UA LLM
1.0.0
このリポジトリには、幅広いウクライナのNLPタスクのさまざまな大規模な言語モデル(LLM)の適応、訓練、評価、および活用に役立つ完全なパイプライン、スクリプトと個々のコンポーネントが含まれています。
このリポジトリでコードを使用するには、システムにCondaをインストールする必要があります。次に、次のコマンドを実行することにより、必要な依存関係を備えた新しいコンドラ環境を作成できます。
conda env create -f environment.yml
これにより、必要なすべての依存関係がインストールされたua-llmと呼ばれる新しいコンドラ環境が作成されます。次に、次のコマンドを実行して、この環境をアクティブにすることができます。
conda activate ua-llm
pre-commit install # required only for contributors
LLMプロバイダーからアクセス資格情報を取得します。
ソースコードディレクトリに移動します:
cd src
取得した資格情報でモデル構成を入力します。 OpenAIプロバイダーについては、以下の例のコマンドを参照してください。
python tools/set_auth.py --openai_org_id <your_org> --openai_api_key <your_api_key>
または、他のサポートされているLLMプロバイダーに対して、次のコマンドと同様のコマンドを使用します(引数リストを表示するために--helpで実行)。
python tools/set_auth.py --cohere_api_key <your_api_key>
例のタスクを実行して予測を取得して評価します(リクエストごとにLLMプロバイダーによって請求されることに注意してください。そのため、トライアルサブスクリプションまたはAPIキーで次のコマンドを実行することをお勧めします):
python main.py +task=qa_eval_task
その結果、次の出力が得られます。
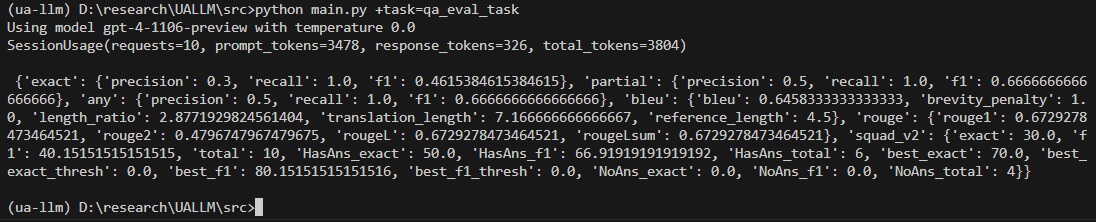
configs/ Directoryの評価タスク構成やその他のファイルを自由に検討して、タスクとその仕組みの詳細を取得してください。また、Hydra FrameworkとOmegaconfについて詳しく知ることもできます。
これで、評価のために独自のデータセットを使用するか、特定のニーズに合ったタスクを適応させる準備ができました。
python main.py +task=qa_predict_task
python main.py +task=qa_annotate_task
このリポジトリに貢献したい場合は、新しいブランチを作成して、変更を受けてプルリクエストを送信してください。貢献は大歓迎です!
このリポジトリは、Apache 2.0ライセンスの下でライセンスされています。詳細については、ライセンスファイルを参照してください。


