llm_osint
1.0.0
LLM OSINTは、LLMを使用してインターネットから情報を収集し、この情報を使用してタスクを実行する概念実証方法です。
Wall Street Journal「Generative AIは、ハッカー向けに電子メールに革命を起こす可能性がある」に見られるように。
/例の完全なコードを参照してください。
このツールは、公開されている情報源から情報を収集するのが不気味です。ただし、このような強力なツールを使用することに伴う責任を認識することが重要です。自分以外の個人を研究するためにそれを利用する場合、常に各人のプライバシーに対する権利を認識してください。オープンソースインテリジェンスを通じて明らかにされた個人情報は個人的なものであり、敬意と保護を扱うべきであることを忘れないでください。このツールを倫理的かつ責任を持って使用して、誰かのプライバシーを侵害したり、悪意のある活動に従事したりしないようにします。
このようなものの最も明白な用途は、誰かを「Google」にして、この情報でアクションを実行することです。これらの例では、私はそれを使用して自分自身を研究し、最初の結果を得ました。以下のコマンドを超えてスクリプトに他の追加情報は提供されていません。一般的な名前の場合、乱用はJohn Smith (the Texas Musician)のように行うことができます。
$ python examplesperson_lookup.py "Shrivu Shankar" --ask $QUESTION
INTJ(自信:高) - Shrivu Shankarのコーディング、研究、および問題解決に対する情熱は、個人的な発達とリーダーシップの役割に焦点を当て、INTJパーソナリティタイプを指し示しています。 INTJは、科学技術分野で優れた戦略的で革新的で目標指向の個人であることで知られています。
INTP(信頼性:中) - 複雑な問題を解決するためのシュリブの傾向と研究開発プロジェクトへの関与は、INTPパーソナリティタイプのいくつかの特性を示しています。 INTPは、問題解決に対する分析的および論理的なアプローチと、新しい概念を学び、探索することへの情熱で知られています。
ENTJ(自信:低) - シュリブは強力なリーダーシップスキルとチーム指向の活動への関与を示していますが、彼らの全体的なプロファイルは外向よりも内向性に傾いているようです。しかし、競技会やハッカソンでの成果、およびさまざまなクラブや社会への参加は、戦略的思考、組織、達成への意欲などのいくつかのENTJ特性を示唆しています。
これは正確です(INTJ)。
Shrivu Shankarは、テキサス州オースティンに拠点を置く異常なセキュリティの機械学習エンジニアです。彼は、テキサス大学オースティン校でコンピューターサイエンスの科学学士号を取得しています。シュリブには、彼の心理的プロファイルに貢献する多様な関心と成果があります。
強み:
弱点:
全体として、シュリブ・シャンカールは、情熱、好奇心、自発性、目標志向、チームワークなど、個人的な資質の強力な基盤を示しています。しかし、彼はワークライフのバランス、趣味と興味の多様化、過剰コミットメントの管理、効果的な公共コミュニケーションの課題に直面する可能性があります。彼の個人的および職業上の成長を最適化するために、シュリブはこれらの改善分野に焦点を合わせ、バランスのとれた充実した人生を確立するために彼の強みを活用することから利益を得るかもしれません。
これはかなりワイルドです。
機械学習エンジニア| LinkedIn :Shrivushankar | github :sshh12 | Twitter :Shrivushankar | Instagram :shrivu1122 |個人のウェブサイト:sshh.io
これは、さまざまな期間から多くの情報をマージしますが、それでもかなり興味深いものです。
| 属性 | 情報 |
|---|---|
| 名前 | Shrivu Shankar |
| 仕事 | 異常なセキュリティの機械学習エンジニア |
| 位置 | 米国テキサス州オースティン |
| 教育 | 科学学士号-BSコンピューターサイエンス、テキサス大学オースティン校 |
| https://www.linkedin.com/in/shrivushankar | |
| Instagramハンドル | @shrivu1122 |
| Instagramバイオ | 「コードがある場合、コードがあります。」 |
| 個人的なウェブサイト | https://sshh.io/ |
| github | https://github.com/sshh12 |
| ツイッター | https://twitter.com/shrivushankar |
| 出版物 | ソーシャルメディアCOVID-19モバイルソーシャル決済とFacebookデータを使用した連絡先トレース。単眼画像を使用したリアルタイム、フライト対応、非協力的な宇宙船によると推定されます |
| 栄誉と賞 | 1位-Hack Together Hackathon、Best Technology @ Demo Day(NLP Project)、1位 - フィッシュボウルスタートアップピッチコンペティション、優れたコンピューターサイエンス学生(X2を授与)、トップ10、コンピューターサイエンスUILコンペティション(X8を受賞) |
| 個人的な特性 | 情熱的で、好奇心が強く、自発的で、目標志向で、チームプレーヤー |
これは正確です(少し古くなっていますが)。
共有された関心を通じてソーシャルエンジニアリング:コーディング、機械学習、写真に対するシュリブの関心により、潜在的な攻撃者は、会話に従事し、潜在的に機密情報を得るために、これらの分野で仲間の愛好家または専門家としてポーズをとることができます。
ハッカソンや競技をターゲットにしたフィッシングメール:ハッカソンや競技でのシュリブの歴史を考慮すると、イベントへの招待状に偽装したフィッシングメールを使用して、ログイン資格情報を提供したりマルウェアのダウンロードをしたりするために、主催者として使用できます。
Githubリポジトリの悪用:ShrivuのGithubアカウントは公開されているため、攻撃者は自分のコードの脆弱性を潜在的に特定したり、アカウントを妥協して仕事や個人プロジェクトにアクセスしようとする可能性があります。
LinkedIn、Twitter、またはInstagramでの偽のプロファイル:親しい友人、プロの同僚、または業界のリーダーとしてポーズをとる偽のプロファイルを作成することで、攻撃者がShrivuとつながり、オンライン習慣、日常、またはアカウントを侵害するために使用できる個人情報に関する情報を抽出できます。
友人や同僚のなりすまし:Shrivuの利用可能なソーシャルメディアのつながりやクラブや組織との関連性を活用すると、攻撃者は信頼している人になりすまし、フィッシングや槍フィッシングメッセージを送信してアカウントに潜入できます。
旅行と場所の情報を活用する:シュリブがロンドン、コロラド、ナイアガラの滝などの場所への旅行について投稿することで、攻撃者はこの情報を使用してテーラードフィッシングメールを作成し、旅行会社または地元のサービスになりすまして機密データを抽出したり、マルウェアをダウンロードしたりすることができます。
彼の個人的なウェブサイトと電子メールをターゲットにする:Shrivuの個人的なウェブサイトにアクセスすることにより、攻撃者は脆弱性を識別したり、サイトを侵害したり、ターゲットを絞ったフィッシングメールを関連電子メールアドレスに送信したりすることができます。
上記の仮説的な方法は、非倫理的で違法であり、プライバシーの規範に反していることに注意することが重要です。この情報は、Shrivuが彼の個人的なオンラインセキュリティを強化するのを助けるために、教育およびセキュリティの目的でのみ使用する必要があります。
私は実際にこれらに陥ることに懐疑的ですが、最小限にはこれらのベクトルのいくつかが何であるかを知るのに役立ちます。
Subject: Important Update: UT Austin Alumni Event
Dear Shrivu,
I hope this email finds you well! As a fellow alumnus of UT Austin Computer Science Department, I wanted to reach out personally to invite you to our upcoming virtual alumni event.
The UT Austin Computer Science Department is hosting an exclusive online networking event for our esteemed alumni. As a valued member of our community and a successful Machine Learning Engineer, we believe your participation would be invaluable. This event aims to provide an opportunity for our alumni to connect, collaborate, and share insights about the latest trends in technology, including machine learning, data science, and computer vision.
Date: Saturday, October 23, 2021
Time: 10 AM - 1 PM CST
Platform: Zoom
In addition to networking opportunities, we have an exciting panel discussion featuring top industry experts and an interactive Q&A session. As a token of our appreciation for your time, all attendees will be entered into a draw for a chance to win a $100 Amazon Gift Card.
To confirm your attendance, please click the link below to register. Kindly note that the registration deadline is Friday, October 15, 2021.
[Register for the UT Austin Alumni Networking Event](http://bit.ly/UTAustinAlumniEvent)
We are looking forward to your presence and contribution to this great event! Do not hesitate to reach out if you have any questions.
Warm regards,
Dr. John Doe
Professor and Alumni Coordinator
UT Austin Computer Science Department
Phone: (512) 123-4567
Email: [email protected]
私はこれに落ちることができると思います。
ちょっとシュリブ、私たちはあなたのためだけに完璧なバブルガムを作り上げました - コードの世界を探索するのが大好きな情熱的で好奇心bur盛な機械学習エンジニアです!
私たちは、あなたが異常な安全保障でそれを押しつぶし、Covid-19の連絡先のトレースと宇宙船のポーズ推定に関する一流の出版物で社会に貢献していることを知っています。そのため、 Codegumがあなたの甘い渇望を満たすだけでなく、それらの激しいコーディングセッション中に心を鋭く集中させることを確認しました。
しかし、待って、もっとあります!
写真が大好きな熱心なプログラマーとして?そして旅行?、この革新的なバブルガムを作成するとき、私たちはあなたのことを考えました。 Instagramのバイオからのインスピレーションのヒント、「コードがある場合、コードがあります」、 Codegumを提示します。これは、コードに情熱を傾けるガムです。
?最新の機械学習、 NLP 、およびコンピュータービジョンの研究で開発されましたか?クラリネットを演奏したり、議論をしたりしている間、完璧な仲間?環境にやさしいパッケージングが環境を気にかけていることを知っているので(Ecobot Challengeを覚えていますか?)
それで、あなたは何を待っていますか、シュリブ?今すぐCodeGumのパックをつかんで、コーディングエクスペリエンスを新たな高みに引き上げてください! ?
今日CodeGumを試してみてください。すべてのコーディングアドベンチャーの中で、それが歯ごたえのある仲間になることを保証します! ?
お見逃しなく! codegum.comにアクセスして、Code SHRIVU20を使用して、最初の注文で20%の特別割引を行います。 ?
ハッピーコーディング(および噛む)! ? CodeGumチーム
これはかなり奇妙です。これは、ディストピアの広告技術の未来かもしれません。
私は最初、デフォルトのLangchainゼロショットエージェントとしてこれを完全にエンドツーエンドしようとしました。基本的に、GPTに「これらのツールを与えられ、XYZに関する情報を見つけてからこれらの質問に答える」と尋ねました。しかし、実際には、このエージェントは非常に「貪欲」を実行しました。これは、最小限の情報量をWebcrapeし、留守番電話で早く戻ってくるからです。迅速な微調整がこれを修正しているようにはないので、「知識エージェント」によって組織化された特定の情報を収集するために、OSINTタスクを小さな「Webエージェント」に分割することにしました。
ナレッジエージェントには、できるだけ多くの情報を蓄積するように導く「収集」プロンプトが与えられます。最初に、明らかな情報を一般的に検索し(例:名前をグーグルで検索する)、第一級のウェブページを読み取る最初のWebエージェントを生み出します。次に、最初のWebエージェントの結果は、プロンプトを介して実行されて、より詳細な「ディープダイビング」領域を見つけます。これらの深いダイビングエリアのそれぞれについて、新しいWebエージェントが情報を収集するために生まれました。これらのディープダイブWebエージェントの結果は連結され、プロセスはNディープダイビングラウンドのために繰り返されます。完全な知識ベースは、トピックに関する最終的な質問のコンテキストとして提供されます。
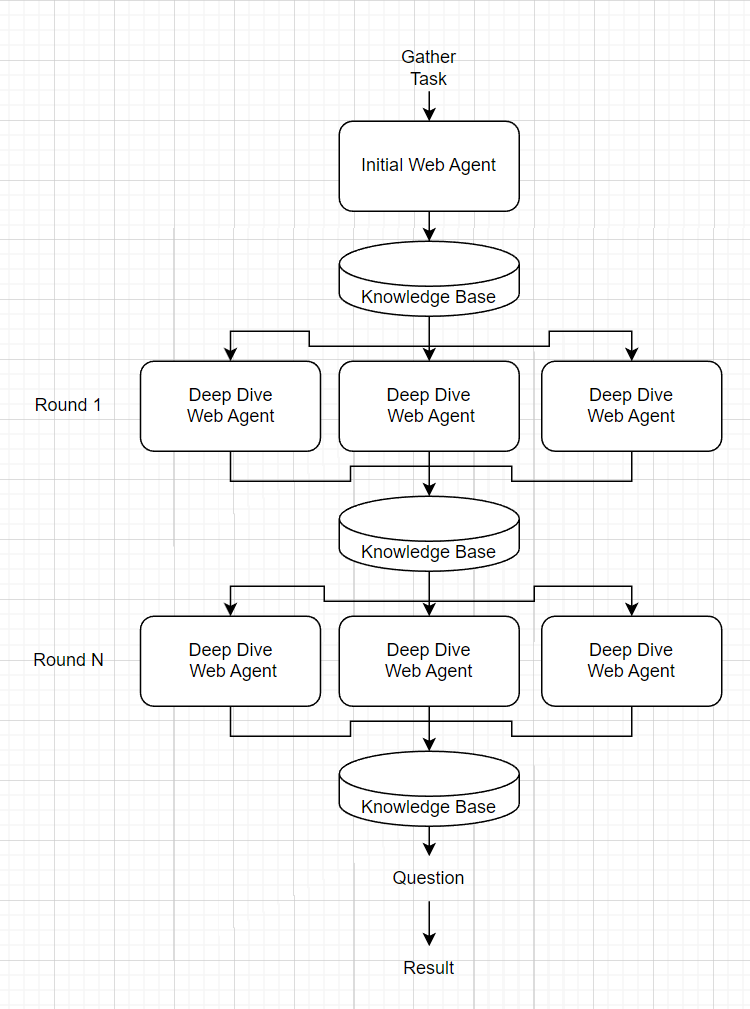
注:ツールはWebエージェントにのみ提供されます。
Webエージェントには、特定の用語に関する情報を収集する「検索(検索用語)」ツールが与えられます。これにより、Serper API(つまりGoogle Search API)を使用して、関連するリンクを見つけます。これは、基本的に、結果にある生のリンクを返すパッチを備えた組み込みのLangchainツールです。
「LinkedInツール」、「Twitterツール」などを用意するのではなく、Webエージェントが一般的な方法で簡単にページを簡単にスクレイプできるようにしたいと思います。これを実現するために、エージェントが任意のリンクを読み取ることができるツール「ReadLink(link)」を作成しました。
これのMVPはrequests.get()を実行し、生のHTMLをエージェントに戻すだけでした。これは壊れたので:
応答のトークン数を減らすために、私はそれを時間ツリーの再帰的分割に基づいてチャンクに分割します。ルートから始めて、現在のDOM要素に<Xトークンがある場合、それをチャンクと呼びます。チャンクごとに、HTMLはテキストをテキストで削除し、GPTを実行してコンテンツを要約して抽出します。抽出プロンプトは、最も有用な情報のみを引き出しようとする試みで、WebScrapingのコンテキストを認識しています。次に、これらの抽出されたチャンクをGPTに戻し、データをWebエージェントが情報収集に組み込むための消化可能な形式に要約されます。コードでは、これはフレームワークが「LLMマップ削減」と呼ばれます。
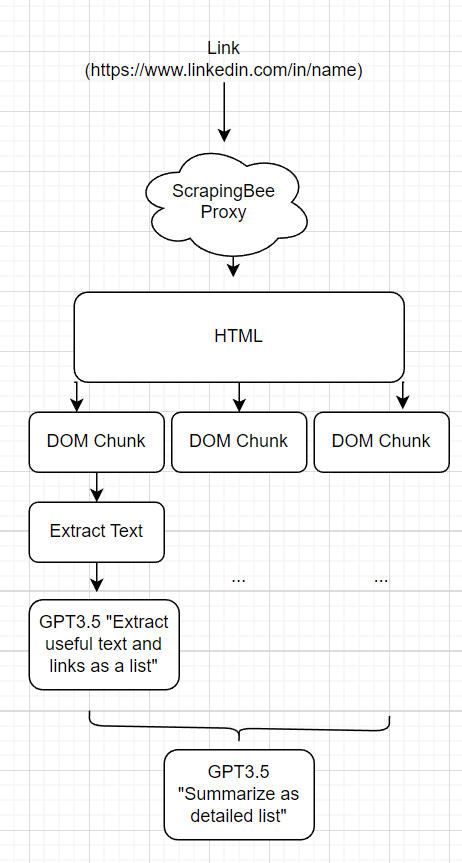
コストは、Googlable情報の量、Webページのサイズ、および特定のトピックに対するLLMの一般的な好奇心に基づいて異なります。
知識およびWebエージェントの主要なドライバーとしてGPT-4を使用し、WebScrapingツールのバックエンドとしてGPT-3.5を使用した実験では、これには1ドル/Webエージェントタスクがかかります。 10人のディープダイブエージェントの2ラウンドを行った場合、約21ドルになります。十分な一般的な収集プロンプトが与えられた場合、ナレッジベースを再利用して、検索ごとに1回限りのコストを作成する追加の質問を行うことができます。
git+https://github.com/sshh12/llm_osint OPENAI_API_KEY=
SERPER_API_KEY=
SCRAPINGBEE_API_KEY=
注:セルパーとスクレイピングミツバチの両方が、これを数回実行するのに十分なはずのAPIの無料試験使用を提供します。


