embcompare
v1.0.1
Un simple outil Python pour la comparaison d'intégration
Embcompare est un petit package Python fortement inspiré par l'outil de comparateur d'intégration qui vous aide à comparer vos intérêts visuellement et numériquement.
Embcompare garde les choses simples. Tous les calculs sont fabriqués en mémoire et le package n'apporte aucune gestion du stockage d'intégration.
Si vous avez besoin d'un outil pour stocker, comparer et suivre vos expériences, vous aimerez peut-être le projet Vectory.
# basic install
pip install embcompare
# installation with the gui tool
pip install embcompare[gui]Embcompare fournit une CLI avec trois sous-communs:
embcompare add est utilisé pour créer ou mettre à jour un fichier YAML contenant toutes les incorporations Infos: chemin, format, étiquettes, fréquences à terme, ...;embcompare report est utilisé pour générer des rapports JSON contenant des mesures de comparaison;embcompare gui est utilisée pour démarrer un webApp rationalisé pour comparer vos intégres visuellement.Embcompare utilise un fichier YAML pour référencer les incorporations et les informations pertinentes. Par défaut, Embcompare recherche un fichier nommé embcompare.yaml dans le répertoire de travail actuel.
embeddings :
first_embedding :
name : My first embedding
path : /abspath/to/firstembedding.json
format : json
frequencies : /abspath/to/freqs.json
frequencies_format : json
labels : /abspath/to/labels.pkl
labels_format : pkl
second_embedding :
name : My second embedding
path : /abspath/to/secondembedding.json
format : word2vec
frequencies : /abspath/to/freqs.pkl
frequencies_format : pkl
labels : /abspath/to/labels.json
labels_format : json La commande embcompare add permet de mettre à jour ce fichier de manière programmatique (et même de le créer s'il n'existe pas).
Embcompare vise à aider à comparer l'intégration grâce à des mesures numériques qui peuvent être utilisées pour vérifier si une nouvelle intégration générée est très différente de la dernière. Le embcompare report peut être utilisé de deux manières:
embcompare report first_embedding
# creates a first_embedding_report.json file containing some infos about the embeddingembcompare report first_embedding second_embedding
# creates a first_embedding_second_embedding_report.json file containing comparison metrics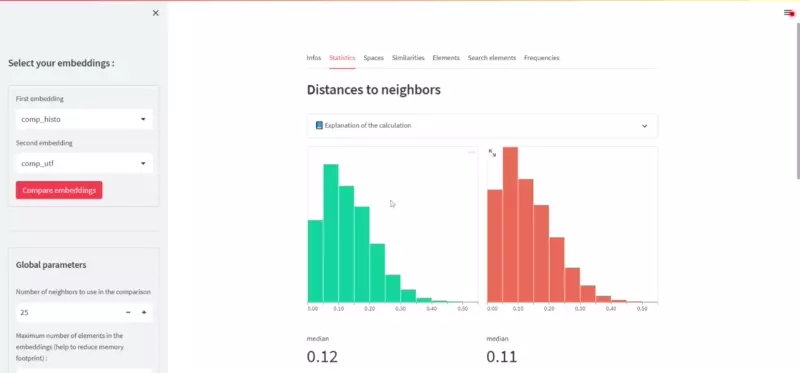
L'interface graphique est également très pratique pour comparer les intégres. Pour démarrer l'interface graphique, utilisez l' embcompare gui . Il lancera une application Streamlit qui vous permettra de comparer visuellement les intégres que vous avez ajoutés dans le fichier de configuration.
Embcompare fournit plusieurs classes pour charger et comparer les intégres.
La classe Embedding est l'enfant de la classe gensim.KeyedVectors .
Il ajoute peu de fonctionnalités:
import json
import gensim . downloader as api
from embcompare import Embedding
word_vectors = api . load ( "glove-wiki-gigaword-100" )
with open ( "frequencies.json" , "r" ) as f :
word_frequencies = json . load ( f )
embedding = Embedding . load_from_keyedvectors ( word_vectors , frequencies = word_frequencies )
neigh_dist , neigh_ind = embedding . compute_neighborhoods () La classe EmbeddingComparison est destinée à comparer deux objets Embedding :
from embcompare import EmbeddingComparison , load_embedding
emb1 = load_embedding ( "first_emb.bin" , embedding_format = "fasttext" , frequencies_path = "freqs.pkl" )
emb2 = load_embedding ( "second_emb.bin" , embedding_format = "word2vec" , frequencies_path = "freqs.pkl" )
comparison = EmbeddingComparison ({ "emb1" : emb1 , "emb2" : emb2 }, n_neighbors = 25 )
comparison . neighborhoods_similarities [ "word" ]
# 0.867 La classe EmbeddingReport est utilisée pour générer un petit rapport sur une intégration:
from embcompare import EmbeddingReport , load_embedding
emb1 = load_embedding ( "first_emb.bin" , embedding_format = "fasttext" , frequencies_path = "freqs.pkl" )
report = EmbeddingReport ( emb1 )
report . to_dict ()
# {
# "vector_size": 300,
# "mean_frequency": 0.00012,
# "mean_distance_neighbors": 0.023,
# ...
# } La classe EmbeddingComparisonReport est utilisée pour générer un petit rapport de comparaison à partir de deux incorporation:
from embcompare import EmbeddingComparison , EmbeddingComparisonReport , load_embedding
emb1 = load_embedding ( "first_emb.bin" , embedding_format = "fasttext" , frequencies_path = "freqs.pkl" )
emb2 = load_embedding ( "second_emb.bin" , embedding_format = "word2vec" , frequencies_path = "freqs.pkl" )
comparison = EmbeddingComparison ({ "emb1" : emb1 , "emb2" : emb2 })
report = EmbeddingComparisonReport ( comparison )
report . to_dict ()
# {
# "embeddings" : [
# {
# "vector_size": 300,
# "mean_frequency": 0.00012,
# "mean_distance_neighbors": 0.023,
# ...
# },
# ...
# ],
# "neighborhoods_similarities_median": 0.012,
# ...
# } L'interface graphique est construite avec rational. Nous avons essayé de moduler l'application afin que vous puissiez plus facilement réutiliser certaines fonctionnalités pour votre application Streamlit personnalisée:
# embcompare/gui/app.py
from embcompare . gui . features import (
display_custom_elements_comparison ,
display_elements_comparison ,
display_embeddings_config ,
display_frequencies_comparison ,
display_neighborhoods_similarities ,
display_numbers_of_elements ,
display_parameters_selection ,
display_spaces_comparison ,
display_statistics_comparison ,
)
from embcompare . gui . helpers import create_comparison
def main ():
"""Streamlit app for embeddings comparison"""
config_embeddings = config [ CONFIG_EMBEDDINGS ]
(
tab_infos ,
tab_stats ,
tab_spaces ,
tab_neighbors ,
tab_compare ,
tab_compare_custom ,
tab_frequencies ,
) = st . tabs (
[
"Infos" ,
"Statistics" ,
"Spaces" ,
"Similarities" ,
"Elements" ,
"Search elements" ,
"Frequencies" ,
]
)
# Embedding selection (inside the sidebar)
with st . sidebar :
parameters = display_parameters_selection ( config_embeddings )
# Display informations about embeddings
with tab_infos :
display_embeddings_config (
config_embeddings , parameters . emb1_id , parameters . emb2_id
)
comparison = create_comparison (
config_embeddings ,
emb1_id = parameters . emb1_id ,
emb2_id = parameters . emb2_id ,
n_neighbors = parameters . n_neighbors ,
max_emb_size = parameters . max_emb_size ,
min_frequency = parameters . min_frequency ,
)
# Display number of element in both embedding and common elements
with tab_infos :
display_numbers_of_elements ( comparison )
# Display statistics
with tab_stats :
display_statistics_comparison ( comparison )
if not comparison . common_keys :
st . warning ( "The embeddings have no element in common" )
st . stop ()
# Comparison below are based on common elements comparison
with tab_spaces :
display_spaces_comparison ( comparison )
with tab_neighbors :
display_neighborhoods_similarities ( comparison )
with tab_compare :
display_elements_comparison ( comparison )
with tab_compare_custom :
display_custom_elements_comparison ( comparison )
with tab_frequencies :
display_frequencies_comparison ( comparison )

