ClassGPT
1.0.0
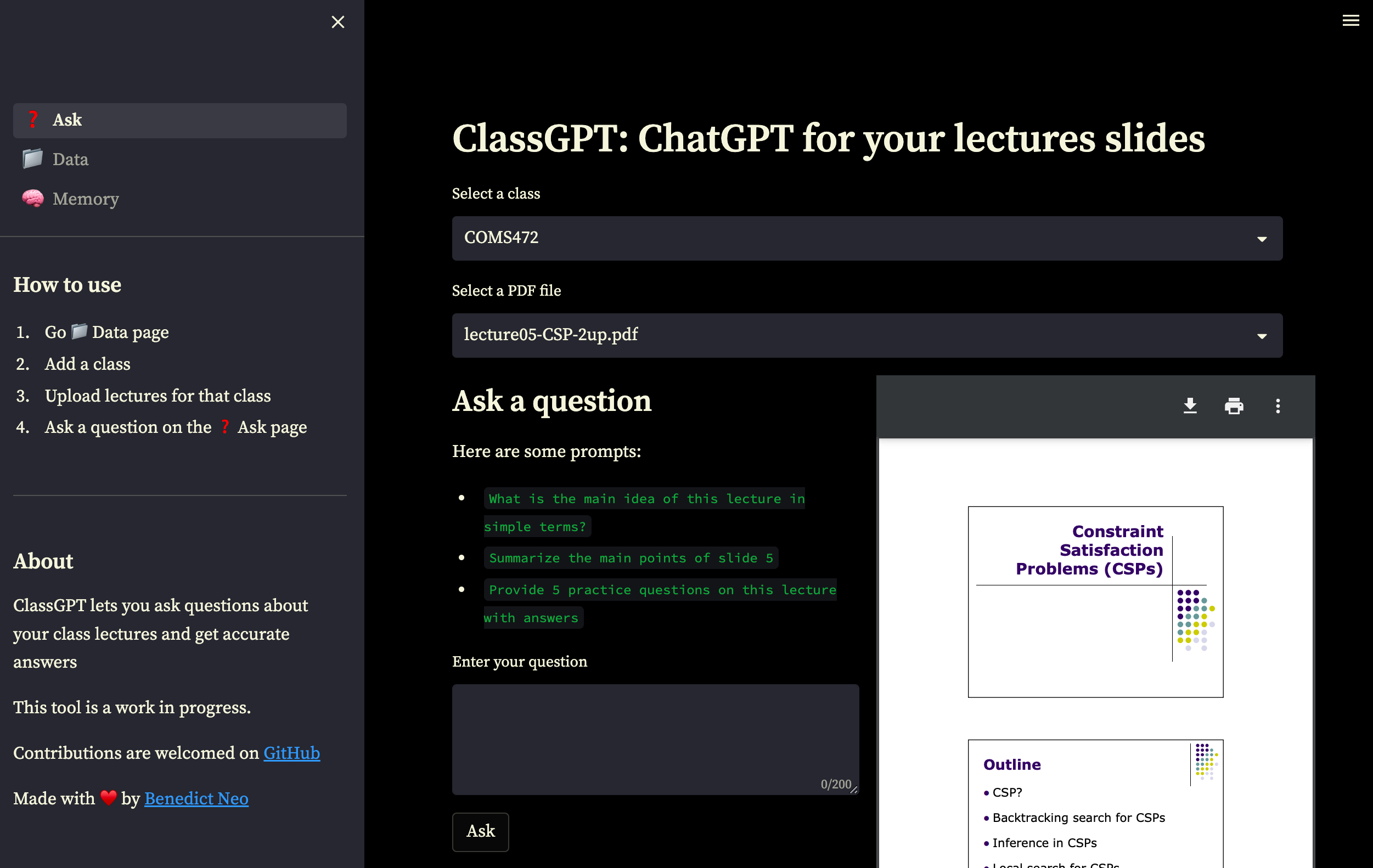
私の講義スライドのChatGpt
LlamaindexとLangchainを搭載した、流線で構築されています。
Openaiの最新のChatGPT APIを使用します。
Athensgptに触発されました
GPTSimpleVectorIndexによるインデックス構造text-embedding-ada-002モデルは、埋め込みを作成するために使用されますgpt-3.5-turboを使用します aws configureユニークな名前のS3バケットを作成します
コードベースのバケット名を変更します(作成したものにbucket_name = "classgpt"を探します。
[.env.local.example]を.envに変更し、Openai資格情報を追加します
conda create -n classgpt python=3.9
conda activate classgpt pip install -r requirements.txt cd app/
streamlit run app/01_❓_Ask.py別の方法では、Dockerを使用できます
docker compose up次に、新しいタブを開き、http:// localhost:8501/に移動します
トークンは言葉の断片と考えることができます。 APIがプロンプトを処理する前に、入力はトークンに分解されます。これらのトークンは、単語が始まるか終わりの場所で正確に切り取られていません - トークンには、トレーリングスペースやサブワードさえも含まれます。長さの観点からトークンを理解するためのいくつかの有用な経験則を次に示します。
Openaiトークネイザーツールをお試しください
ソース
埋め込みは、浮動小数点数のベクトル(リスト)です。 2つのベクトル間の距離は、その関連性を測定します。小さな距離は、高い関連性と広い距離が低い関連性を示唆しています。
text-embedding-ada-002の場合、コストは0.0004 / 1kトークンまたは3000ページ /ドルです
gpt-3.5-turboモデル(chatgptapi)の場合、コストは$0.002 / 1K tokensです
text-davinci-003モデルの場合、コストは$0.02 / 1K tokensです
データの読み込み
マルチモーダル
chatgpt
sourceコマンドが機能しません

