情報爆発の時代においては、正確かつ効率的な情報スクリーニングが極めて重要です。情報過多の解決策として、レコメンデーション システムは、レコメンデーション結果とユーザーの好みの間の乖離という問題に直面することがよくあります。香港大学のチームによって開発された EasyRec は、この問題に対する革新的なソリューションを提供します。言語モデルに基づいたレコメンドシステムであり、データが不足している場合でもユーザーの好みを正確に予測し、レコメンド効率を向上させることができます。
圧倒的な情報の時代において、レコメンデーション システムは情報をフィルタリングする際の重要なアシスタントとなっています。しかし、レコメンドされたコンテンツが自分の好みに合わずにがっかりしたことはありませんか? 。
EasyRec は、香港大学のチームによって開発された、言語モデルに基づいた推奨システムです。ユニークなのは、大量のユーザーデータがなくても、テキスト情報を分析することでユーザーの嗜好を予測できることです。
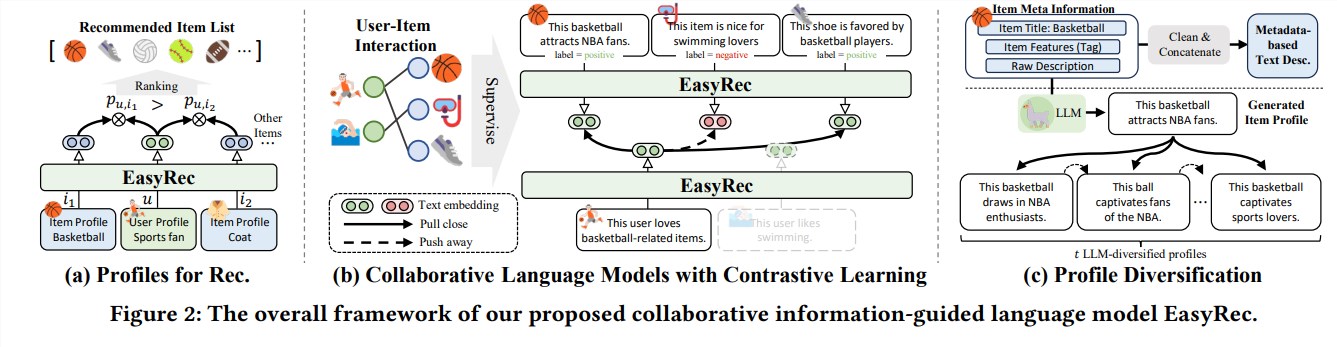
このシステムの中核テクノロジーは、テキスト動作調整フレームワークです。この技術は、閲覧した商品や読んだレビューなどのユーザー行動ストーリーを分析し、感情や詳細と組み合わせてユーザーの潜在的な嗜好を予測します。
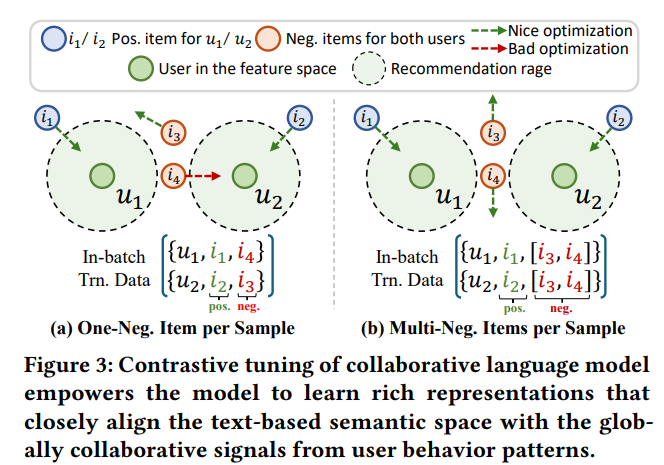
EasyRec の優れた点は、対照的な学習モデルと協調的な言語モデルを組み合わせていることです。ユーザーが好む商品の特徴を学習するだけでなく、他のユーザーのデータも学習し、比較分析を通じてユーザーを引き付ける可能性が最も高い商品を見つけます。
複数の実世界のデータセットでのテストでは、特に新規ユーザーや新規アイテムを処理するゼロショット レコメンデーション シナリオにおいて、EasyRec がレコメンデーションの精度において既存のモデルを上回っていることが示されています。
EasyRec のもう 1 つの利点は、プラグアンドプレイの性質であり、既存のレコメンデーション システムに簡単に統合できます。これにより、ビジネス ユーザーと学術研究者の両方がレコメンデーション システムのパフォーマンスを迅速に向上させることができます。
テクノロジーが進歩し続けるにつれて、EasyRec の可能性がさらに探求されています。これは商業的な推薦システムへの理解を高めるだけでなく、学術研究に新たなブレークスルーをもたらす可能性もあります。
論文アドレス: https://arxiv.org/pdf/2408.08821
EasyRec は、独自のテキスト動作調整フレームワークと対比学習メカニズムにより、ゼロサンプルのレコメンデーション シナリオで優れたパフォーマンスを示し、レコメンデーション システムが直面する課題を解決するための新しいアイデアを提供します。プラグアンドプレイ機能もあり、幅広い応用が可能であり、今後の商業分野や学術分野でのさらなる発展が期待されます。