Chinese_models_for_SpaCy
1.0.0
スペイシーに提供される中国のデータモデル。モデルは現在、ベータ版のパブリックテスト中です。
Jupyterノートブックに基づくオンラインデモ。
このDocオブジェクトの属性情報のいくつかは王小明在北京的清华大学读书:
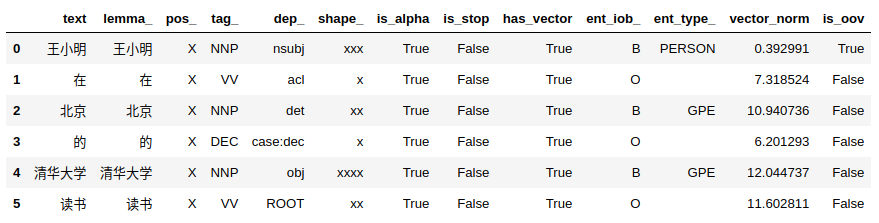
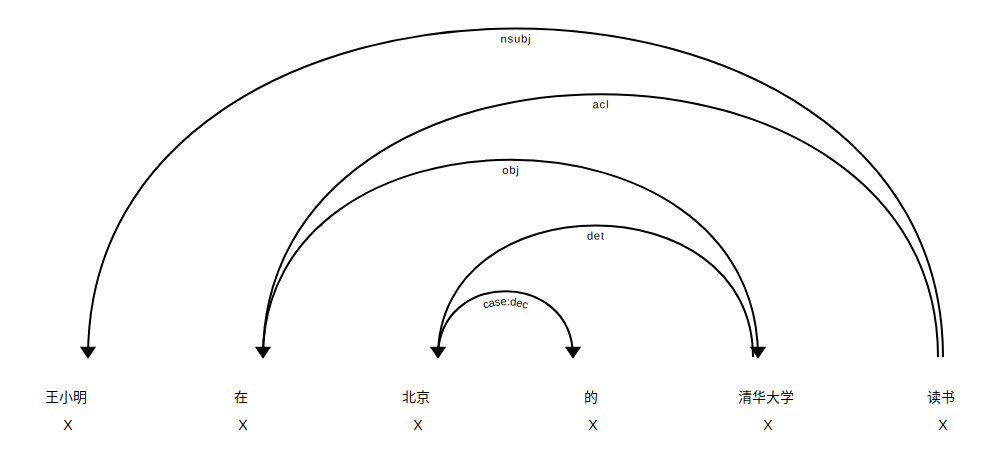
王小明在北京的清华大学读书Wang XiaomingのDoc研究に関するNER情報のいくつか:

モデルはバイナリファイルの形式で配布されており、ユーザーはスペイシーに関する基本的な知識を持っている必要があります(バージョン> 2)。
Python 3(Python2をサポートするかもしれませんが、十分にテストされていません)
リリースページからモデルをダウンロードします(新規!中国のユーザーに、ダウンロードを加速するためのリンクを提供します)。ダウンロードされたモデルの名前がzh_core_web_sm-2.xxtar.gzと呼ばれるとします。
pip install zh_core_web_sm-2.x.x.tar.gz
Rasa NLUなどのフレームワークでの後続の使用を促進するには、次のコマンドを実行して、このモデルのリンクを確立する必要があります。
spacy link zh_core_web_sm zh実行が完了した後、エイリアスZHを使用してモデルにアクセスできます。
デモコードはtest.pyにあります。モデルがインストールされた後、ユーザーはこのリポジトリのコードをダウンロードまたはクローン化し、直接実行できます。
python3 ./test.pyアドレスを開きますhttp://127.0.0.1:5000では、次のことがわかります。
ワークフローを参照してください
このプロジェクトで使用されているコーパスは、Ontonotes 5.0です。
Ontonotes 5.0はLDC(言語データコンソーシアム)の著作権で保護された資料であるため、このプロジェクトに直接含めることはできません。良いニュースは、Ontonotes 5.0は、企業や学術組織を含むグループユーザーにとって完全に無料であることです。ユーザーは、企業または学術組織のアカウントを確立し、Ontonotes 5.0を無料で取得できます。
pos_は正しくありません。これは、スペイシーの中国語クラスに関連しています。shape_およびis_alpha中国人にとって意味がないようですが、それを確認するには権威ある情報が必要です。is_stopが正しくありません。これは、スペイシーの中国語クラスに関連しています。vector十分に訓練されていないようです。is_oovは完全に間違っています。最初の優先度修正。Contributing.mdを読んで、プルリクエストを提出してください。
バージョン標準にはsemverを使用しています。すべてのバージョンを理解するには、 tagsをチェックしてください。
貢献者の詳細については、 contributorsを参照してください。
MITライセンス - 詳細については、license.mdを参照してください


