rrpl
1.0.0
4824578 Les blocs de construction peuvent être emballés horizontalement ou verticalement en utilisant - et | Symboles respectivement pour composer des glyphes plus complexes. Ces symboles peuvent être enchaînés pour emballer plus de deux symboles avec une pièce égale.
Exemple:
| Résultat | Code | Résultat | Code |
|---|---|---|---|
27-26-26 | 2468|24578 |
( et ) Les symboles peuvent être utilisés pour regrouper les composants, donc un emballage horizontal et vertical mixte peut se produire dans le bon ordre.
Exemple:
| Résultat | Code | Résultat | Code |
|---|---|---|---|
(48|37)-(25678|27)-(37|15) | (46-68)|(246-268)|(24-28) |
D'autres caractères et radicaux peuvent être référencés directement pour construire un nouveau caractère. L'analyseur videra le contenu du glyphe de référence directement dans la chaîne, similaire à la fonction C / C ++ #include . Cela rend particulièrement facile de décrire les caractères chinois les plus compliqués, car la plupart d'entre eux sont constitués de radicaux.
Exemple:
| Résultat | Code | Résultat | Code |
|---|---|---|---|
廿|468|由|(八) | ((車|(山))-(殳))|(手) | ||
((口)-(口))|(甲)|十 | (((木)-(缶)-(木))|(冖))|((鬯)-(彡)) |
Un analyseur de base est inclus dans rrpl_parser.js , qui alimente cette démo interactive. Il peut être utilisé avec JavaScript côté navigateur ainsi que Node.js:
//require the module: (or in html, <script src="./rrpl_parser.js"></script>)
var parser = require ( './rrpl_parser.js' ) ;
//obtain an abstract syntax tree
var ast = parser . parse ( "(48|37)-(25678|27)-(37|15)" ) ;
//returns line segments (normalized 0.0-1.0) that can be used to render the character
var lines = parser . toLines ( parser . toRects ( ast ) ) ; Les données RRPL peuvent être stockées dans un fichier JSON, que l'objet racine mappant les caractères Unicode à leur description respective, par exemple
{
"一" : "48" ,
"丁" : "468|26|27" ,
"上" : "246|248" ,
"不" : "(48-45678-48)|(3-26-1)" ,
"丕" : "不|一" ,
"中" : "(46-2468-68)|(24-2468-28)" ,
"串" : "中|中"
} Les références de ces fichiers sont généralement élargies avant la tentative de rendu. Cela peut être fait de deux manières. Le premier utilise parser.preprocess(json_object) dans rrpl_parser.js , tandis que le second utilise compile.js . Plus de documentation peut être trouvée dans les commentaires de ces fichiers.
Les fichiers JSON peuvent être compressés (et non compressés à partir d'un fichier binaire autour de la moitié de la taille de l'original à l'aide compress.js , en utilisant un demi-octet pour coder chaque symbole dans l'alphabet RRPL.
preview.html contenant un rendu de tous les caractères dans un fichier RRPL JSON: $node render.js preview path/to/input.json
realtime.html où les entrées utilisateur peuvent être analysées et rendues de manière interactive: (les caractères définis dans le fichier d'entrée seront disponibles pour référence) $node render.js realtime path/to/input.json
$node export_glyphs.js path/to/input.json path/to/output/folder 0
Contrairement à ce que génère render.js , ces SVG contiennent des «contours» des glyphes au lieu de coups simples. Plus de paramètres tels que l'épaisseur peuvent être modifiés dans le code source d' export_glyphs.js ; L'API de ligne de commande viendra plus tard.
pip install fontforge ) Un exemple peut être trouvé dans tools/forge_font.py . Étant donné que RRPL réduit tous les caractères chinois à une courte série de nombres, leur structure peut être apprise par des modèles séquentiels tels que les chaînes de Markov, les RNN et les LSTS sans beaucoup de difficulté. J'ai appliqué RNN (réseaux de neurones récurrents) à la langue pour halluciner des caractères chinois inexistants. Vous trouverez ci-dessous quelques caractères générés par la formation pendant la nuit sur ~ 1000 descriptions de caractères RRPL, avec les visuels rendus à l'aide d'un modèle PIX2PIX. Un référentiel séparé pour ce projet sera bientôt créé.

rrpl.json contient la dernière version de travail en cours. Il y a quelque 5 000 personnages là-dedans, mais il existe plus de 50 000 caractères chinois! L'aide est donc très appréciée. Si vous souhaitez vous aider avec ce projet, veuillez ajouter de nouveaux caractères dans le fichier et soumettre une demande de traction. Pour plus d'informations, contactez-moi en envoyant un e-mail à Lingdonh [at] Andrew [dot] CMU [dot] edu.
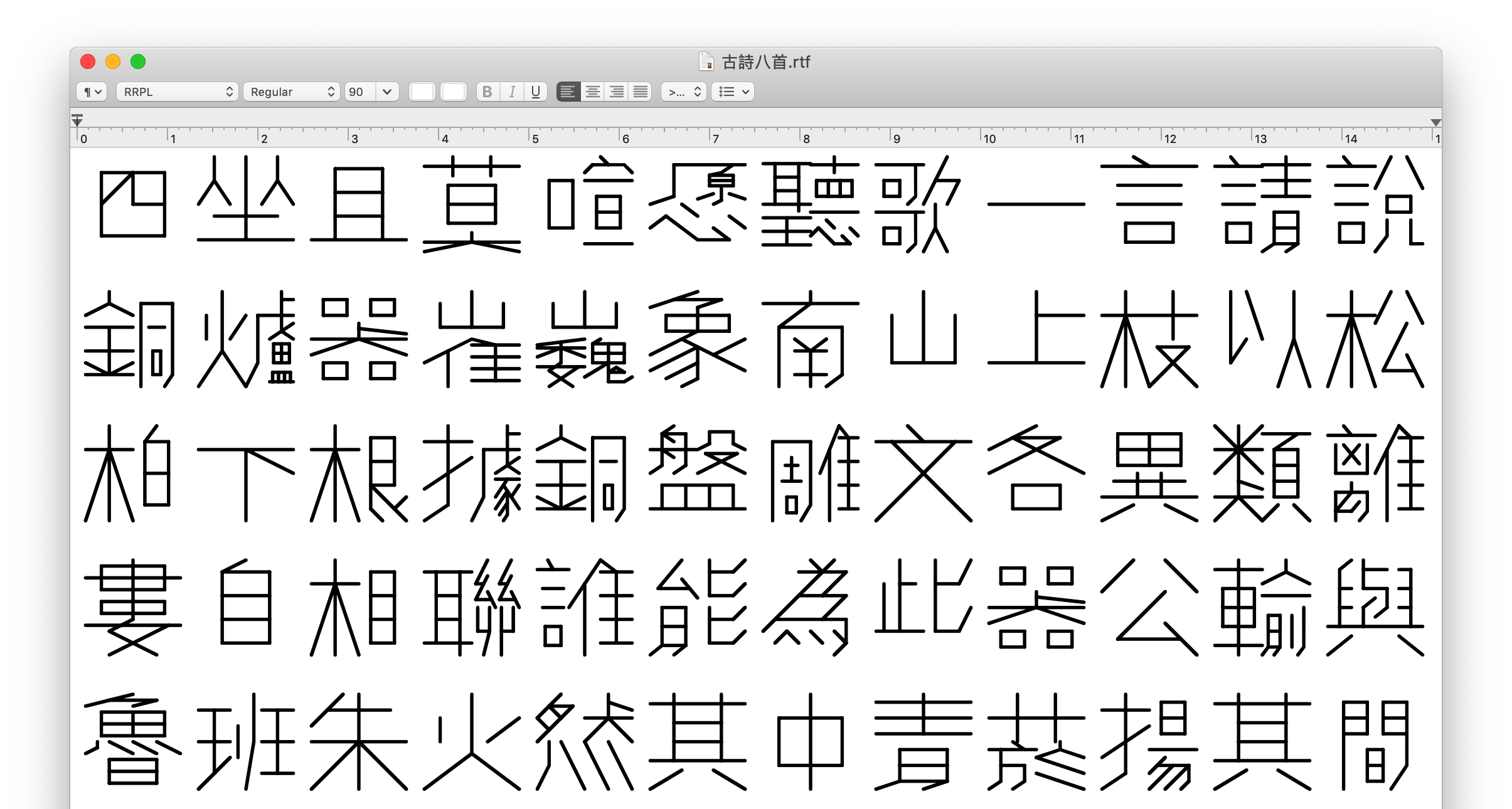
Vous trouverez ci-dessous un rendu des 5000+ caractères chinois désignés à l'aide de RRPL jusqu'à présent. Cliquez sur l'image pour agrandir.



