 실행할 때마다 API를 호출하지 않도록 파일을 다운로드하여 데이터 폴더 아래에 저장합니다. 다음은 해마다 데이터 세트에 대한 링크입니다.
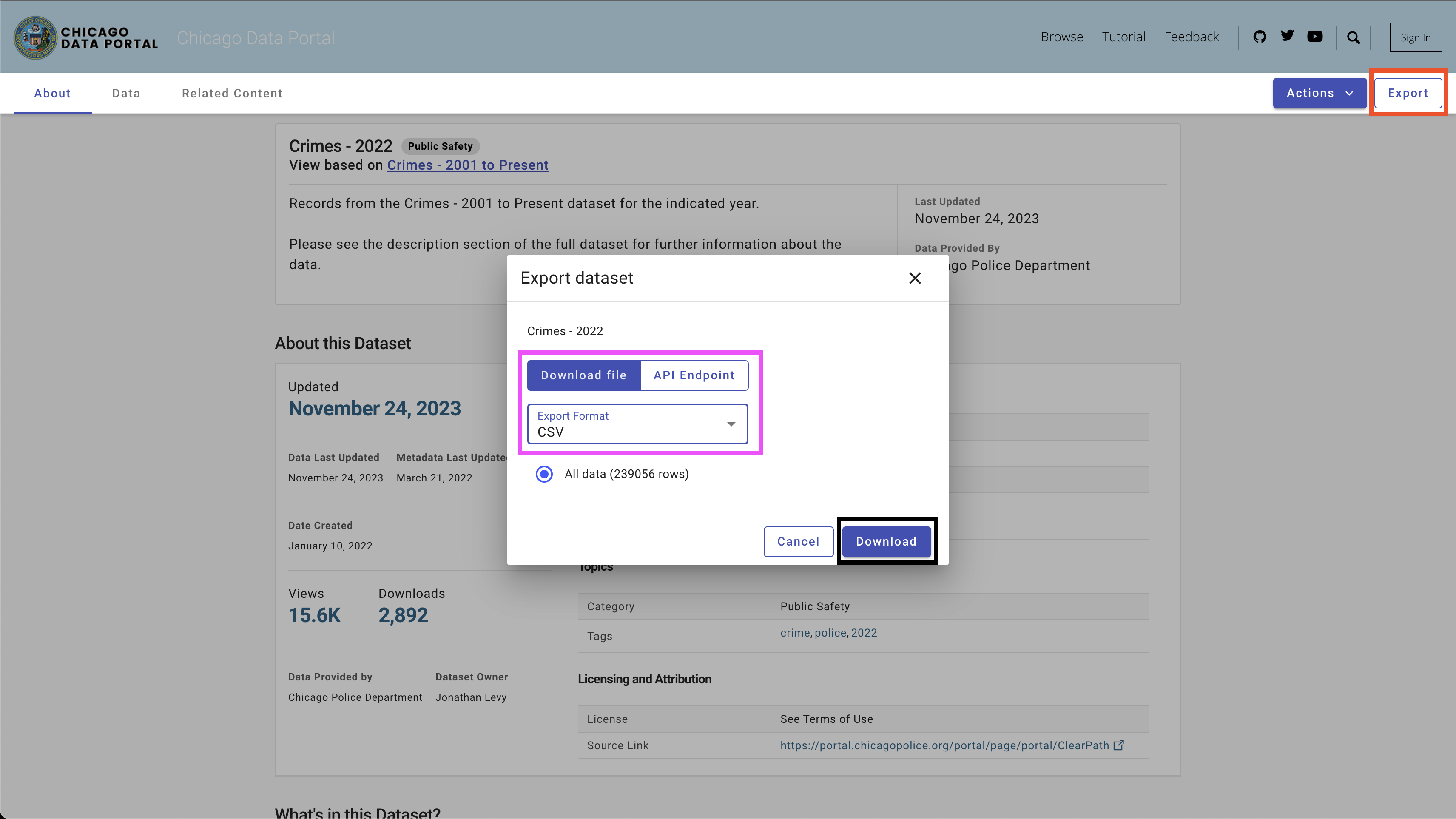
데이터를 다운로드하려면 오른쪽 상단의 Export 버튼을 사용하고 CSV 옵션을 선택하고 그림 4에서 볼 수 있듯이 Download 버튼을 클릭하십시오.
다음 이름 지정 컨벤션을 사용했습니다 -Chicago_crime_year.csv는 파일을 data 폴더에 저장했습니다. 각 파일 크기는 50MB에 가깝습니다. 따라서 data 폴더 아래에서 Git 무시 파일에 추가 했으며이 리포지토리에서 사용할 수 없습니다. 파일을 다운로드하고 이름을 설정 한 후 폴더에 다음 파일이 있어야합니다.
| ── data
├── chicago_crime_2021.csv
├── chicago_crime_2022.csv
└── chicago_crime_2023.csv
참고 : 이 튜토리얼을 작성하는시기에 2023의 데이터가 여전히 업데이트되고 있습니다. 따라서 다음 섹션에서 일부 쿼리를 실행할 때 약간 다른 결과를 얻을 수 있습니다.
SQL 코드 생성기를 설정하는 흥미로운 부분으로 넘어 갑시다. 이 섹션에서는 사용자의 질문, 관련 SQL 테이블 및 OpenAI API 키를 취하는 Python 함수를 생성하고 사용자의 질문에 답변하는 SQL 쿼리를 출력합니다.
시카고 범죄 데이터 세트와 필요한 파이썬 라이브러리를로드하여 시작하겠습니다.
먼저 - 필요한 파이썬 라이브러리를로드합시다.
import pandas as pd
import duckdb
import openai
import time
import os우리는 OS 및 시간 라이브러리를 사용하여 CSV 파일을로드하고 특정 필드를 개혁합니다. 데이터는 Pandas 라이브러리를 사용하여 처리되며 DuckDB 라이브러리로 SQL 명령을 시뮬레이션합니다. 마지막으로 OpenAI 라이브러리를 사용하여 OpenAI API에 연결됩니다.
다음으로 데이터 폴더에서 CSV 파일을로드합니다. 아래 코드는 데이터 폴더에서 사용 가능한 모든 CSV 파일을 읽습니다.
path = "./data"
files = [ x for x in os . listdir ( path = path ) if ".csv" in x ]2021 년에서 2023 년 동안 해당 파일을 다운로드하고 동일한 이름 지정 컨벤션을 사용한 경우 다음 출력이 예상됩니다.
print ( files )
[ 'chicago_crime_2022.csv' , 'chicago_crime_2023.csv' , 'chicago_crime_2021.csv' ]다음으로 모든 파일을 읽고로드하여 Pandas 데이터 프레임에 추가합니다.
chicago_crime = pd . concat (( pd . read_csv ( path + "/" + f ) for f in files ), ignore_index = True )
chicago_crime . head파일을 올바르게로드 한 경우 다음 출력이 예상됩니다.
< bound method NDFrame . head of ID Case Number Date Block
0 12589893 JF109865 01 / 11 / 2022 03 : 00 : 00 PM 087 XX S KINGSTON AVE
1 12592454 JF113025 01 / 14 / 2022 03 : 55 : 00 PM 067 XX S MORGAN ST
2 12601676 JF124024 01 / 13 / 2022 04 : 00 : 00 PM 031 XX W AUGUSTA BLVD
3 12785595 JF346553 08 / 05 / 2022 09 : 00 : 00 PM 072 XX S UNIVERSITY AVE
4 12808281 JF373517 08 / 14 / 2022 02 : 00 : 00 PM 055 XX W ARDMORE AVE
... ... ... ... ...
648826 26461 JE455267 11 / 24 / 2021 12 : 51 : 00 AM 107 XX S LANGLEY AVE
648827 26041 JE281927 06 / 28 / 2021 01 : 12 : 00 AM 117 XX S LAFLIN ST
648828 26238 JE353715 08 / 29 / 2021 03 : 07 : 00 AM 010 XX N LAWNDALE AVE
648829 26479 JE465230 12 / 03 / 2021 08 : 37 : 00 PM 000 XX W 78 TH PL
648830 11138622 JA495186 05 / 21 / 2021 12 : 01 : 00 AM 019 XX N PULASKI RD
IUCR Primary Type
0 1565 SEX OFFENSE
1 2826 OTHER OFFENSE
2 1752 OFFENSE INVOLVING CHILDREN
3 1544 SEX OFFENSE
4 1562 SEX OFFENSE
... ... ...
648826 0110 HOMICIDE
648827 0110 HOMICIDE
648828 0110 HOMICIDE
648829 0110 HOMICIDE
648830 1752 OFFENSE INVOLVING CHILDREN
...
648828 41.899709 - 87.718893 ( 41.899709327 , - 87.718893208 )
648829 41.751832 - 87.626374 ( 41.751831742 , - 87.626373808 )
648830 41.915798 - 87.726524 ( 41.915798196 , - 87.726524412 ) 참고 : 이 튜토리얼을 만들 때 2023 년의 부분 데이터를 사용할 수있었습니다. 세 파일을 추가하면 표시된 것보다 더 많은 행이 생깁니다 (648830 행).
파이썬 코드에 들어가기 전에 프롬프트 엔지니어링이 어떻게 작동하는지, Chatgpt (및 일반적으로 모든 LLM)가 최상의 결과를 생성하는 방법을 잠시 멈추고 검토합시다. 이 섹션에서는 Chatgpt 웹 인터페이스를 사용할 것입니다.
통계 및 기계 학습 모델의 주요 요인 중 하나는 출력 품질이 입력 품질에 따라 다르다는 것입니다. 유명한 문구가 말했듯이 정크 인, 정크 아웃 . 마찬가지로 LLM 출력의 품질은 프롬프트의 품질에 따라 다릅니다.
예를 들어, 체포로 끝나는 사례의 수를 세고 싶다고 가정 해 봅시다.
다음 프롬프트를 사용하는 경우 :
Create an SQL query that counts the number of records that ended up with an arrest.
다음은 chatgpt의 출력입니다.
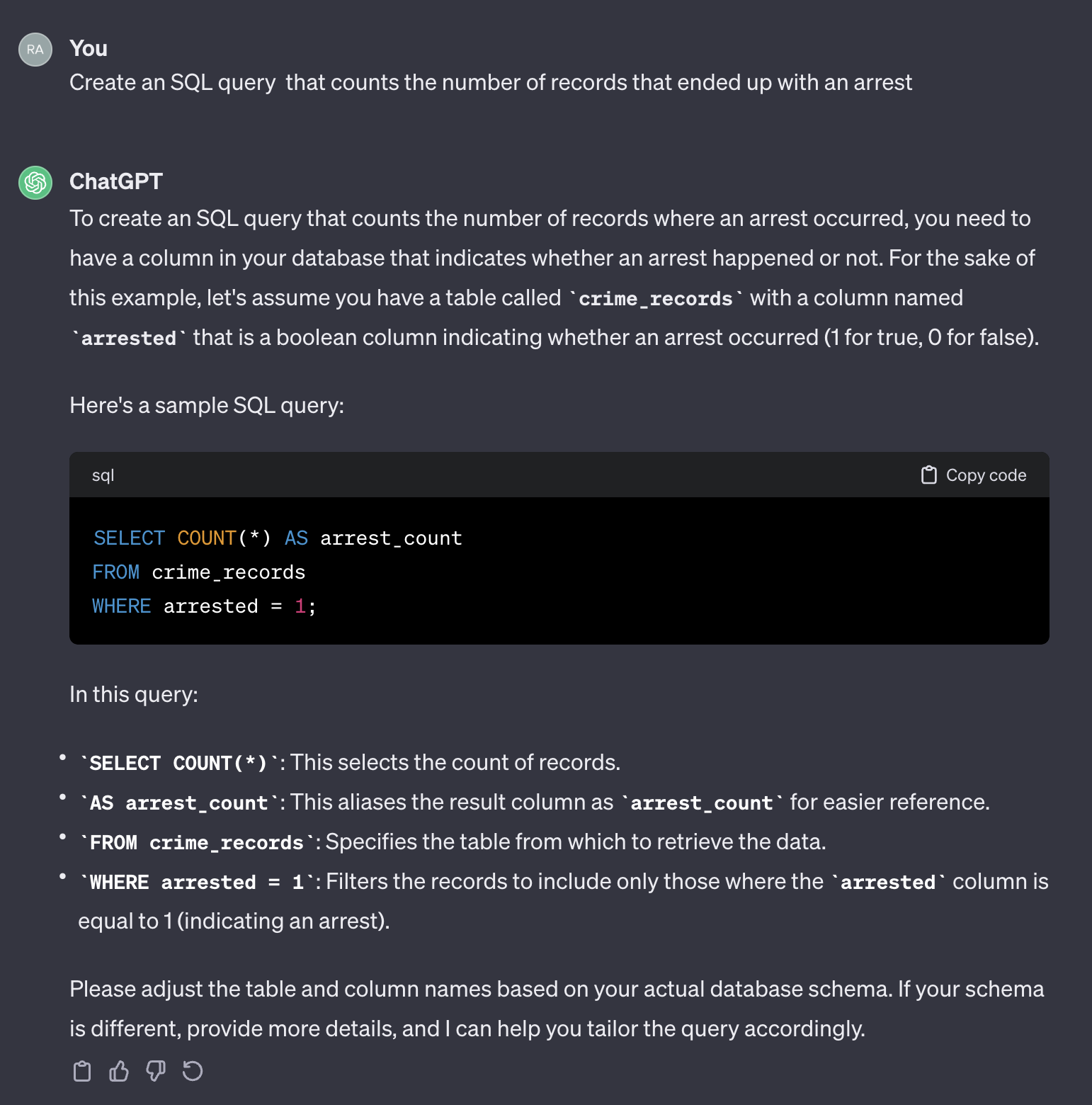
Chatgpt가 일반적인 응답을 제공한다는 점은 주목할 가치가 있습니다. 일반적으로 정확하지만 자동화 된 프로세스에서 사용하는 것은 실용적이지 않을 수 있습니다. 첫째, 응답의 필드 이름은 쿼리 해야하는 실제 테이블의 이름과 일치하지 않습니다. 둘째, 체포 결과를 나타내는 분야는 정수 ( 0 또는 1 ) 대신 부울 ( true 또는 false )입니다.
그런 의미에서 Chatgpt는 인간처럼 행동합니다. Stack Overflow 또는 다른 유사한 플랫폼과 같은 코딩 양식에 동일한 질문을 게시하여 사람으로부터 더 정확한 답변을받을 것 같지 않습니다. 테이블 특성에 대한 컨텍스트 나 추가 정보를 제공하지 않았기 때문에 Chatgpt가 필드 이름을 추측 할 것으로 예상하면 그 값이 불합리 할 것으로 기대합니다. 컨텍스트는 모든 프롬프트에서 중요한 요소입니다. 이 점을 설명하기 위해 Chatgpt가 다음 프롬프트를 어떻게 처리하는지 살펴 보겠습니다.
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
I want to create an SQL query that counts the number of records that ended up with an arrest.
다음은 chatgpt의 출력입니다.
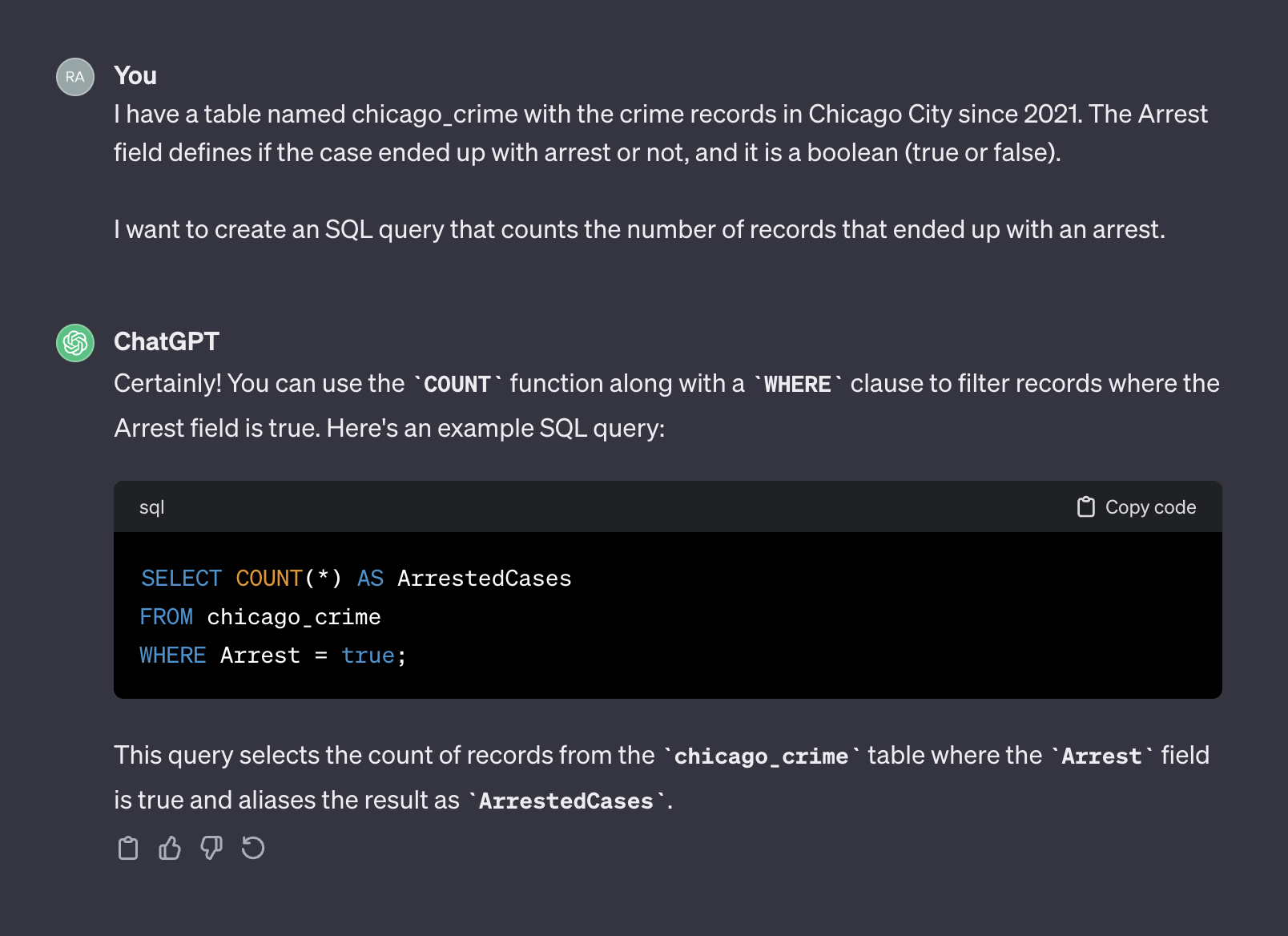
이번에는 컨텍스트를 추가 한 후 Chatgpt는 우리가 사용할 수있는 올바른 쿼리를 반환했습니다. 일반적으로 텍스트 생성기로 작업 할 때 프롬프트에는 컨텍스트와 요청의 두 가지 구성 요소가 포함되어야합니다. 위의 프롬프트에서 첫 번째 단락은 프롬프트의 컨텍스트를 나타냅니다.
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
두 번째 단락은 요청을 나타냅니다.
I want to create an SQL query that counts the number of records that ended up with an arrest.
OpenAI API는 컨텍스트를 system 으로, user 로서 요청합니다.
OpenAI API 문서는 SQL 코드를 생성하도록 요청할 때 system 및 user 구성 요소를 프롬프트로 설정하는 방법에 대한 권장 사항을 제공합니다.
System
Given the following SQL tables, your job is to write queries given a user’s request.
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
CREATE TABLE OrderDetails (
OrderDetailID int,
OrderID int,
ProductID int,
Quantity int,
PRIMARY KEY (OrderDetailID)
);
CREATE TABLE Products (
ProductID int,
ProductName varchar(50),
Category varchar(50),
UnitPrice decimal(10, 2),
Stock int,
PRIMARY KEY (ProductID)
);
CREATE TABLE Customers (
CustomerID int,
FirstName varchar(50),
LastName varchar(50),
Email varchar(100),
Phone varchar(20),
PRIMARY KEY (CustomerID)
);
User
Write a SQL query which computes the average total order value for all orders on 2023-04-01.
다음 섹션에서는 위의 OpenAI 예제를 사용하여 일반 목적 템플릿으로 일반화합니다.
이전 섹션에서는 신속한 엔지니어링의 중요성과 좋은 맥락을 제공하면 LLM 응답 정확도를 향상시킬 수있는 방법에 대해 논의했습니다. 또한 SQL 코드 생성에 대한 OpenAI 권장 프롬프트 구조를 보았습니다. 이 섹션에서는 이러한 원칙을 기반으로 SQL 생성을위한 프롬프트를 만드는 과정을 일반화하는 데 중점을 둘 것입니다. 목표는 테이블 이름과 사용자 질문을 수신하고 그에 따라 프롬프트를 생성하는 Python 함수를 구축하는 것입니다. 예를 들어, 우리가 이전에로드 한 테이블 chicago_crime 테이블의 경우, 이전 섹션에서 요청한 질문은 다음과 같은 프롬프트를 생성해야합니다.
Given the following SQL table, your job is to write queries given a user’s request.
CREATE TABLE chicago_crime (ID BIGINT, Case Number VARCHAR, Date VARCHAR, Block VARCHAR, IUCR VARCHAR, Primary Type VARCHAR, Description VARCHAR, Location Description VARCHAR, Arrest BOOLEAN, Domestic BOOLEAN, Beat BIGINT, District BIGINT, Ward DOUBLE, Community Area BIGINT, FBI Code VARCHAR, X Coordinate DOUBLE, Y Coordinate DOUBLE, Year BIGINT, Updated On VARCHAR, Latitude DOUBLE, Longitude DOUBLE, Location VARCHAR)
Write a SQL query that returns - How many cases ended up with arrest?
프롬프트 구조부터 시작하겠습니다. OpenAI 형식을 채택하고 다음 템플릿을 사용합니다.
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}" system_template 두 가지 요소를 받았습니다.
이 튜토리얼의 경우 DuckDB 라이브러리를 사용하여 Pandas의 데이터 프레임을 SQL 테이블이므로 duckdb.sql 기능을 사용하여 테이블의 필드 이름 및 속성을 추출합니다. 예를 들어, DESCRIBE SQL 명령을 사용하여 chicago_crime 테이블 필드 정보를 추출하겠습니다.
duckdb . sql ( "DESCRIBE SELECT * FROM chicago_crime;" )아래 표를 반환해야합니다.
┌──────────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├──────────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ ID │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Case Number │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Date │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Block │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ IUCR │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Primary Type │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Location Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Arrest │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Domestic │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Beat │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ District │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Ward │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Community Area │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ FBI Code │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ X Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Y Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Year │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Updated On │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Latitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Longitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Location │ VARCHAR │ YES │ NULL │ NULL │ NULL │
├──────────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┤
│ 22 rows 6 columns │
└────────────────────────────────────────────────────────────────────────────┘참고 : 필요한 정보 - 열 이름과 속성은 처음 두 열에서 사용할 수 있습니다. 그러므로 우리는 그 열을 구문 분석하고 다음과 함께 다음 형식으로 결합해야합니다.
Column_Name Column_Attribute
예를 들어, Case Number 열은 다음 형식으로 전송되어야합니다.
Case Number VARCHAR
아래의 create_message 함수는 위의 논리를 사용하여 테이블 이름과 질문을 취하고 프롬프트를 생성하는 프로세스를 오케스트레이션합니다.
def create_message ( table_name , query ):
class message :
def __init__ ( message , system , user , column_names , column_attr ):
message . system = system
message . user = user
message . column_names = column_names
message . column_attr = column_attr
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}"
tbl_describe = duckdb . sql ( "DESCRIBE SELECT * FROM " + table_name + ";" )
col_attr = tbl_describe . df ()[[ "column_name" , "column_type" ]]
col_attr [ "column_joint" ] = col_attr [ "column_name" ] + " " + col_attr [ "column_type" ]
col_names = str ( list ( col_attr [ "column_joint" ]. values )). replace ( '[' , '' ). replace ( ']' , '' ). replace ( ' ' ' , '' )
system = system_template . format ( table_name , col_names )
user = user_template . format ( query )
m = message ( system = system , user = user , column_names = col_attr [ "column_name" ], column_attr = col_attr [ "column_type" ])
return m 함수는 프롬프트 템플릿을 생성하고 프롬프트 system 및 user 구성 요소 및 열 이름 및 속성을 반환합니다. 예를 들어, 체포 질문 수를 실행하겠습니다.
query = "How many cases ended up with arrest?"
msg = create_message ( table_name = "chicago_crime" , query = query )이것은 돌아올 것입니다 :
print ( msg . system )
Given the following SQL table , your job is to write queries given a user ’ s request .
CREATE TABLE chicago_crime ( ID BIGINT , Case Number VARCHAR , Date VARCHAR , Block VARCHAR , IUCR VARCHAR , Primary Type VARCHAR , Description VARCHAR , Location Description VARCHAR , Arrest BOOLEAN , Domestic BOOLEAN , Beat BIGINT , District BIGINT , Ward DOUBLE , Community Area BIGINT , FBI Code VARCHAR , X Coordinate DOUBLE , Y Coordinate DOUBLE , Year BIGINT , Updated On VARCHAR , Latitude DOUBLE , Longitude DOUBLE , Location VARCHAR )
print ( msg . user )
Write a SQL query that returns - How many cases ended up with arrest ?
print ( msg . column_names )
0 ID
1 Case Number
2 Date
3 Block
4 IUCR
5 Primary Type
6 Description
7 Location Description
8 Arrest
9 Domestic
10 Beat
11 District
12 Ward
13 Community Area
14 FBI Code
15 X Coordinate
16 Y Coordinate
17 Year
18 Updated On
19 Latitude
20 Longitude
21 Location
Name : column_name , dtype : object
print ( msg . column_attr )
0 BIGINT
1 VARCHAR
2 VARCHAR
3 VARCHAR
4 VARCHAR
5 VARCHAR
6 VARCHAR
7 VARCHAR
8 BOOLEAN
9 BOOLEAN
10 BIGINT
11 BIGINT
12 DOUBLE
13 BIGINT
14 VARCHAR
15 DOUBLE
16 DOUBLE
17 BIGINT
18 VARCHAR
19 DOUBLE
20 DOUBLE
21 VARCHAR
Name : column_type , dtype : object create_message 함수의 출력은 OpenAI API ChatCompletion.create 기능 인수에 맞게 설계되었으며 다음 섹션에서 검토합니다.
이 섹션은 OpenAi Python 라이브러리 기능에 중점을 둡니다. OpenAI 라이브러리를 사용하면 OpenAI REST API에 완벽하게 액세스 할 수 있습니다. 라이브러리를 사용하여 API에 연결하고 프롬프트와 함께 GET 요청을 보냅니다.
API를 openai.api_key 함수에 공급하여 API에 연결하여 시작하겠습니다.
openai . api_key = os . getenv ( 'OPENAI_KEY' ) 참고 : os 라이브러리의 getenv 함수를 사용하여 OpenAI_Key 환경 변수를로드했습니다. 또는 API 키를 직접 공급할 수 있습니다.
openai . api_key = "YOUR_OPENAI_API_KEY"OpenAI API는 기능이 다른 다양한 LLM에 대한 액세스를 제공합니다. OpenAi.Model.list 함수를 사용하여 사용 가능한 모델 목록을 얻을 수 있습니다.
openai . Model . list () 좋은 형식으로 변환하려면 pandas 데이터 프레임으로 랩핑 할 수 있습니다.
openai_api_models = pd . DataFrame ( openai . Model . list ()[ "data" ])
openai_api_models . head다음과 같은 출력을 기대해야합니다.
<bound method NDFrame.head of id object created owned_by
0 text-search-babbage-doc-001 model 1651172509 openai-dev
1 gpt-4 model 1687882411 openai
2 curie-search-query model 1651172509 openai-dev
3 text-davinci-003 model 1669599635 openai-internal
4 text-search-babbage-query-001 model 1651172509 openai-dev
.. ... ... ... ...
65 gpt-3.5-turbo-instruct-0914 model 1694122472 system
66 dall-e-2 model 1698798177 system
67 tts-1-1106 model 1699053241 system
68 tts-1-hd-1106 model 1699053533 system
69 gpt-3.5-turbo-16k model 1683758102 openai-internal
[70 rows x 4 columns]>
유스 케이스, 텍스트 생성의 경우 GPT3 모델의 개선 인 gpt-3.5-turbo 모델을 사용합니다. gpt-3.5-turbo 모델은 계속 업데이트되는 일련의 모델을 나타냅니다. 기본적으로 모델 버전을 지정하지 않으면 API는 가장 최근의 안정적인 릴리스를 지적합니다. 이 튜토리얼을 만들 때 기본 3.5 모델은 4,096 개의 토큰을 사용하여 gpt-3.5-turbo-0613 으로 2021 년 9 월까지 데이터로 교육했습니다.
프롬프트와 함께 GET 요청을 보내려면 ChatCompletion.create 기능을 사용합니다. 이 기능에는 많은 주장이 있으며 다음은 다음과 같습니다.
model - 사용할 모델 ID, 여기에서 사용할 수있는 전체 목록messages - 지금까지 대화를 포함하는 메시지 목록 (예 : 프롬프트)temperature - 샘플링 온도 수준을 설정하여 공정 출력의 무작위성 또는 결정론을 관리합니다. 온도 수준은 0과 2 사이의 값을 허용합니다. 인수 값이 높으면 출력이 더 무작위로됩니다. 반대로, 인수 값이 0에 가까워지면 출력은 더 결정적이됩니다 (재현 가능).max_tokens 완료시 생성 할 최대 토큰 수API Documenton에서 사용 가능한 함수 인수의 전체 목록.
아래 예제에서는 이번에 API를 사용하여 ChatGpt 웹 인터페이스 (예 : 그림 5)에 사용 된 것과 동일한 프롬프트를 사용합니다. create_message 함수로 프롬프트를 생성합니다.
query = "How many cases ended up with arrest?"
prompt = create_message ( table_name = "chicago_crime" , query = query ) 위의 프롬프트를 ChatCompletion.create 의 구조로 변환합시다. 기능 messages 작성 인수 :
message = [
{
"role" : "system" ,
"content" : prompt . system
},
{
"role" : "user" ,
"content" : prompt . user
}
] 다음으로 ChatCompletion.create function을 사용하여 프롬프트 (즉, message 객체)를 API로 보냅니다.
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
messages = message ,
temperature = 0 ,
max_tokens = 256 ) 우리는 temperature 인수를 0으로 설정하고 텍스트 완료의 토큰 수를 256으로 제한합니다. 함수는 텍스트 완료, 메타 데이터 및 기타 정보로 JSON 객체를 반환합니다.
print ( response )
< OpenAIObject chat . completion id = chatcmpl - 8 PzomlbLrTOTx1uOZm4WQnGr4JwU7 at 0xffff4b0dcb80 > JSON : {
"id" : "chatcmpl-8PzomlbLrTOTx1uOZm4WQnGr4JwU7" ,
"object" : "chat.completion" ,
"created" : 1701206520 ,
"model" : "gpt-3.5-turbo-0613" ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : "assistant" ,
"content" : "SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true;"
},
"finish_reason" : "stop"
}
],
"usage" : {
"prompt_tokens" : 137 ,
"completion_tokens" : 12 ,
"total_tokens" : 149
}
}응답 인디를 사용하여 SQL 쿼리를 추출 할 수 있습니다.
sql = response [ "choices" ][ 0 ][ "message" ][ "content" ]
print ( sql ) ' SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true; ' duckdb.sql 함수를 사용하여 SQL 코드를 실행합니다.
duckdb . sql ( sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘다음 섹션에서는 모든 단계를 일반화하고 기능합니다.
이전 섹션에서는 프롬프트 형식을 도입하고 create_message 함수를 설정하고 ChatCompletion.create 함수의 기능을 검토했습니다. 이 섹션에서는 모두 함께 꿰매겠습니다.
ChatCompletion.create 기능에서 반환 된 SQL 코드에 대해 주목해야 할 한 가지는 변수가 따옴표와 함께 반환되지 않는다는 것입니다. 쿼리의 변수 이름이 두 개 이상의 단어를 결합한 경우 문제 일 수 있습니다. 예를 들어, 따옴표를 사용하지 않고 쿼리 내부의 chicago_crime 의 Case Number 또는 Primary Type 과 같은 변수를 사용하면 오류가 발생합니다.
반환 된 쿼리에 쿼리가없는 경우 아래의 도우미 기능을 사용하여 쿼리의 변수에 따옴표를 추가합니다.
def add_quotes ( query , col_names ):
for i in col_names :
if i in query :
l = query . find ( i )
if query [ l - 1 ] != "'" and query [ l - 1 ] != '"' :
query = str ( query ). replace ( i , '"' + i + '"' )
return ( query ) 함수 입력은 쿼리와 해당 테이블의 열 이름입니다. 열 이름을 반복하고 쿼리 내에서 일치하는 경우 인용문을 추가합니다. 예를 들어, ChatCompletion.create 기능 출력에서 구문 분석 한 SQL 쿼리로 실행할 수 있습니다.
add_quotes ( query = sql , col_names = prompt . column_names )
'SELECT COUNT(*) FROM chicago_crime WHERE "Arrest" = true;' Arrest 변수에 인용문이 추가된다는 것을 알 수 있습니다.
이제 지금까지 소개 한 세 create_message 기능을 활용하는 lang2sql 기능을 소개 ChatCompletion.create 수 add_quotes .
def lang2sql ( api_key , table_name , query , model = "gpt-3.5-turbo" , temperature = 0 , max_tokens = 256 , frequency_penalty = 0 , presence_penalty = 0 ):
class response :
def __init__ ( output , message , response , sql ):
output . message = message
output . response = response
output . sql = sql
openai . api_key = api_key
m = create_message ( table_name = table_name , query = query )
message = [
{
"role" : "system" ,
"content" : m . system
},
{
"role" : "user" ,
"content" : m . user
}
]
openai_response = openai . ChatCompletion . create (
model = model ,
messages = message ,
temperature = temperature ,
max_tokens = max_tokens ,
frequency_penalty = frequency_penalty ,
presence_penalty = presence_penalty )
sql_query = add_quotes ( query = openai_response [ "choices" ][ 0 ][ "message" ][ "content" ], col_names = m . column_names )
output = response ( message = m , response = openai_response , sql = sql_query )
return output 함수는 입력, OpenAI API 키, 테이블 이름 및 ChatCompletion.create 의 핵심 매개 변수를 수신합니다. 예를 들어, lang2sql 함수와 함께 이전 섹션에서 사용한 것과 동일한 쿼리를 다시 실행 해 보겠습니다.
query = "How many cases ended up with arrest?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )출력 객체에서 SQL 쿼리를 추출 할 수 있습니다.
print ( response . sql ) SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = true;이전 섹션에서받은 결과와 관련하여 출력을 테스트 할 수 있습니다.
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘이제 질문에 추가 복잡성을 추가하고 2022 년에 체포 된 사례를 요청합시다.
query = "How many cases ended up with arrest during 2022"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query ) 보시다시피, 모델은 Year 관련 필드를 올바르게 식별하고 올바른 쿼리를 생성했습니다.
print ( response . sql )SQL 코드 :
SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = TRUE AND " Year " = 2022 ;테이블의 쿼리 테스트 :
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 27805 │
└──────────────┘다음은 특정 변수 별 그룹화가 필요한 간단한 질문의 예입니다.
query = "Summarize the cases by primary type"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )응답 출력 에서이 경우 SQL 코드가 정확하다는 것을 알 수 있습니다.
SELECT " Primary Type " , COUNT ( * ) as TotalCases
FROM chicago_crime
GROUP BY " Primary Type "이것은 쿼리의 출력입니다.
duckdb . sql ( response . sql ). show ()
┌───────────────────────────────────┬────────────┐
│ Primary Type │ TotalCases │
│ varchar │ int64 │
├───────────────────────────────────┼────────────┤
│ MOTOR VEHICLE THEFT │ 54934 │
│ ROBBERY │ 25082 │
│ WEAPONS VIOLATION │ 24672 │
│ INTERFERENCE WITH PUBLIC OFFICER │ 1161 │
│ OBSCENITY │ 127 │
│ STALKING │ 1206 │
│ BATTERY │ 115760 │
│ OFFENSE INVOLVING CHILDREN │ 5177 │
│ CRIMINAL TRESPASS │ 11255 │
│ PUBLIC PEACE VIOLATION │ 1980 │
│ · │ · │
│ · │ · │
│ · │ · │
│ ASSAULT │ 58685 │
│ CRIMINAL DAMAGE │ 75611 │
│ DECEPTIVE PRACTICE │ 46377 │
│ NARCOTICS │ 13931 │
│ BURGLARY │ 19898 │
...
├───────────────────────────────────┴────────────┤
│ 31 rows ( 20 shown ) 2 columns │
└────────────────────────────────────────────────┘마지막으로, LLM은 부분 변수 이름을 제공 할 때에도 컨텍스트 (예 : 변수)를 식별 할 수 있습니다.
query = "How many cases is the type of robbery?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )아래 SQL 코드를 반환합니다.
SELECT COUNT ( * ) FROM chicago_crime WHERE " Primary Type " = ' ROBBERY ' ;이것은 쿼리의 출력입니다.
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 25082 │
└──────────────┘이 튜토리얼에서는 몇 줄의 파이썬 코드로 SQL 코드 생성기를 빌드하고 OpenAI API를 활용하는 방법을 보여주었습니다. 결과 SQL 코드의 성공에 프롬프트의 품질이 중요하다는 것을 알았습니다. 프롬프트가 제공 한 컨텍스트 외에도 필드 이름은 LLM이 필드의 관련성을 사용자 질문과 식별 할 수 있도록 필드의 특성에 대한 정보를 제공해야합니다.
이 튜토리얼은 단일 테이블 (예 : 테이블 사이의 결합 없음)으로 작업하는 것으로 제한되었지만 OpenAI에서 사용 가능한 LLM과 같은 일부 LLM은 여러 테이블 작업 및 올바른 조인 작업을 식별하는 등보다 복잡한 경우를 처리 할 수 있습니다. 여러 테이블을 처리하도록 LANG2SQL 기능을 조정하는 것이 다음 단계가 될 수 있습니다.
이 튜토리얼은 Creative Commons Attribution-Noncommercial Sharealike 4.0 International 라이센스에 따라 라이센스가 부여됩니다.


