text cnn tensorflow
1.0.0
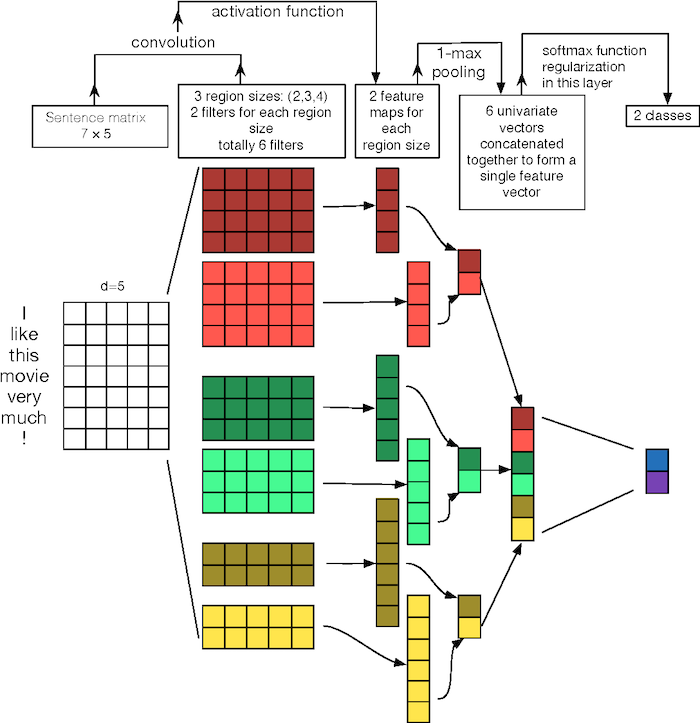
このコードは、文化分類モデルのための畳み込みニューラルネットワークを実装します。
HBベースによるINITプロジェクト
.
├── config # Config files (.yml, .json) using with hb-config
├── data # dataset path
├── notebooks # Prototyping with numpy or tf.interactivesession
├── scripts # download or prepare dataset using shell scripts
├── text-cnn # text-cnn architecture graphs (from input to logits)
├── __init__.py # Graph logic
├── data_loader.py # raw_date -> precossed_data -> generate_batch (using Dataset)
├── hook.py # training or test hook feature (eg. print_variables)
├── main.py # define experiment_fn
├── model.py # define EstimatorSpec
└── predict.py # test trained model
参照:HB-Config、DataSet、Experiments_Fn、TisitatorSpec
例:kaggle_movie_review.yml
data :
type : ' kaggle_movie_review '
base_path : ' data/ '
raw_data_path : ' kaggle_movie_reviews/ '
processed_path : ' kaggle_processed_data '
testset_size : 25000
num_classes : 5
PAD_ID : 0
model :
batch_size : 64
embed_type : ' rand ' # (rand, static, non-static, multichannel)
pretrained_embed : " "
embed_dim : 300
num_filters : 256
filter_sizes :
- 2
- 3
- 4
- 5
dropout : 0.5
train :
learning_rate : 0.00005
train_steps : 100000
model_dir : ' logs/kaggle_movie_review '
save_checkpoints_steps : 1000
loss_hook_n_iter : 1000
check_hook_n_iter : 1000
min_eval_frequency : 1000
slack :
webhook_url : " " # after training notify you using slack-webhook 要件をインストールします。
pip install -r requirements.txt
次に、データセットを準備してトレーニングします。
sh prepare_kaggle_movie_reviews.sh
python main.py --config kaggle_movie_review --mode train_and_evaluate
トレーニング後、 predict.pyを使用して必要なものを文章に入力することを試みることができます。
python python predict.py --config rt-polarity
例を予測します
python predict.py --config rt-polarity
Setting max_seq_length to Config : 62
load vocab ...
Typing anything :)
> good
1
> bad
0
✅:働いています
◽:まだテストされていません。
evaluate :評価データで評価します。extend_train_hooks :トレーニング用のフックを拡張します。reset_export_strategies :new_export_strategiesでエクスポート戦略をリセットします。run_std_server :Tensorflowサーバーを起動し、サービングスレッドに結合します。test :シングルステップの推定器のトレーニング、評価、エクスポートのテスト。train :トレーニングデータを使用して推定器を適合させます。train_and_evaluate :トレーニングと評価をリーブします。tensorboard --logdir logs