Jina AI a publié Reader-LM, un modèle de langage léger spécialement conçu pour convertir le HTML en Markdown propre. Il peut supprimer efficacement le contenu encombré des pages Web, tel que les publicités et les scripts, pour générer des fichiers Markdown clairement structurés sans expressions régulières complexes ni opérations manuelles. Reader-LM est disponible en deux versions : Reader-LM-0.5B et Reader-LM-1.5B, toutes deux optimisées pour fonctionner efficacement même dans des environnements aux ressources limitées et prendre en charge des contextes jusqu'à 256 000 jetons.
Jina AI a lancé deux petits modèles de langage spécialement conçus pour convertir le contenu HTML original en un format Markdown propre et soigné, nous permettant ainsi de nous débarrasser du traitement fastidieux des données des pages Web.
Le plus grand point fort de ce modèle appelé Reader-LM est qu'il peut convertir rapidement et efficacement le contenu Web en fichiers Markdown.
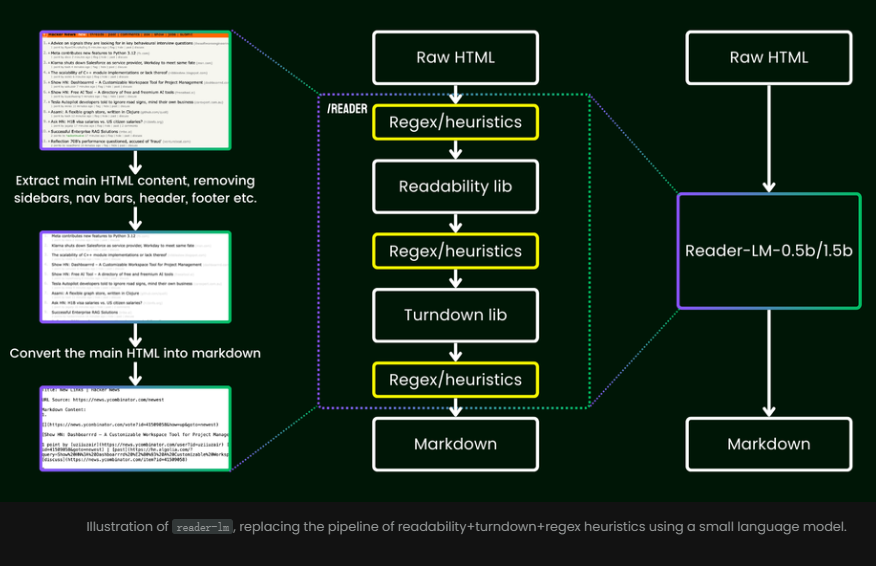
L’avantage de son utilisation est que vous n’avez plus besoin de vous appuyer sur des règles complexes ou des expressions régulières laborieuses. Ces modèles suppriment intelligemment et automatiquement le contenu encombré des pages Web, tel que les publicités, les scripts et les barres de navigation, et présentent enfin un format Markdown clair et organisé.
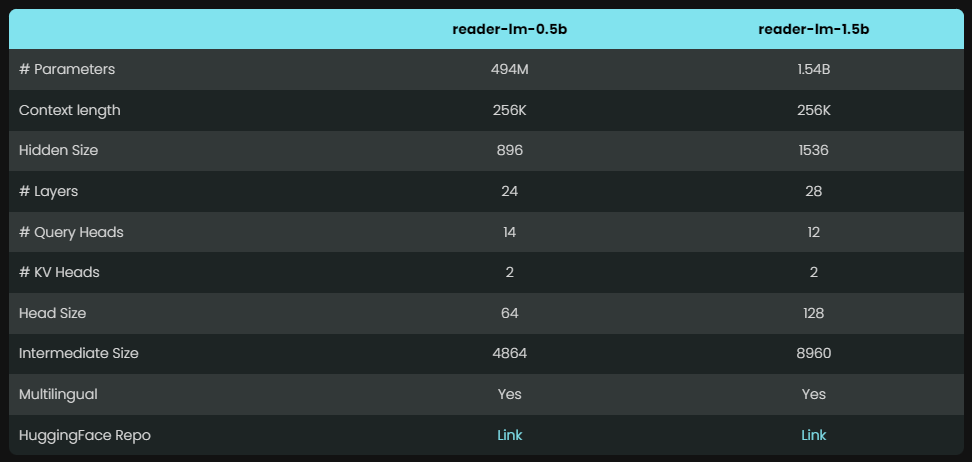
Reader-LM propose deux modèles avec des paramètres différents, à savoir Reader-LM-0.5B et Reader-LM-1.5B. Bien que le nombre de paramètres de ces deux modèles ne soit pas énorme, ils sont optimisés pour la tâche de conversion de HTML en Markdown. Les résultats sont surprenants et leurs performances dépassent celles de nombreux grands modèles de langage.
Grâce à leur conception compacte, ces modèles peuvent fonctionner efficacement dans des environnements aux ressources limitées. Ce qui est encore plus louable, c'est que Reader-LM prend non seulement en charge plusieurs langues, mais peut également gérer des données contextuelles jusqu'à 256 000 jetons, ce qui permet de gérer facilement des fichiers HTML même complexes.
Contrairement aux méthodes traditionnelles qui reposent sur des expressions régulières ou des paramètres manuels, Reader-LM fournit une solution de bout en bout qui nettoie automatiquement les données HTML et extrait les informations clés.
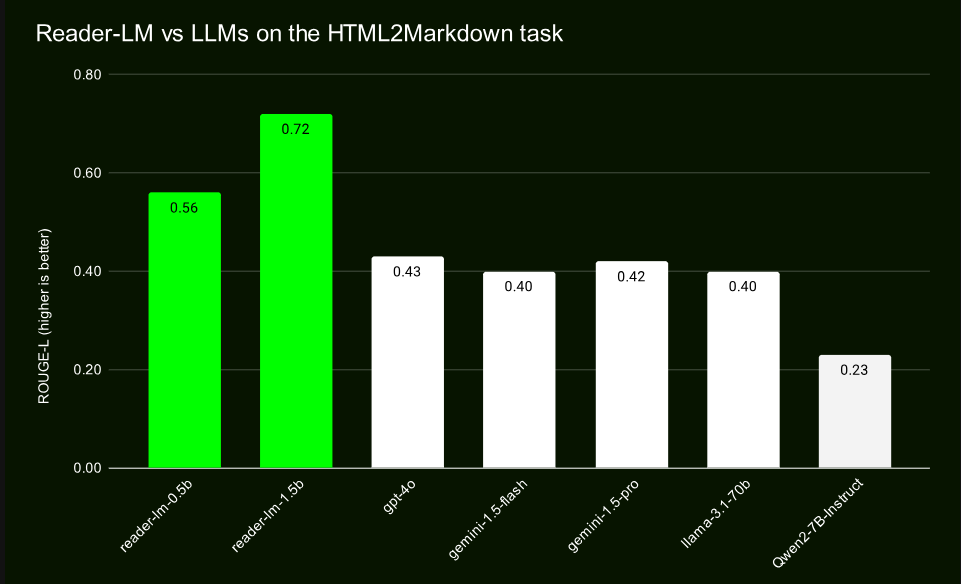
Grâce à des tests comparatifs avec des modèles à grande échelle tels que GPT-4 et Gemini, Reader-LM a démontré d'excellentes performances, notamment en termes de préservation de la structure et d'utilisation de la syntaxe Markdown. Reader-LM-1.5B fonctionne particulièrement bien dans divers indicateurs, avec un score ROUGE-L de 0,72, démontrant sa grande précision dans la génération de contenu, et son taux d'erreur est également nettement inférieur à celui de produits similaires.
Grâce à la conception compacte de Reader-LM, il est plus léger en termes d'utilisation des ressources matérielles, en particulier le modèle 0,5B, qui peut fonctionner sans problème dans des environnements à faible configuration comme Google Colab. Malgré sa petite taille, Reader-LM dispose toujours de puissantes capacités de traitement de contexte long et peut traiter efficacement du contenu Web volumineux et complexe sans affecter les performances.
En termes de formation, Reader-LM adopte un processus en plusieurs étapes et se concentre sur l'extraction de contenu Markdown à partir de HTML original et bruyant.
Le processus de formation comprend le couplage d'un grand nombre de pages Web réelles et de données synthétiques, garantissant l'efficacité et la précision du modèle. Après une formation en deux étapes soigneusement conçue, Reader-LM a progressivement amélioré sa capacité à traiter des fichiers HTML complexes et a efficacement évité le problème de la génération répétée.
Introduction officielle : https://jina.ai/news/reader-lm-small-lingual-models-for-cleaning-and-converting-html-to-markdown/
Dans l'ensemble, Reader-LM fournit une solution efficace, pratique et précise pour la conversion HTML vers Markdown. Sa conception légère le rend facile à exécuter dans divers environnements, ce qui en fait un choix idéal pour le traitement des données de pages Web. Pour plus d’informations, veuillez visiter le lien d’introduction officiel.