TTS dataset tools
1.0.0
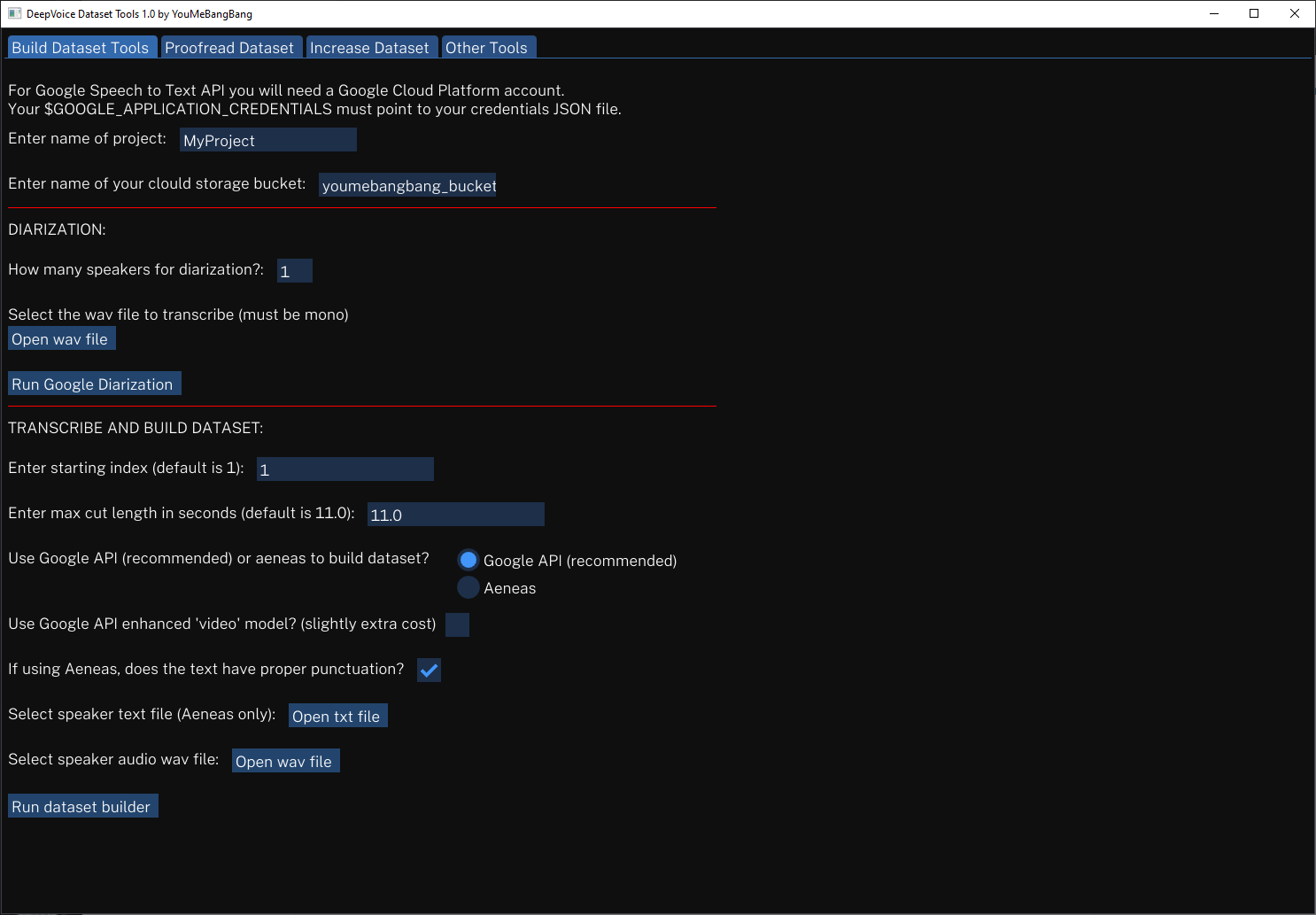
Transkripsi audio melalui Google Speech ke API Teks dengan pemisahan speaker (Diarization). Secara otomatis menghasilkan dataset TTS menggunakan audio dan teks terkait. Menggunakan Google API untuk menyalin pemotongan yang telah dibagi dengan istirahat keheningan maksimum (disarankan). Atau gunakan Aeneas untuk memaksa AUDIO ke audio. Mengoreksi dan mengedit pemotongan dengan cepat.
Untuk Google Speech ke API Teks Anda akan memerlukan akun Google Cloud Platform. Anda $ google_application_credentials Env variable harus menunjukkan jalur file kredensial JSON Anda. Google menawarkan layanan senilai $ 300 dan 3 bulan gratis di akun baru.
Jalankan tools.py untuk alat GUI.
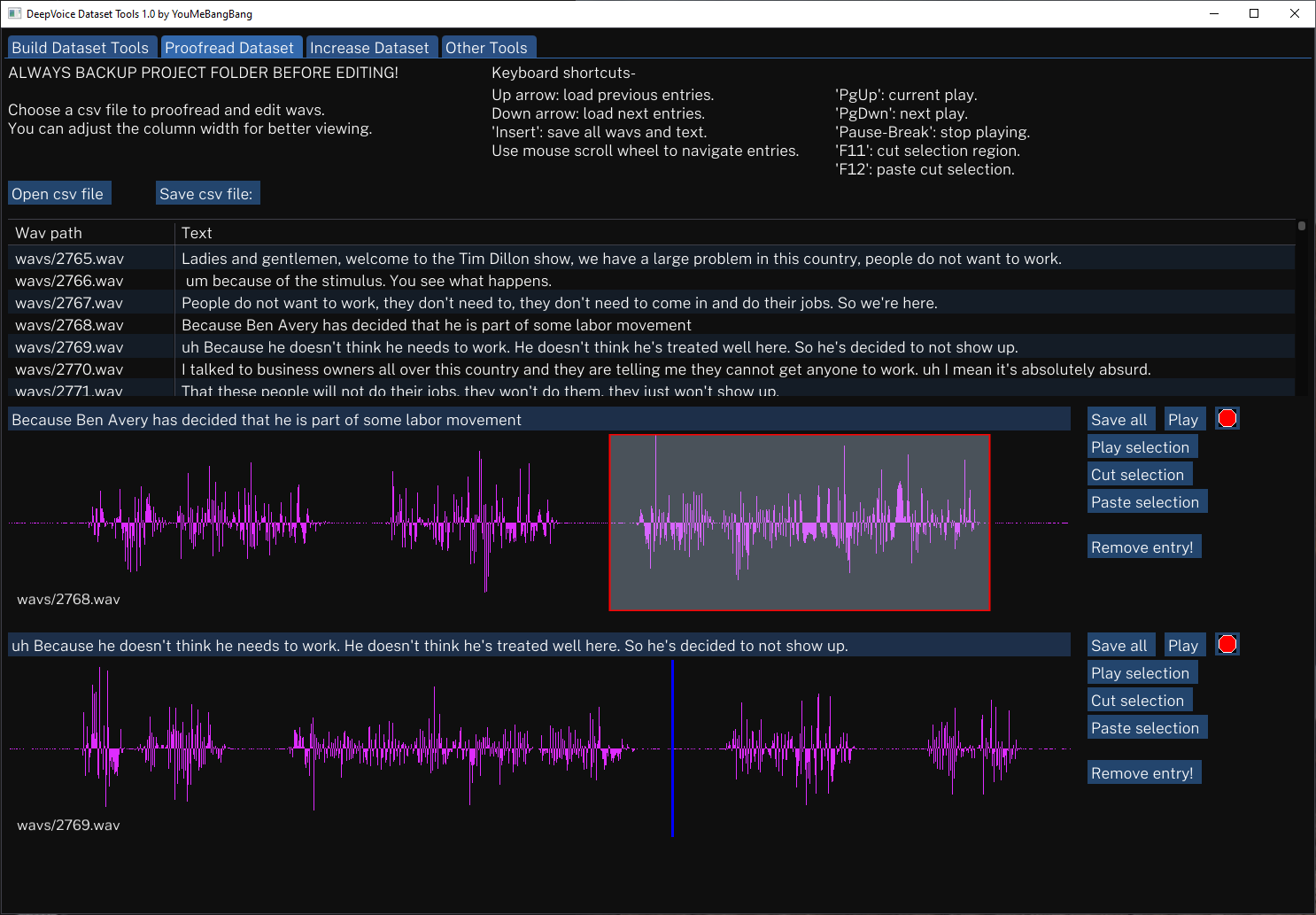
Keterbatasan saat ini adalah bahwa Anda perlu menyesuaikan lebar kolom dari bagian proofreading dan ketika menavigasi entri Anda harus mengambil fokus dari kotak teks input saat ini dan berikutnya atau kotak teks tidak akan diperbarui. Versi berikutnya dari Dearpy GUI akan menyelesaikan masalah ini.
Menggunakan VPN akan mengganggu ucapan Google yang panjang ke permintaan API teks.
Menggunakan versi yang lebih lama dari Dearpygui di momen, saya akan bermigrasi pada akhirnya.
Pip Instal Numpy -Pengguna
Pip Instal PyDub -Pengguna
Pip Instal Dearpygui == 0.6.415 -Pengguna
Pip Instal Google-Cloud-Speech-Pengguna
Pip Instal Google-Cloud-Storage-Pengguna
Pip Instal SimpleAudio -Pengguna
*Jika Anda tidak dapat membangun SimpleAudio, pastikan Anda telah menginstal GCC: Sudo apt-get update, sudo apt-get install build-eSSentials
Pip Instal Sox -Pengguna
Linux Environment direkomendasikan untuk opsi Aeneas, di Windows Aeneas tidak akan dapat membuat pemotongan lebih lama karena masalah memori.
wget https://raw.githubusercontent.com/readbeyond/aeneas/master/install_dependencies.sh
bash install_dependencies.sh
Pip Instal Numpy -Pengguna
Pip Instal Aeneas -Pengguna
Instalasi Uji: Python -M Aeneas.Diagnostics
Pip Instal PyDub -Pengguna
Pip Instal Dearpygui == 0.6.415 -Pengguna
Pip Instal Google-Cloud-Speech-Pengguna
Pip Instal Google-Cloud-Storage-Pengguna
Pip Instal SimpleAudio -Pengguna
Pip Instal Sox -Pengguna
Jika Anda mendapatkan kesalahan libpython:
sudo apt instal libasound2-dev
Edit file Bashrc Anda dengan mengetik: sudo nano ~/.bashrc
Kemudian tambahkan garis di akhir dengan info Anda tergantung di mana paket Anda diinstal:
Ekspor ld_library_path = "/[yourhomePath]/anaconda3/envs/[yourenv]/lib/"
ATAU
Ekspor ld_library_path = "/[yourhomePath]/. conda/envs/[yourenv]/lib/"
Atau jika lingkungan dasar
Ekspor ld_library_path = "/[yourhomePath]/anaconda3/lib/"
Tekan Ctrl+O untuk mengekspor file yang diperbarui. Kemudian Ctrl+X untuk keluar.
Ketik Sumber ~/.bashrc untuk mengaktifkan jalur baru.
Tutorial Video: https://www.youtube.com/watch?v=te7pui2xeje
Beberapa hal akan meningkatkan kualitas pemotongan Anda, meskipun Anda harus selalu mengoreksi mereka sebelum pelatihan. Untuk bahasa selain bahasa Inggris, Anda dapat dengan mudah mengedit baris perintah Aeneas dan penggantian karakter sesuai kebutuhan Anda, dan mengganti kode bahasa Google En-US dengan kode bahasa Anda (https://cloud.google.com/speech-to-text/docs/languages). Periksa apakah hal -hal seperti judul bab disertakan. Pembicara dengan ucapan yang lambat dan bahkan berjalan akan membuat potongan terbersih, sementara penutur cepat cenderung menjalankan kata -kata bersama dan dapat menyebabkan beberapa kata, potongan kata, dialihkan ke potongan berikutnya di mana ia harus diedit. Hapus semua musik jika mampu.


