Anime2Sketch
1.0.0
Anime2Sketch:イラストのためのスケッチ抽出器、アニメアート、漫画
Xiaoyu Xiangによる

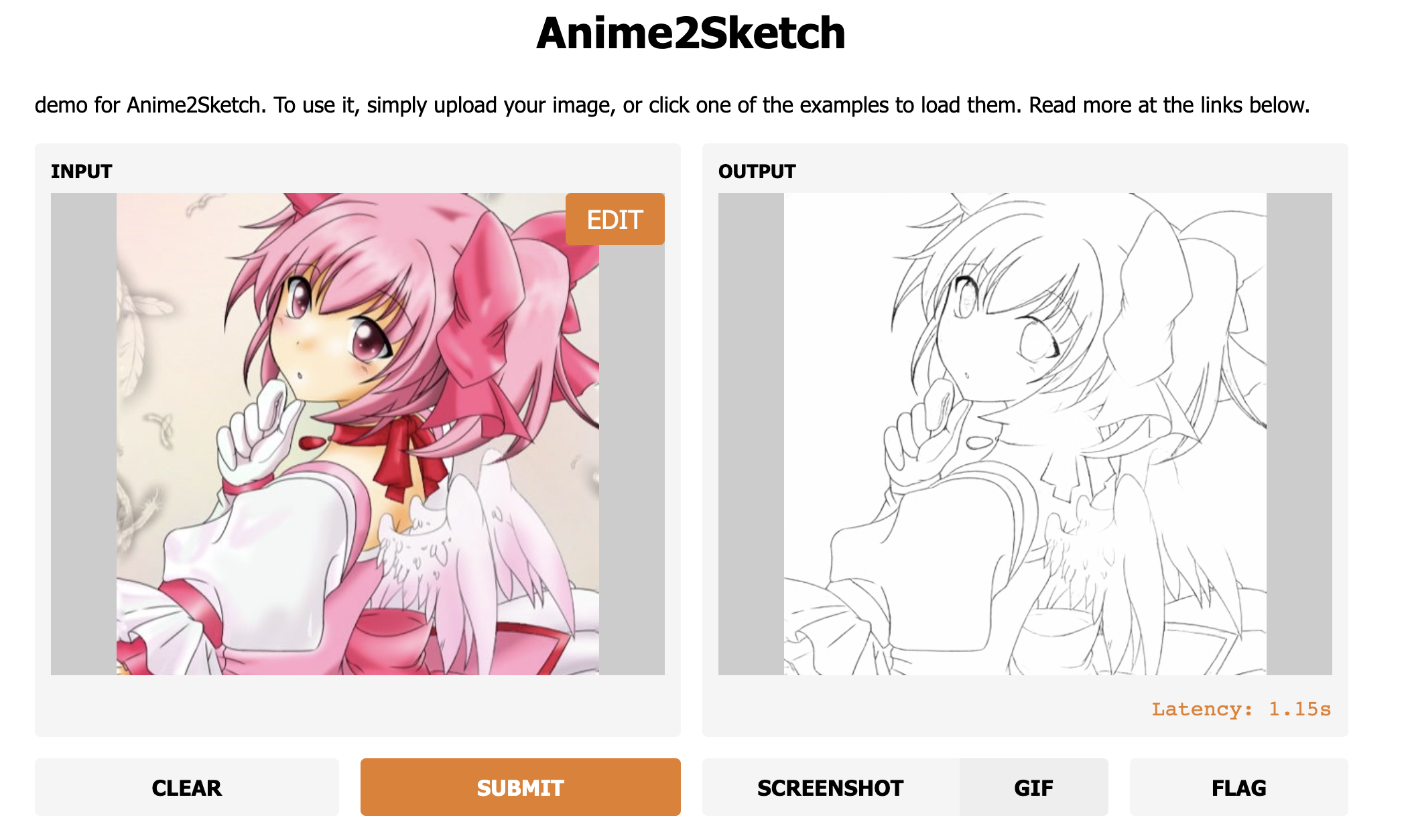
リポジトリには、ANIME2SKETCHのテストコードと事前処理された重みが含まれています。
Anime2Sketchは、イラスト、アニメアート、漫画でうまく機能するスケッチ抽出器です。これは、「スケッチ間統合のための敵対的なオープンドメイン適応」という論文に基づいたアプリケーションです。
必要なパッケージのインストール: pip install -r requirements.txt
GoogledRiveからWeightsをダウンロードして、Weights/ Folderに入れてください。
また、ダーク /ローコントラスト画像で動作するモデルのアーティファクトフリーのバージョンもあります。 GoogleDriveからWeightsをダウンロードして、Weights/ Folderに入れることができます。
python3 test.py --dataroot /your_input/dir --load_size 512 --output_dir /your_output/dir上記のコマンドには3つの引数が含まれています。
512x512にサイズを変更します。例を実行します:
python3 test.py --dataroot test_samples/madoka.jpg --load_size 512 --output_dir results/ Dockerで実行したい場合は、入力/出力画像ディレクトリをカスタマイズすることで簡単に実行できます。
Docker画像を作成します
make docker-build入力/出力ディレクトリの設定
MakeFileで入力/出力画像のマウントボリュームをカスタマイズできます。ターゲットディレクトリを設定してください。
docker run -it --rm --gpus all -v `pwd`:/workspace -v {your_input_dir}:/input -v {your_output_dir}:/output anime2sketch
例:
docker run -it --rm --gpus all -v `pwd`:/workspace -v `pwd`/test_samples:/input -v `pwd`/output:/output anime2sketch
走る
make docker-runCPUのみを実行する場合は、2つのものを修正する必要があります(GPUオプションを削除します)。
CMD [ "python", "test.py", "--dataroot", "/input", "--load_size", "512", "--output_dir", "/output" ]docker run -it --rm -v `pwd`:/workspace -v `pwd`/images/input:/input -v `pwd`/images/output:/output anime2sketchこのプロジェクトは、AODAのサブブランチです。トレーニングの指示については確認してください。
私たちのモデルはイラストアートに適しています:
 手持ち式の写真をめくるために、Lineartsをきれいにする:
手持ち式の写真をめくるために、Lineartsをきれいにする: フリーハンドのスケッチを簡素化:
フリーハンドのスケッチを簡素化: そして、より多くのアニメの結果:
そして、より多くのアニメの結果: 

Xiaoyu Xiang。
また、リポジトリの問題として質問を残すこともできます。答えてうれしいです!
このプロジェクトは、MITライセンスの下でリリースされます。
@misc { Anime2Sketch ,
author = { Xiaoyu Xiang, Ding Liu, Xiao Yang, Yiheng Zhu, Xiaohui Shen } ,
title = { Anime2Sketch: A Sketch Extractor for Anime Arts with Deep Networks } ,
year = { 2021 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/Mukosame/Anime2Sketch} }
}
@inproceedings { xiang2022adversarial ,
title = { Adversarial Open Domain Adaptation for Sketch-to-Photo Synthesis } ,
author = { Xiang, Xiaoyu and Liu, Ding and Yang, Xiao and Zhu, Yiheng and Shen, Xiaohui and Allebach, Jan P } ,
booktitle = { Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision } ,
year = { 2022 }
}

