GUNDAM
1.0.0

プロジェクト|論文|ドキュメント
Gundamは、言語モデルを利用してPytorchに基づいて構築されたテキストデータを効率的に処理するデータマネージャーです。ガンダムは次のとおりです。
Gundamは、言語モデルを条件付けられたプラグインデモンストレーションの十分性と必要性を測定する新しいデータ管理フレームワークです。提案された充足度と必要性メトリックは、デモンストレーションインスタンス(つまり、インスタンスレベル)とデモンストレーションセット(つまり、セットレベル)の両方で操作できることを示します。したがって、ゴールデンプラグインセットと呼ばれる十分で必要なプラグインデータのセットは、有益なサンプルを含むコアセットと見なすことができます。可能なすべてのサブセットを列挙して測定することは実行不可能であるため、Goldenプラグインセットをマイニングするために新しいツリーベースの検索アルゴリズムを設計します。ゴールデンプラグインセットを事前に計算して保存して、オンラインの計算コストを節約できることに注意してください。この点で、ノンパラメトリックデモンストレーションレトリバーは、データコーパス全体の代わりに保存されたゴールデンプラグインセットで実行でき、不十分または不必要なデモンストレーションを取得しないようにします。さらに、多くの現実世界のデータコーパスが成長し続けることを考慮すると、変更されたすべての部品と変化していないパーツのガンダムを再計算しないように、インクリメンタル更新アルゴリズムを開発します。
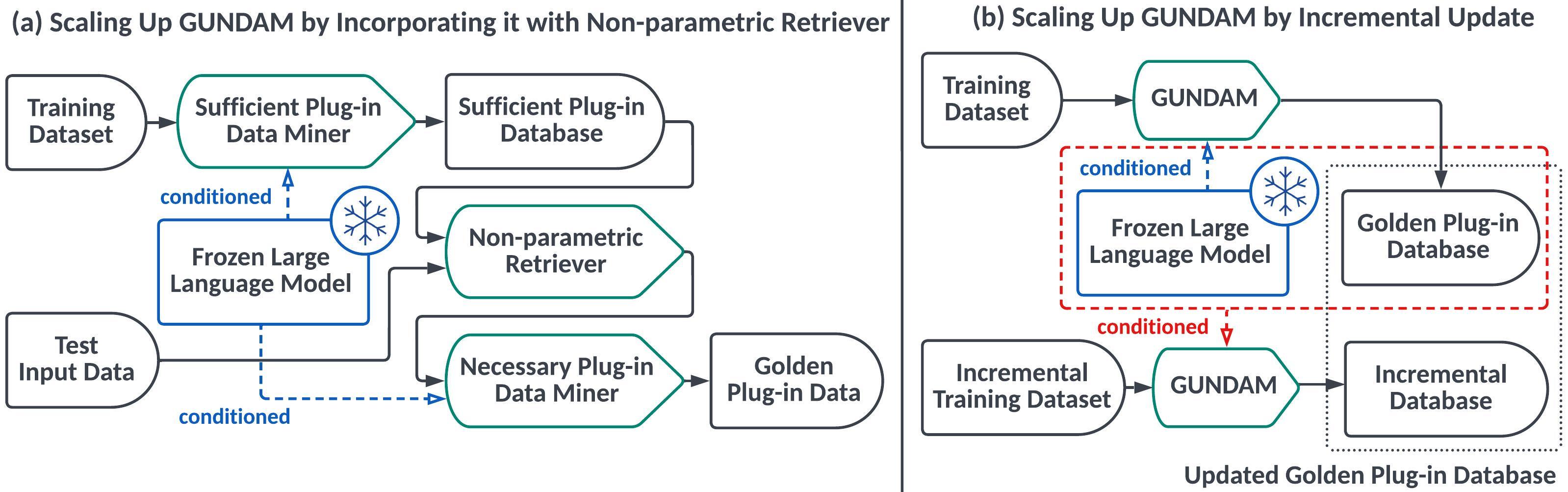
ガンダムの重要な利点は、ガンダムのコアアイデアは、特定の言語モデルに関するデータの品質を示すために、Gundamの中心的なアイデアは保存されたデータに異なる優先レベルを割り当てることであるため、Gundamを既存のデータ管理プラットフォームに簡単に展開できることです。
@software { GUNDAM ,
author = { Jiarui Jin, Yuwei Wu, Mengyue Yang, Xiaoting He, Weinan Zhang, Yiming Yang, Yong Yu, and Jun Wang } ,
title = { GUNDAM: A Data-Centric Manager for Your Plug-in Data with Language Models } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
version = { 0.0 } ,
howpublished = { url{https://github.com/GUNDAM-Labet/GUNDAM} } ,
}ガンダムシステムのコア開発者は、江ui、Yuwei Wu、Mengyue Yangです。
ガンダムは、バージョン2.0のApacheライセンスに基づいてリリースされます。


