
仮想 DOM の本質を理解して習得するにはどうすればよいでしょうか?私は皆さんに Snabbdom プロジェクトを学ぶことをお勧めします。
Snabbdom は仮想 DOM 実装ライブラリです。第一に、コードが比較的小さく、コア コードがわずか数百行であること、第二に、Vue はこのプロジェクトのアイデアを利用して仮想 DOM を実装していることです。このプロジェクトの設計/実装と拡張のアイデアは参考になります。
スナッブ /snab/ はスウェーデン語で、速いという意味です。
快適な座り姿勢を調整して元気を出してみましょう。仮想 DOM を学ぶには、まず DOM の基礎知識と、JS で DOM を直接操作する際の問題点を理解する必要があります。
DOM (Document Object Model) は、オブジェクト ツリー構造を使用して HTML/XML ドキュメントを表すドキュメント オブジェクト モデルであり、ツリーの各ブランチの終端にはオブジェクトが含まれます。 DOM API のメソッドを使用すると、このツリーを特定の方法で操作でき、ドキュメントの構造、スタイル、コンテンツを変更できます。
DOM ツリー内のすべてのノードは最初のNodeでありNode基本クラスです。 Element 、 Text 、 Commentすべてそれを継承します。
つまり、 Element 、 Text 、 Comment 3 つの特別なNodeであり、それぞれELEMENT_NODEと呼ばれます。
TEXT_NODE 、 COMMENT_NODE要素ノード(HTMLタグ)、テキストノード、コメントノードを表します。 Element HTMLElementというサブクラスもあります。 HTMLElementとElementの違いは何ですか? HTMLElement 、 <span> 、 <img>などの HTML の要素を表します。また、 <svg>などの一部の要素は HTML 標準ではありません。次のメソッドを使用して、この要素がHTMLElementであるかどうかを判断できます。
document.getElementById('myIMG') instanceof HTMLElement;ブラウザが DOM を作成するには「コストがかかります」。古典的な例を見てみましょう。 document.createElement('p')を通じて単純な p 要素を作成し、すべての属性を出力します。

複雑な DOM ツリーを頻繁に更新すると、パフォーマンス上の問題が発生することがわかります。仮想 DOM はネイティブ JS オブジェクトを使用して DOM ノードを記述するため、JS オブジェクトの作成は DOM オブジェクトを作成するよりもはるかに低コストです。
、
Snabbdom の仮想 DOM を記述するオブジェクト構造です。その内容は次のとおりです。
インターフェース VNode {
// CSS セレクター (例: 'p#container')。
sel: 文字列が定義されていません。
// モジュールを通じて CSS クラス、属性などを操作します。
データ: VNodeData 未定義;
// 仮想子ノード配列。配列要素は文字列にすることもできます。
子: 配列<VNode 文字列> | 未定義
// 作成された実際の DOM オブジェクトを指します。
elm: ノードが未定義です。
/**
* text 属性には 2 つの状況があります。
* 1. sel セレクターが設定されていないため、ノード自体がテキスト ノードであることを示します。
* 2. sel が設定され、このノードのコンテンツがテキスト ノードであることを示します。
*/
テキスト: 文字列 | 未定義;
// 既存の DOM の識別子を提供するために使用されます。不必要な再構築操作を効果的に回避するために、兄弟要素間で一意である必要があります。
キー: キー | 未定義;
}
// vnode.data、クラスまたはライフサイクル関数フックなどのいくつかの設定。
インターフェース VNodeData {
小道具?: 小道具;
属性?: 属性;
クラス?: クラス;
スタイル?: VNodeStyle;
データセット?: データセット;
オン?: オン;
AttachData?: AttachData;
フック?: フック;
キー?: キー;
ns?: 文字列; // SVG の場合
fn?: () => VNode; // サンク用
args?: any[] // サンク用
is?: string // カスタム要素 v1 の場合
[key: string]: // 他のサードパーティモジュールの場合
たとえば、vnode オブジェクトを次のように定義します。
const vnode = h(
'p#コンテナ',
{ クラス: { アクティブ: true } },
[
h('span', { style: { fontWeight: 'bold' } }, 'これは太字です'),
「これは単なる通常のテキストです」
]); h(sel, b, c)関数を通じて vnode オブジェクトを作成します。 h()コードの実装は、主に b および c パラメーターが存在するかどうかを判断し、それらをデータと子に処理し、最終的には配列の形式になります。最後に、上で定義したVNodeタイプの形式がvnode()関数を通じて返されます。
まず、実行プロセスの簡単な例を図にして、一般的なプロセスの概念を理解しましょう。

差分処理は、新しいノードと古いノードの差分を計算するために使用されるプロセスです。
Snabbdom によって実行されるサンプル コードを見てみましょう
。
初期化、
クラスモジュール、
小道具モジュール、
スタイルモジュール、
イベントリスナーモジュール、
ああ、
「スナブダム」から;
const patch = init([
// モジュールを渡してパッチ関数 classModule を初期化します。 // クラス関数 propsModule を有効にします。 // props の受け渡しをサポートします。
styleModule, // インライン スタイルとアニメーションをサポートします。eventListenersModule, // イベント リスニングを追加します]);
// <p id="コンテナ"></p>
const コンテナ = document.getElementById('コンテナ');
const vnode = h(
'p#container.two.classes',
{ 上: { クリック: someFn } }、
[
h('span', { style: { fontWeight: 'bold' } }, 'これは太字です'),
'そしてこれは単なる通常のテキストです',
h('a', { props: { href: '/foo' } }, "場所を案内します!"),
】
);
// 空の要素ノードを渡します。
パッチ(コンテナー、vnode);
const newVnode = h(
'p#container.two.classes',
{ 上: { クリック: anotherEventHandler } }、
[
h(
'スパン'、
{ スタイル: { fontWeight: 'normal', fontStyle: 'italic' } },
「これはイタリック体になりました」
)、
'そしてこれはまだ通常のテキストです',
h('a', { props: { href: ''/bar' } }, "場所を案内します!"),
】
);
// patch() を再度呼び出して、古いノードを新しいノードに更新します。
patch(vnode, newVnode);プロセス図とサンプル コードからわかるように、Snabbdom の実行プロセスは次のように記述されています。
最初に初期化のためにinit()を呼び出し、初期化中に使用するモジュールを設定する必要があります。たとえば、 classModuleモジュールはオブジェクトの形式で要素のクラス属性を構成するために使用され、 eventListenersModuleモジュールはイベント リスナーなどを構成するために使用されます。 patch()関数は、 init()が呼び出された後に返されます。
h()関数を使用して初期化された vnode オブジェクトを作成し、 patch()関数を呼び出してそれを更新し、最後にcreateElm()を使用して実際の DOM オブジェクトを作成します。
更新が必要な場合は、新しい vnode オブジェクトを作成し、 patch()関数を呼び出して更新し、 patchVnode()およびupdateChildren()を通じてこのノードと子ノードの差分更新を完了します。
Snabbdom は、コア コードにすべてを書き込むのではなく、モジュール設計を使用して関連プロパティの更新を拡張します。では、これはどのように設計され実装されているのでしょうか?次に、Kangkang の設計の中核となるコンテンツであるフック、つまりライフサイクル機能について見てみましょう。
Snabbdomは、フック関数とも呼ばれる一連のリッチライフサイクル関数を提供します。たとえば、次のように vnode でフックの実行を定義できます:
h('p.row', {
キー: 'myRow'、
フック: {
挿入: (vnode) => {
console.log(vnode.elm.offsetHeight);
}、
}、
すべてのライフサイクル関数は次のように宣言されます:
name トリガー ノード コールバック パラメーター パッチ実行開始前 なし init vnodeが
| 追加 | さ | れる | |
|---|---|---|---|
| vnode | pre | に | |
init | て | vnode | |
| 要素が作成される | create | emptyVnode, vnode | |
insert | 要素が DOM に挿入される | vnode | |
prepatch | 要素は | oldVnode にパッチを適用しようとしています | oldVnode, vnode |
update | 要素が更新されました | oldVnode, vnode | |
postpatch | 要素がパッチされました | oldVnode, vnode | |
destroy | 要素が直接または間接的に削除されました | vnode | |
remove | 要素が DOM から vnode を削除しました | vnode, removeCallback | |
post | パッチプロセスを完了しまし | た |
該当するものはあり
ませんモジュールへ: pre 、 create 、 update 、 destroy 、 remove 、 post 。 vnode 宣言に適用できるのは、 init 、 create 、 insert 、 prepatch 、 update 、 postpatch 、 destroy 、 removeです。
Kangkang がどのように実装されるかを見てみましょう。たとえば、Kangkang のclassModuleを例に挙げてみましょう
。
import { モジュール } から "./module";
エクスポート タイプ Classes = Record<string, boolean>;
関数 updateClass(oldVnode: VNode, vnode: VNode): void {
// ここではクラス属性の更新の詳細を示しますが、ここでは無視してください。
// ...
}
import const classModule: Module = { create: updateClass, update: updateClass };最後にエクスポートされたモジュール定義が、モジュール オブジェクトModuleの名前であることがわかります。次のように:
import {
プレフック、
フックの作成、
アップデートフック、
デストロイフック、
フックを削除し、
ポストフック、
"../フック" から;
エクスポート タイプ モジュール = 部分<{
pre: プリフック;
作成: CreateHook;
更新: UpdateHook;
破壊: DestroyHook;
削除: フックを削除します。
ポスト: ポストフック;
}>; TS のPartialは、オブジェクト内の各キーの属性を空にすることができることを意味します。つまり、モジュール定義で必要なフックを定義するだけです。フックが定義されたので、プロセス内でどのように実行されるのでしょうか?次に、 init()関数を見てみましょう。
// モジュール内で定義できるフックは何ですか。
const フック: Array<keyof Module> = [
"作成する"、
"アップデート"、
"取り除く"、
"破壊する"、
「前」、
"役職"、
];
エクスポート関数 init(
モジュール: 配列<部分<モジュール>>、
domApi?: DOMAPI、
オプション?: オプション
) {
//モジュール内で定義したフック関数は最終的にここに格納されます。
const cbs: モジュールフック = {
作成する: []、
アップデート: []、
取り除く: []、
破壊する: []、
前: []、
役職: []、
};
// ...
// モジュール内で定義されたフックをトラバースし、それらをまとめて保存します。
for (const フックのフック) {
for (モジュールの定数モジュール) {
const currentHook = モジュール[フック];
if (currentHook !== 未定義) {
(cbs[hook] as any[]).push(currentHook);
}
}
}
// ...
init()実行中にまず各モジュールを走査し、次にフック関数をcbsオブジェクトに格納することがわかります
。
実行すると、 patch()関数:
エクスポート機能initを使用できます。
モジュール: 配列<部分<モジュール>>、
Domapi?:Domapi、
オプション?:オプション
) {
// ...
戻り機能パッチ(
oldVnode: VNode 要素 |
vnode:vnode
):vnode {
// ...
// パッチが開始され、プリフックが実行されます。
for (i = 0; i < cbs.pre.length; ++i) cbs.pre[i]();
// ...
}
ここでは、
preを例として取り上げます。 preの実行時間は、パッチの実行が開始される時間です。 patch()関数が、実行開始時にcbsに格納されているpre関連フックを周期的に呼び出していることがわかります。他のライフサイクル関数の呼び出しもこれに似ています。対応するライフサイクル関数の呼び出しはソース コードの他の場所で確認できます。
ここでの設計上のアイデアは、オブザーバー パターンです。 Snabbdom は、非コア関数をモジュールに分散することによって実装します。ライフサイクルの定義と組み合わせることで、モジュールは対象となるフックを定義できます。その後、 init()が実行されると、これらのフックを登録するためにcbsオブジェクトに処理されます。実行時間になったら、これらのフックを呼び出してモジュールの処理を通知します。これにより、コア コードとモジュール コードが分離されます。ここから、オブザーバー パターンがコード分離の一般的なパターンであることがわかります。
次に、Kangkang のコア関数patch()について説明します。この関数は、 init()呼び出しの後に返されます。その機能は、VNode をマウントして更新することです。
function patch(oldVnode: VNode | Element) | DocumentFragment 、vnode: VNode): VNode {
// 簡単にするために、DocumentFragment には注意を払わないでください。
// ...
oldVnode パラメーターは古い VNode、DOM 要素、またはドキュメントのフラグメントであり
oldVnode vnodeパラメーターは更新されたオブジェクトです。
モジュールに登録されているpreを呼び出す
プロセスの説明を直接投稿します
。oldVnodeがElementの場合、空のvnodeオブジェクトに変換され、属性にelm記録されます。
ここでの判断は、 Element (oldVnode as any).nodeType === 1 nodeType === 1ここで定義されている ELEMENT_NODE であることを示します。
、
oldVnodeとvnodeが同じであるかsameVnode()かを判断します。
//同じキー。 const isSameKey = vnode1.key === vnode2.key; // Webコンポーネント、カスタム要素タグ名、こちらを参照してください: // https://developer.mozilla.org/zh-CN/docs/Web/API/Document/createElement const issameis = vnode1.data?.is === vnode2.data?.is; //同じセレクター。 const isSameSel = vnode1.sel === vnode2.sel; // 3 つとも同じです。 isSameSel && isSameKey && isSameIs; を返します。 }
patchVnode()を呼び出します。createElm()を呼び出して新しい DOM ノードを作成し、作成後に DOM ノードを挿入し、古い DOM ノードを削除します。上記の操作に関連するvnodeオブジェクトに登録されているinsertフックキューを呼び出すことにより、新しいノードを挿入できますpatchVnode() createElm() 。これが行われる理由については、 createElm()で言及されます。
最後に、モジュールに登録されているpostフックが呼び出されます。
このプロセスは、vNodesが同じである場合、基本的にdiffを行うことであり、それらが異なる場合は、新しいものを作成して古いものを削除します。次に、 createElm()どのようにDOMノードを作成するかを見てみましょう。
createElm() vnodeの構成に基づいてdomノードを作成します。プロセスは次のとおりです。VNode
オブジェクトに存在する可能性のあるinitフックを呼び出します。
次に、いくつかの状況に対処します。
vnode.sel === '!'の場合、これは Snabbdom が元のノードを削除するために使用するメソッドであり、新しいコメント ノードが挿入されます。古いノードはcreateElm()後に削除されるため、この設定はアンインストールの目的を達成できます。
vnode.selセレクターの定義が存在する場合:
セレクターを解析し、 id 、 tag 、 classを取得します。
document.createElement()またはdocument.createElementNSを呼び出して DOM ノードを作成し、それをvnode.elmに記録し、前のステップの結果に基づいてid 、 tag 、およびclassを設定します。
モジュールのcreateフックを呼び出します。
children配列を処理します。
childrenが配列の場合、 createElm()再帰的に呼び出して子ノードを作成し、 appendChild呼び出してvnode.elmの下にマウントします。
children配列ではなく、 vnode.textが存在する場合、この要素の内容がvnode.elmであることを意味しcreateTextNode 。
vnode でcreateフックを呼び出します。そして、vnode のinsertフックをinsertフック キューに追加します。
残りの状況は、 vnode.sel存在しないことです。これは、ノード自体がテキストであることを示しており、 createTextNode呼び出してテキスト ノードを作成し、それをvnode.elmに記録します。
最後にvnode.elmを返します。
createElm() selセレクターのさまざまな設定に基づいてDOMノードを作成する方法を選択するプロセス全体から見ることができます。ここに追加すべき詳細があります。 patch()で説明されているinsertフック キューです。このinsertフックキューが必要である理由は、DOMが実際に挿入されるまで実行する前に待機する必要があることです。また、すべての子孫ノードが挿入されるまで待つ必要があるため、要素を正確にinsertしてください。上記の子ノードを作成するプロセスと組み合わせることで、 createElm()子ノードを作成するための再帰的な呼び出しであるため、キューは最初に子ノード、次にそれ自体を記録します。このようにして、 patch()の最後にキューを実行するときに注文を保証できます。
次に、SnabbdomがpatchVnode()使用してVirtual DomのコアであるDIFFを実行する方法を見てみましょう。 patchVnode()の処理フローは次のとおりです。
最初にVNodeのprepatchフックを実行します。
OldVNodeとVNodeが同じオブジェクト参照である場合、処理せずに直接返されます。
モジュールと vnode でupdateフックを呼び出します。
vnode.textが定義されていない場合、 childrenのいくつかのケースが処理されます:
oldVnode.childrenとvnode.children両方が存在し、同じではない場合。次に、 updateChildrenに電話して更新します。
vnode.children存在しますが、 oldVnode.children存在しません。 oldVnode.textが存在する場合は、最初にクリアしてから、 addVnodesを呼び出して新しいvnode.childrenを追加します。
vnode.children存在しませんが、 oldVnode.children存在します。 removeVnodes呼び出して、 oldVnode.childrenを削除します。
oldVnode.childrenもvnode.childrenも存在しない場合。 oldVnode.textが存在する場合はクリアします。
vnode.textが定義され、 oldVnode.textとは異なる場合。 oldVnode.childrenが存在する場合は、 removeVnodes呼び出してそれをクリアします。次に、 textContentを通じてテキストコンテンツを設定します。
最後に、vnode でpostpatchフックを実行します。
class 、 styleなど、DIFFの関連属性の変更がモジュールによって更新されていることがわかりますモジュール関連のコードを見ることができます。 DIFFの主なコア処理はchildren次にchildrenに焦点を当てています。
非常にシンプルです。最初のcreateElm()を作成し、対応する親に挿入します。
remove destory
destory 、このフックは最初に呼ばれます。ロジックは、最初にvNodeオブジェクトのフックを呼び出してから、モジュールのフックを呼び出すことです。このフックは、この順序でvnode.childrenで再帰的に呼ばれます。removeれた要素の子要素がトリガーされない場合にのみトリガーされ、このフックはモジュールとVNodeオブジェクトの両方で呼び出されます最初にモジュール。さらに特別なのは、すべてのremoveが呼び出されるまで、要素が実際に削除されないことです。上記から、 removeの2つのフックの呼び出しロジックが異なることがわかります。
updateChildren()は、子ノードdiffを処理するために使用されます。また、Snabbomでも比較的複雑な機能です。一般的newStartIdxアイデアoldEndIdx 、 oldChとnewCh newEndIdx合計4つのoldStartIdxとテールポインターを設定することです。次に、2つの配列をwhile (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx)ループを比較して、再利用と更新のために同じパーツを見つけ、比較ごとに1つのポインターに移動します。詳細なトラバーサルプロセスは、次の順序で処理されます。4
つのポインターのいずれかがVNode == nullを指している場合、ポインターは次のように中央に移動します。
古いスタートノードと新しいスタートノードが同じである場合、つまりsameVnode(oldStartVnode, newStartVnode)がtrueを返します。PatchVnode patchVnode()使用してDIFFを実行し、両方の開始ノードは1つのステップを中央に向かって移動します。
古いエンドノードと新しいエンドノードが同じ場合、 patchVnode()も使用され、2つのエンドノードが1つのステップに戻ります。
古い開始ノードが新しいエンドノードと同じ場合、 patchVnode()使用して最初に更新を処理します。次に、 oldEndVnodeに対応するDOMノードを移動する必要があります。なぜこのように動くのでしょうか?まず、OldStartはNewEndと同じです。つまり、現在のループ処理では、古い配列の開始ノードが右に移動しているため、ヘッドとテールのポインターが中央に移動します。この時点では、古い配列はまだ処理されていないかもしれませんが、この時点では、新しい配列の現在の処理の最後のものであると判断されているため、次の兄弟に移動することは合理的です。 oldEnd のノード。移動が完了した後、OldStart ++とNewEnd-それぞれのアレイの中央に1つのステップを移動します。
古いエンドノードが新しいスタートノードと同じ場合、 patchVnode()が最初に更新を処理し、次にOldEndに対応するDOMノードがoldStartVnodeに対応するDOMノードに移動します前のステップと同じ。移動が完了した後、Oldend-、Newstart ++。
上記のいずれにも当てはまらない場合は、 newStartVnode のキーを使用して、 oldChildrenの添字 idx を見つけます。 添字が存在するかどうかに応じて、2 つの異なる処理ロジックがあります。
添字が存在しない場合は、 newStartVnode が新しく作成されることを意味します。 createElm()を介して新しいdomを作成し、 oldStartVnodeに対応するDOMの前に挿入します。
添え字が存在する場合、2つのケースで処理されます。2
つのvNodesのSELが異なる場合でも、新しく作成されたものと見なされ、 createElm()を介して新しいdomを作成し、 oldStartVnodeに対応するDOMの前に挿入します。
SELが同じ場合、更新はpatchVnode()を介して処理され、 oldChildrenの添え字に対応するVNodeが未定義に設定されています。次に、更新されたノードをoldStartVnodeに対応する DOM に挿入します。
以上の操作が完了したら、newStart++を実行します。
トラバーサルが完了した後、対処すべき2つの状況がまだあります。 1つは、 oldChが完全に処理されていることですが、 newChにoldCh newCh新しいノードがあり、残りのnewChごとに新しいDOMを作成する必要があります。冗長ノードを削除する必要があります。 2つの状況は次のように処理されます
。
Parentelm:ノード、
oldch:vnode []、
Newch:vnode []、
挿入vnodequeue:vnodequeue
) {
// ダブルポインタのトラバーサル処理。
// ...
// Newchには、作成する必要がある新しいノードがあります。
if(newstartidx <= newEndidx){
//最後の処理されたnewEndidxの前に挿入する必要があります。
before = newch [newEndidx + 1] == null:newch [newEndidx + 1] .elm;
addvnodes(
親エルム、
前に、
新しいCh、
newStartIdx、
newEndIdx、
挿入されたvnodequeue
);
}
// Oldchにはまだ削除する必要がある古いノードがあります。
if(oldStartIdx <= oldEndidx){
removevnodes(parentelm、oldch、oldstartidx、oldendidx);
}
}実用的な例を使用してupdateChildren()の処理プロセスを調べましょう。
初期状態は次のとおりです。古い子ノードアレイは[a、b、c]、新しいノードアレイは[b、a、cです、d]:

比較の最初のラウンドでは、開始ノードとエンドノードが異なるため、 patchVnode()が古いノードに存在するかどうかを確認し、OldChの位置を見つけて最初に更新し、Oldch [1を更新します。 ] =未定義で、 oldStartVnode前にDOMを挿入すると、 newStartIdx 1つのステップを動かし、処理後のステータスは次のとおりです。
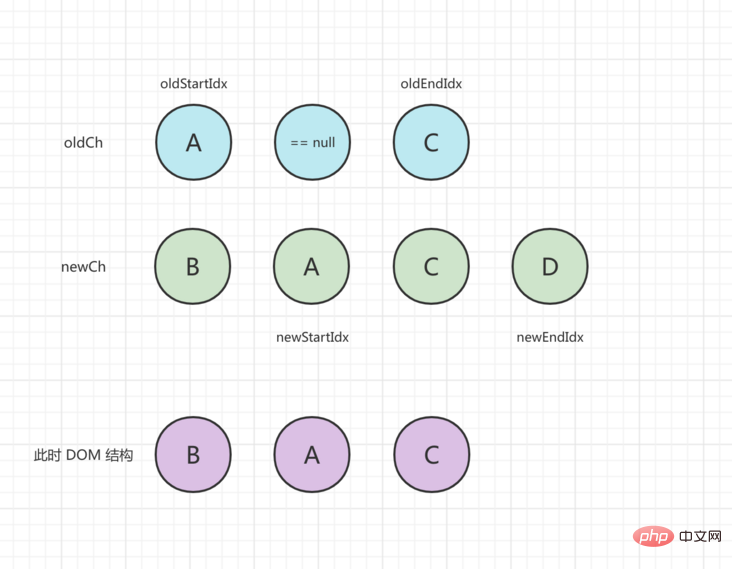
2 回目の比較では、 oldStartVnodeとnewStartVnodeが同じになります。patchVnode patchVnode()実行して更新すると、 oldStartIdxとnewStartIdx中間に移動します。
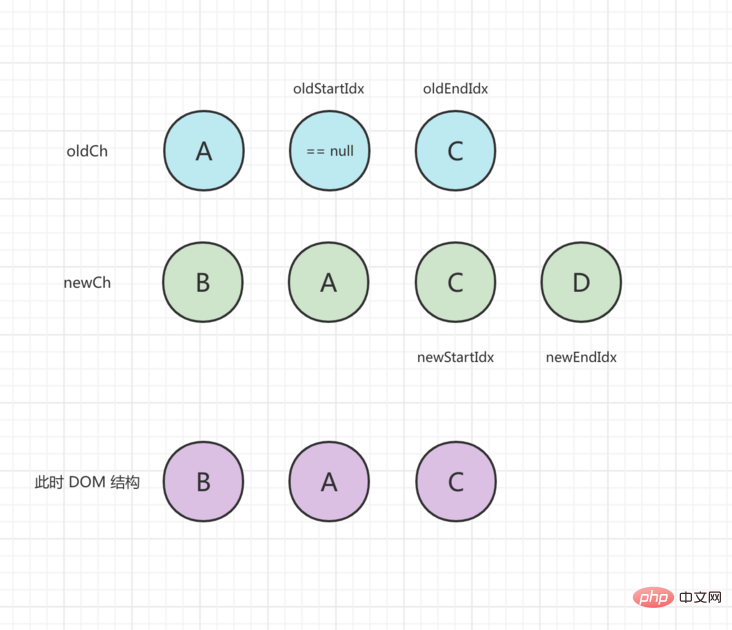
比較の第3ラウンドでは、 oldStartVnode == null 、 oldStartIdx中央に移動し、ステータスは次のように更新されます。
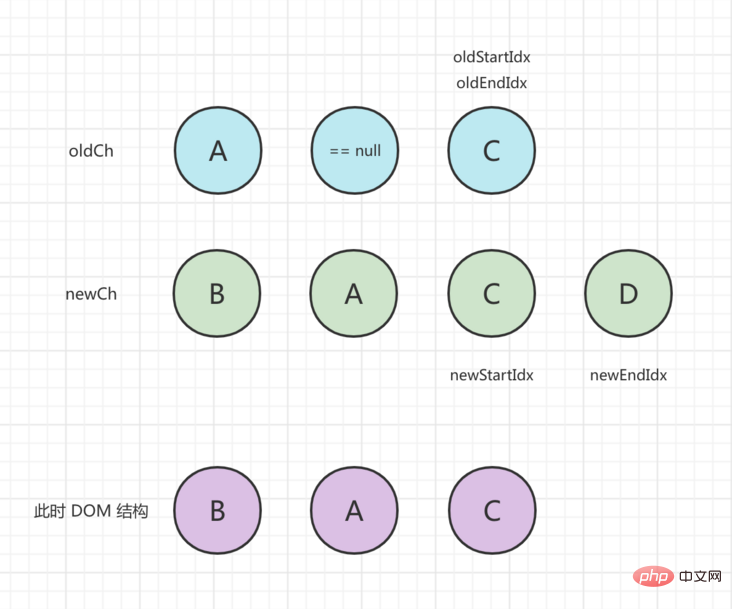
4 回目の比較では、 oldStartVnodeとnewStartVnodeが同じになります。patchVnode patchVnode()実行して更新すると、 oldStartIdxとnewStartIdx中間に移動します。

この時点で、 oldStartIdxはoldEndIdxより大きくなり、ループは終了します。現時点では、 newChで処理されていない新しいノードがあり、 addVnodes()呼び出して最終的なステータスを挿入する必要があります。

、仮想DOMのコアコンテンツはここで整理されていますアイデアは学ぶ価値があります。