nlpaug
Release 1.1.11

이 파이썬 라이브러리는 기계 학습 프로젝트를위한 NLP를 확대하는 데 도움이됩니다. NLP의 데이터 확대에 대해 이해하려면이 소개를 방문하십시오. Augmenter 는 증강의 기본 요소이며 Flow 오케스트라 다중 증강기의 파이프 라인입니다.
| 부분 | 설명 |
|---|---|
| 빠른 데모 | 이 라이브러리를 사용하는 방법 |
| 증강기 | 사용 가능한 모든 증강 방법을 소개하십시오 |
| 설치 | 이 라이브러리를 설치하는 방법 |
| 최근 변경 | 최신 향상 |
| 확장 판독 | 더 많은 실제 사례 또는 연구 |
| 참조 | 데이터 또는 모델과 같은 외부 리소스 참조 |
| 증강기 | 목표 | 증강기 | 행동 | 설명 |
|---|---|---|---|---|
| 텍스트 | 성격 | 키보드 | 대리자 | 키보드 거리 오류를 시뮬레이션합니다 |
| 텍스트 | Ocraug | 대리자 | OCR 엔진 오류를 시뮬레이션합니다 | |
| 텍스트 | Randomaug | 삽입, 대체, 스왑, 삭제 | 증강을 무작위로 적용하십시오 | |
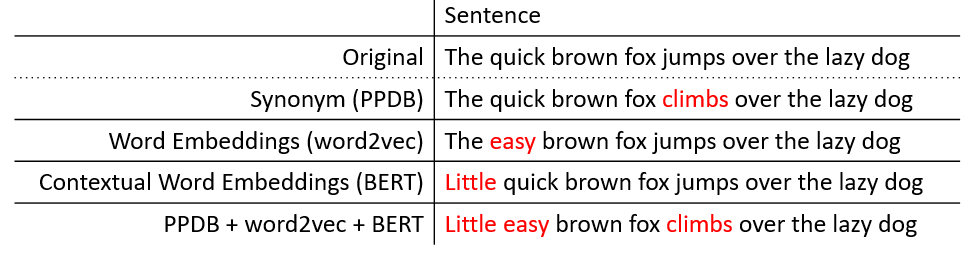
| 텍스트 | 단어 | Antonymaug | 대리자 | Wordnet Antonym에 따른 반대 의미 단어를 대체하십시오 |
| 텍스트 | Contextualwordembsaug | 삽입, 대체 | Bert, Distilbert, Roberta 또는 Xlnet Language Model에게 주변을 공급하여 증강을위한 가장 적합한 단어를 찾으십시오. | |
| 텍스트 | randomwordaug | 교체, 자르기, 삭제 | 증강을 무작위로 적용하십시오 | |
| 텍스트 | 철자 | 대리자 | 철자 실수 사전에 따른 대체 단어 | |
| 텍스트 | Splitaug | 나뉘다 | 한 단어를 무작위로 두 단어로 나눕니다 | |
| 텍스트 | 동의어 | 대리자 | WordNet/ PPDB 동의어에 따라 유사한 단어를 대체하십시오 | |
| 텍스트 | tfidfaug | 삽입, 대체 | TF-IDF를 사용하여 단어가 어떻게 증강되어야하는지 알아보십시오. | |
| 텍스트 | Wordembsaug | 삽입, 대체 | word2veec, 장갑 또는 빠른 텍스트 임베드를 활용하여 증강을 적용합니다 | |
| 텍스트 | Backtranslationaug | 대리자 | 증강을 위해 두 개의 번역 모델을 활용하십시오 | |
| 텍스트 | Reservedaug | 대리자 | 예약 된 단어를 교체하십시오 | |
| 텍스트 | 문장 | ContextualwordembsforsentEnceaug | 끼워 넣다 | XLNET, GPT2 또는 DistilGPT2 예측에 따라 문장을 삽입하십시오 |
| 텍스트 | Abstsummaug | 대리자 | 추상적 요약 방법별로 기사를 요약하십시오 | |
| 텍스트 | Lambadaaug | 대리자 | 언어 모델을 사용하여 텍스트를 생성 한 다음 분류 모델을 사용하여 고품질 결과를 유지합니다. | |
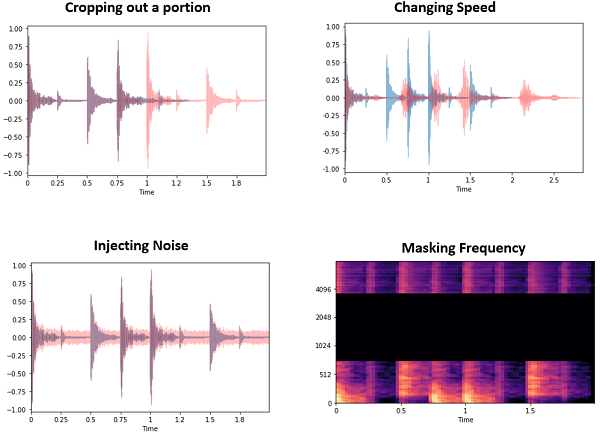
| 신호 | 오디오 | Cropaug | 삭제 | 오디오 세그먼트를 삭제합니다 |
| 신호 | 음량 | 대리자 | 오디오의 볼륨을 조정하십시오 | |
| 신호 | 마스바 그 | 대리자 | 마스크 오디오의 세그먼트 | |
| 신호 | Noiseaug | 대리자 | 소음을 주입하십시오 | |
| 신호 | Pitchaug | 대리자 | 오디오의 피치를 조정하십시오 | |
| 신호 | Shiftaug | 대리자 | 시계 시간 치수를 앞으로/ 뒤로 이동합니다 | |
| 신호 | speedaug | 대리자 | 오디오의 속도를 조정하십시오 | |
| 신호 | vtlpaug | 대리자 | 보컬 트랙을 변경하십시오 | |
| 신호 | 정상화 | 대리자 | 오디오 정상화 | |
| 신호 | PolarityInverseaug | 대리자 | 오디오를 위해 긍정적이고 부정적인 스왑 | |
| 신호 | 스펙트로 그램 | 주파수 마스킹 | 대리자 | 주파수 차원에 따라 값 블록을 0으로 설정 |
| 신호 | Timemaskingaug | 대리자 | 시간 차원에 따라 값 블록을 0으로 설정 | |
| 신호 | 음량 | 대리자 | 볼륨을 조정하십시오 |
| 증강기 | 증강기 | 설명 |
|---|---|---|
| 관로 | 잇달아 일어나는 | 확대 기능 목록을 순차적으로 적용하십시오 |
| 관로 | 때때로 | 일부 증강 기능을 무작위로 적용하십시오 |
이 라이브러리는 Linux 및 창 플랫폼에서 Python 3.5+를 지원합니다.
라이브러리를 설치하려면 :
pip install numpy requests nlpaug또는 GitHub에서 최신 버전 (베타 기능 포함)을 직접 설치하십시오.
pip install numpy git+https://github.com/makcedward/nlpaug.git또는 콘다를 설치하십시오
conda install -c makcedward nlpaugBackTranslationAug, ContextualwordemBsaug, ContextualwordembsForsentEnceaug 및 Abstsummaug를 사용하는 경우 다음 종속성도 설치합니다.
pip install torch > =1.6.0 transformers > =4.11.3 sentencepieceLambadaaug를 사용하는 경우 다음 종속성도 설치하십시오.
pip install simpletransformers > =0.61.10Antonymaug, Synonymaug를 사용하는 경우 다음 종속성도 설치합니다.
pip install nltk > =3.4.5Wordembsaug (Word2vec, Glove 또는 Fasttext)를 사용하는 경우 먼저 미리 훈련 된 모델을 다운로드하고 다음 종속성을 설치하십시오.
from nlpaug.util.file.download import DownloadUtil
DownloadUtil.download_word2vec(dest_dir= ' . ' ) # Download word2vec model
DownloadUtil.download_glove(model_name= ' glove.6B ' , dest_dir= ' . ' ) # Download GloVe model
DownloadUtil.download_fasttext(model_name= ' wiki-news-300d-1M ' , dest_dir= ' . ' ) # Download fasttext model
pip install gensim > =4.1.2Synonymaug (PPDB)를 사용하는 경우 다음 URI에서 파일을 다운로드하십시오. 다른 웹 사이트에서 PPDB 파일을 받으면 Augmenter를 실행하지 못할 수 있습니다.
http://paraphrase.org/ # /downloadpitchaug, speedaug 및 vtlpaug를 사용하는 경우 다음 종속성도 설치하십시오.
pip install librosa > =0.9.1 matplotlib자세한 내용은 ChangElog를 참조하십시오.
이 라이브러리는 데이터 (예 : 인터넷 캡처), 연구 (예 : Augmenter Idea), 모델 (예 : 미리 훈련 된 모델 사용)을 사용합니다. 자세한 내용은 데이터 소스를 참조하십시오.
@misc{ma2019nlpaug,
title={NLP Augmentation},
author={Edward Ma},
howpublished={https://github.com/makcedward/nlpaug},
year={2019}
}이 패키지는 많은 책, 워크숍 및 학술 연구 논문 (70+)에서 인용합니다. 다음은 몇 가지 예입니다. 여기를 방문하여 전체 목록을 얻을 수 있습니다.
Sakares Saengkaew | Binoy Dalal | Emrecan Çelik |


