descript audio codec
1.0.0
このリポジトリには、RVQGANが改善された高忠実度オーディオ圧縮というタイトルのペーパーで紹介された、高忠実度の一般的なニューラルオーディオコーデックであるDecript Audio Codec(.DAC)のトレーニングと推論スクリプトが含まれています。
ARXIVペーパー:RVQGANの改善による高忠実度オーディオ圧縮
?デモサイト
modelモデルの重み
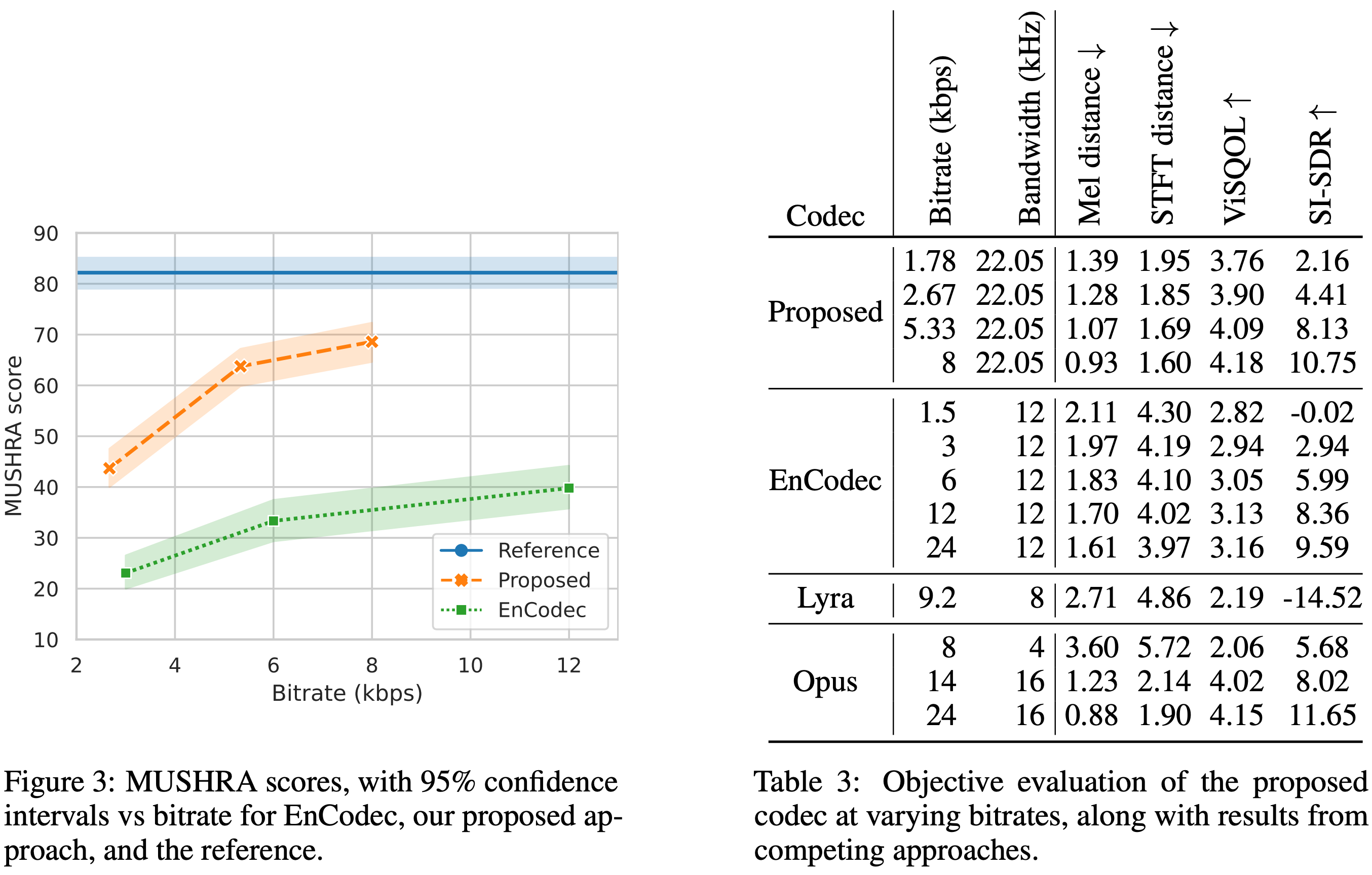
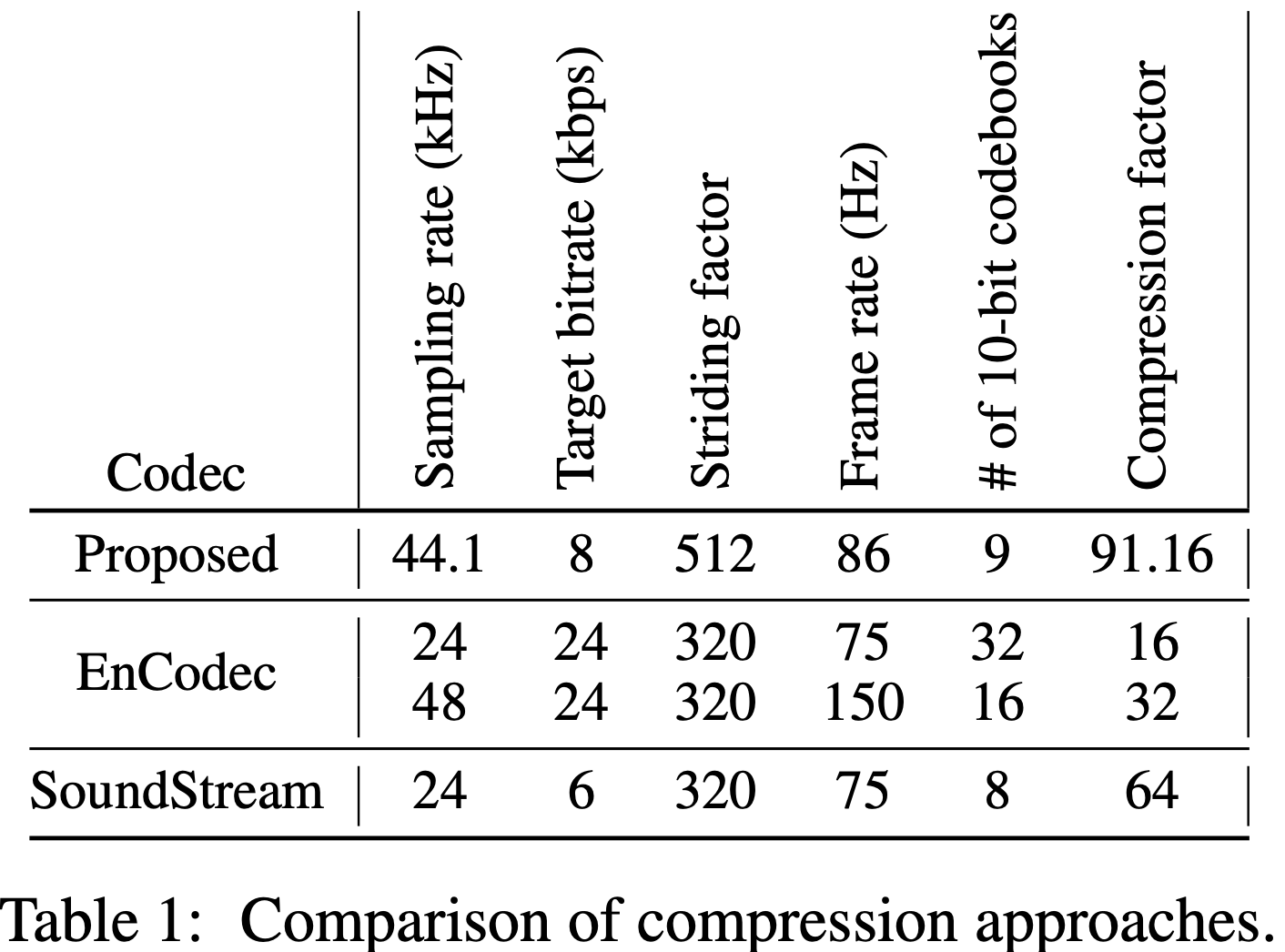
記述オーディオコーデックを使用すると、 44.1 kHzオーディオを8 kbpsビットレートで離散コードに圧縮できます。
?これは、例外的な忠実度を維持し、アーティファクトを最小限に抑えながら、約90倍の圧縮です。
?私たちのユニバーサルモデルは、すべてのドメイン(音声、環境、音楽など)で機能し、すべてのオーディオの生成モデリングに広く適用されます。
?すべてのオーディオ言語モデリングアプリケーション(Audiolms、MusicLMS、MusicGenなど)のEncodecのドロップイン交換として使用できます。
pip install descript-audio-codec
または
pip install git+https://github.com/descriptinc/descript-audio-codec
Weightsは、MITライセンスの下でこのレポの一部としてリリースされます。 16 kHz、24kHz、および44.1kHzのサンプリングレートをネイティブにサポートできるモデルの重みをリリースします。 encodeまたはdecodeコマンドを最初に実行すると、ウェイトは自動的にダウンロードされます。次のコマンドのいずれかを使用してキャッシュできます
python3 -m dac download # downloads the default 44kHz variant
python3 -m dac download --model_type 44khz # downloads the 44kHz variant
python3 -m dac download --model_type 24khz # downloads the 24kHz variant
python3 -m dac download --model_type 16khz # downloads the 16kHz variantエンコードとデコードに必要なすべての依存関係をインストールするDockerFileを提供します。ビルドプロセスは、画像内のデフォルトモデルの重みをキャッシュします。これにより、インターネット接続なしで画像を使用できます。以下の手順を参照してください。
python3 -m dac encode /path/to/input --output /path/to/output/codes
このコマンドは、入力ファイルと同じ名前の.dacファイルを作成します。また、入力ルートに対するディレクトリ構造を保持し、出力ディレクトリに再作成します。 python -m dac encode --help使用して、その他のオプションを使用してください。
python3 -m dac decode /path/to/output/codes --output /path/to/reconstructed_input
このコマンドは、入力ファイルと同じ名前の.wavファイルを作成します。また、入力ルートに対するディレクトリ構造を保持し、出力ディレクトリに再作成します。 python -m dac decode --helpを使用して、その他のオプションを使用してください。
import dac
from audiotools import AudioSignal
# Download a model
model_path = dac . utils . download ( model_type = "44khz" )
model = dac . DAC . load ( model_path )
model . to ( 'cuda' )
# Load audio signal file
signal = AudioSignal ( 'input.wav' )
# Encode audio signal as one long file
# (may run out of GPU memory on long files)
signal . to ( model . device )
x = model . preprocess ( signal . audio_data , signal . sample_rate )
z , codes , latents , _ , _ = model . encode ( x )
# Decode audio signal
y = model . decode ( z )
# Alternatively, use the `compress` and `decompress` functions
# to compress long files.
signal = signal . cpu ()
x = model . compress ( signal )
# Save and load to and from disk
x . save ( "compressed.dac" )
x = dac . DACFile . load ( "compressed.dac" )
# Decompress it back to an AudioSignal
y = model . decompress ( x )
# Write to file
y . write ( 'output.wav' )必要なすべての依存関係を備えたDocker画像を構築するためのDockerFileを提供します。
画像を構築します。
docker build -t dac .
画像を使用します。
CPUでの使用:
docker run dac <command>
GPUでの使用:
docker run --gpus=all dac <command>
<command> 、上記の圧縮および再構成コマンドの1つになります。たとえば、圧縮を実行する場合は、
docker run --gpus=all dac python3 -m dac encode ...
ベースラインモデルの構成は、次のコマンドを使用してトレーニングできます。
正しい依存関係をインストールしてください
pip install -e ".[dev]"
DockerfileとDocker Composeのセットアップを提供し、実行している実験を簡単にします。
Docker画像を構築するには:
docker compose build
次に、コンテナを起動するには、次のことを行います。
docker compose run -p 8888:8888 -p 6006:6006 dev
ポート引数( -p )はオプションですが、コンテナ内でJupyterおよびTensorboardインスタンスを起動する場合は便利です。 Jupyterのデフォルトのパスワードはpasswordであり、現在のディレクトリは/u/home/srcに取り付けられており、これも作業ディレクトリになります。
次に、トレーニングコマンドを実行します。
export CUDA_VISIBLE_DEVICES=0
python scripts/train.py --args.load conf/ablations/baseline.yml --save_path runs/baseline/
export CUDA_VISIBLE_DEVICES=0,1
torchrun --nproc_per_node gpu scripts/train.py --args.load conf/ablations/baseline.yml --save_path runs/baseline/
CLI +トレーニング機能をテストするための2つのテストスクリプトを提供します。これらのテストを開始する前に、トレーニングの前提条件が満たされていることを確認してください。これらのテストを起動するには、実行してください
python -m pytest tests