fonttable
1.0.0

Imprimez chaque caractère Unicode; Voir tous les glyphes possibles dans votre terminal
¹ Eh bien ... pas tout à fait tous les personnages. Nous ne voulons pas de codes de contrôle et autres, donc les caractères des catégories C , M et Z ne seront pas imprimés. (Voir le tableau des valeurs de catégorie générale à la fin du script.)
Si vous n'avez pas /usr/share/unicode/UnicodeData.txt sur votre système, une version mise en cache dans ce script sera automatiquement utilisée. (v14.0.0, courant en septembre 2021 de Unicode.org).
Alors que FontTable envoie tous les caractères Unicode imprimables à STDOUT, les caractères sont réellement affichés dépend des polices que vous avez installées sur votre système et si votre terminal est configuré pour les utiliser.
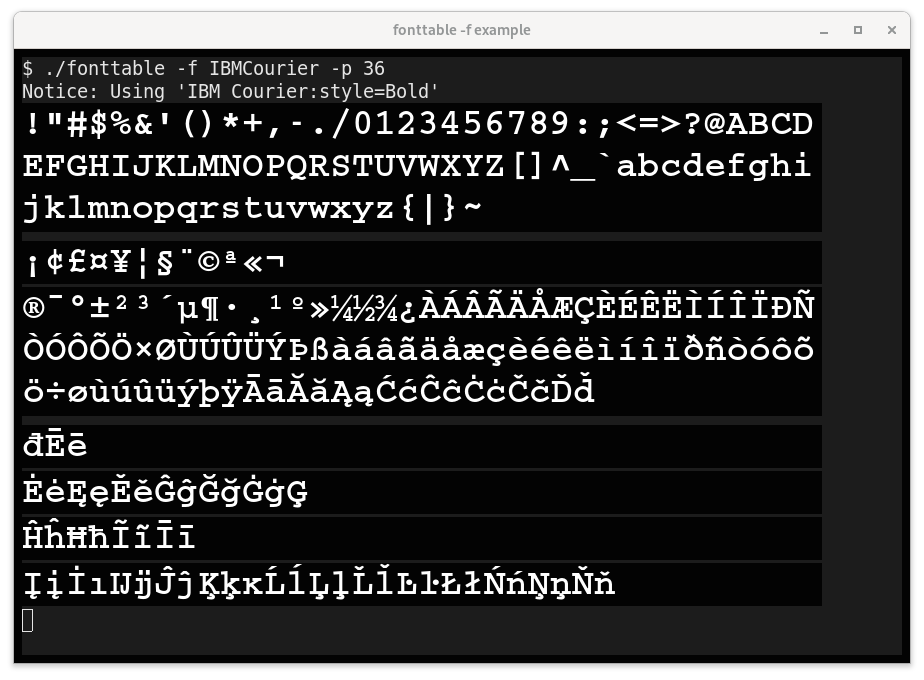
Facultativement, on peut spécifier une police particulière à l'aide de Fontname -f pour restreindre l'affichage aux glyphes définis dans cette police. (Nécessite des graphiques FontConfig et Sixel.)
Remarque: Le fichier "Unicodedata.txt" du consortium Unicode ne répertorie pas les caractères CJK, mais ils peuvent être trouvés dans la base de données Unihan adjacente. Si vous souhaitez les voir également, spécifiez "-s"
C'est un script shell. Téléchargez simplement fonttable et exécutez-le.
Cela a été inspiré par la ligne préférée 8 bits de nombreux jeunes:
;: suivant: exécuter")
FORT=0TO255:?CHR$(T);:NEXT:RUN
C'est l'équivalent moderne, un moyen de voir tous les glyphes valides. Bien sûr, nous ne pouvons pas utiliser une boucle simple car Unicode a un énorme espace d'adressage et seule une petite fraction des points de code est des caractères valides. La solution consiste uniquement à imprimer des caractères spécifiés dans le fichier unicodedata.txt.
De même, tous les points de code CJK dans la plage d'idéographie unifiée allouée ne sont pas un caractère. Fonttable imprime uniquement les caractères que la base de données Unihan existe existe. (Unihan_DictionaryIndices.txt).
À partir de Unicode 14 (2021), je compte près de 32 000 caractères imprimables dans Unicodedata.txt. De plus, il y a plus de 70 000 caractères CJK connus dans la base de données Unihan.
$ ./fonttable -s | awk '{print length($1)}'
31959
70805
(Certaines personnes réclament des nombres beaucoup plus élevés car ils utilisent PropList.txt et comptent les régions allouées , que les caractères existent ou non à ces points de code.)
fonttable: Show every Unicode character in your terminal.
Usage: fonttable [ -csu ] [ START..END ] [ -f FONT [ -p POINTSIZE ]]
START..END
Show range from START to END, inclusive. (Hexadecimal).
START defaults to 0, END defaults to infinity.
Multiple ranges are allowed: fonttable 2590..f 1fb00..ff
-f FONT | --font-name FONT
Display every Unicode glyph which is defined in FONT as
a sixel image directly in the terminal.
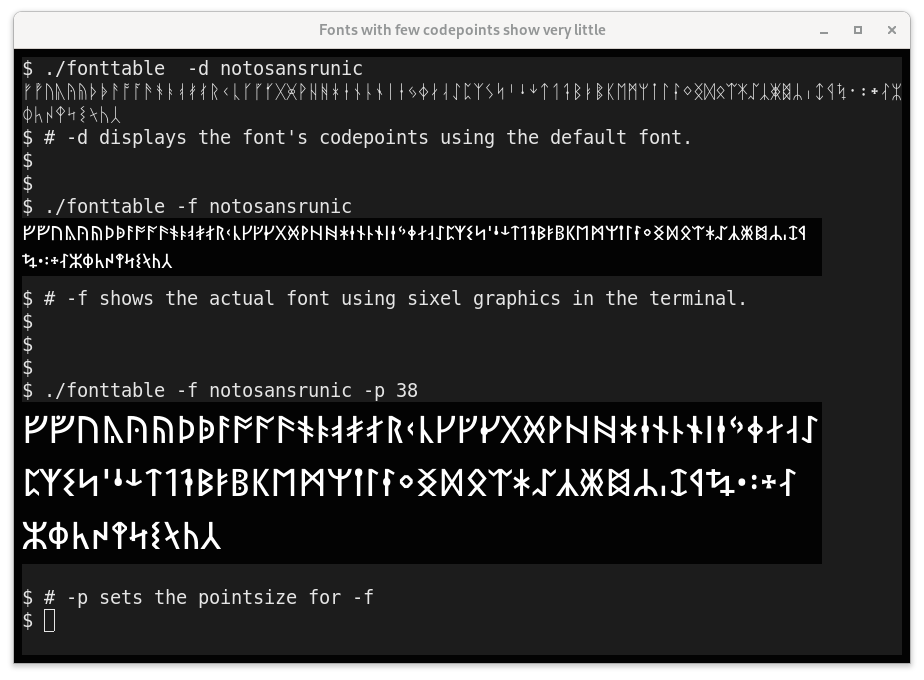
-p POINTSIZE | --point-size POINTSIZE
Change the size of the font rendered by -f.
-d FONT | --defined-in FONT
Like -f, but displays using the default terminal font,
not graphics. Useful to quickly see character coverage.
-c | --cache
Use cached UnicodeData.txt embedded in this script.
Usually the cached version is only used if the file is
not in /usr/share/unicode/ or the current directory.
-s | --show-unihan
Also show CJK data from the Unihan database.
The default is to not show characters that Unicode has
designated as mappings to other standards.
-u | --unihan-cache
Use a cached copy of the list of valid CJK characters
instead of looking for Unihan_DictionaryIndices.txt.
UnicodeData.txt contains around 30,000 characters.
Unihan adds another 70,000.
L'option -f / --font-name est comme l'option de plage, mais elle affiche uniquement les points de code qui sont définis dans une police spécifique (et qui sont marqués comme des caractères imprimables normaux dans Unicode). Par exemple:
fonttable -f NotoSans
Les polices peuvent être spécifiées par nom de fichier:
fonttable -f /usr/share/fonts/X11/misc/neep-iso10646-1-10x20.pcf.gz
FontTable utilise des graphiques Sixel pour dessiner la police demandée. Utilisez l'option -d FONT si vous souhaitez utiliser une police spécifique pour limiter les points de code affichés, mais les affichez toujours dans la police par défaut.
Bogue: Actuellement, la manipulation du Sixel est assez naïve. Le terminal n'est pas interrogé s'il prend en charge les graphiques Sixels, ni le nombre de pixels de chaque caractère, ni les couleurs de texte appropriées.
Votre machine doit avoir FontConfig, ce qui sera vrai pour Debian GNU / Linux et les dérivés, mais peut ne pas être vrai universellement. De plus, le nom de Fontname doit dans un format que FontConfig aime. Par exemple:
fonttable -f LTCCaslon # Works
fonttable -f "LTC Caslon" # Works
fonttable -f "LTC Caslon Swash Long Regular" # Works
Mais, comme cela se produit:
fonttable -f Caslon # Does Not Work
fonttable -f "LTC Caslon Swash Long" # Does Not Work
Si vous n'êtes pas sûr du nom, essayez fc-list | grep -i caslon . Vous pouvez également spécifier directement un nom de fichier de police. Par exemple:
fonttable ~/.local/share/fonts/P22CezannePro.ttf
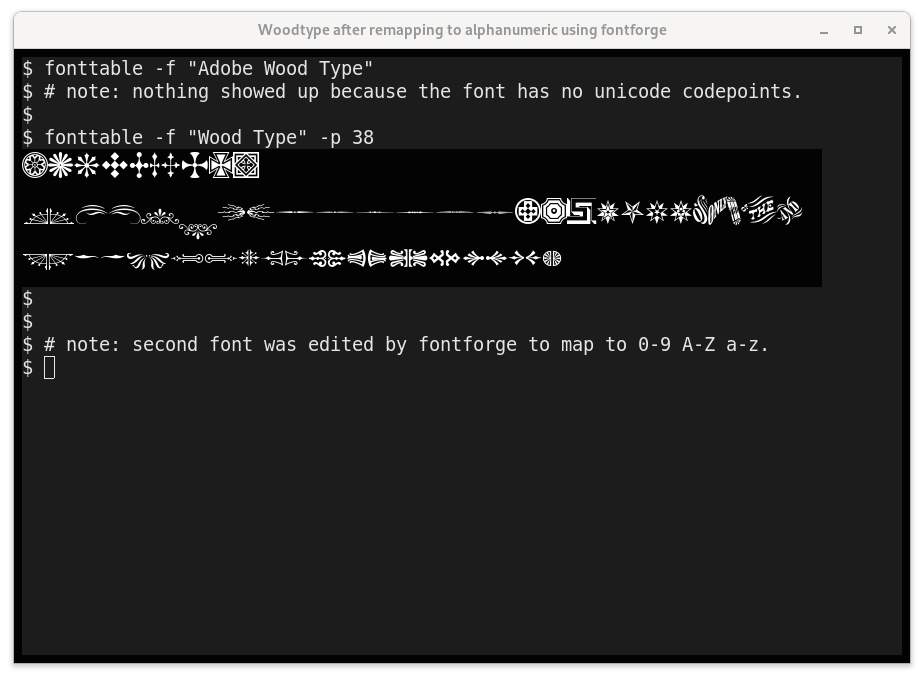
Certaines polices décoratives et expertes définissent les glyphes qui n'ont pas de mappages pour les points de code Unicode ou cette carte à une utilisation privée. Ces personnages ne seront pas trouvés par ce script. Par exemple:
fonttable -f AdobeWoodType # Shows no glyphs!
Cependant, avec un certain effort, on peut déplacer ces glyphes vers des points de code Unicode à l'aide d'un programme tel que FontForge.
Différents programmes de terminaux et polices vous donneront des résultats radicalement différents.
XXX TODO
Cette section doit être refaite car les terminaux testés sont désormais assez anciens.
GNOME-terminal-3.38.3 utilise plusieurs polices à l'aide de Freetype. Pour certains caractères, tels que ⑫ (numéro de douze encerclé), les glyphes sont trop larges pour la cellule de caractère et se chevauchent mal. Il ne semble pas y avoir de cadre pour dire au gnome-terminal de rétrécir ou de tronquer des glyphes trop larges.

GNOME Terminal a très peu de préférences réglables par les utilisateurs, mais vous pouvez définir des caractères "largeur ambigus" pour être larges (deux cellules) au lieu d'être étroites. Cela aide un peu, au moins sur ce test de torture.

Cependant, la définition de la largeur ambiguë à large n'est pas une panacée. Par exemple, si le glyphe est remplacé par une police d'un rapport d'aspect très différent de votre défaut. Par exemple, voici ce qui se passe lorsque la police "Terminal DEC" est choisie (qui est deux fois plus élevée que large):

Notez qu'avec cette police par défaut, les glyphes se chevauchent même si la largeur ambiguë est définie sur large.
Comme le gnome-terminal, XTerm utilise également plusieurs polices lorsqu'une police antialiasée (vectorielle) est sélectionnée ( -fa Inconsolata -fs 18 ), remplissant d'autres polices système si la police sélectionnée est trop limitée. XTerm peut également fonctionner avec des polices Bitmaps, mais elles sont un peu plus difficiles.
XTerm n'utilisera qu'une seule police si vous spécifiez une police bitmap en utilisant -fn . Cela signifie que vous devrez trouver une police qui couvre chaque section d'Unicode que vous utilisez. Ce n'est pas toujours facile.
La police xterm par défaut, appelée "fixe", semble un choix terrible car il a très peu de caractères Unicode. Cependant, c'est parce que XTerm utilise la version latine-1 par défaut. Il existe une version Unicode (10646) de "fixe" qui n'est pas mal en termes de couverture. "Correct" est également disponible dans une version large pour les caractères asiatiques, qui détecte et utilise automatiquement automatiquement. Donc, pas un mauvais choix, et il est préinstallé.
xterm -fn '*fixed-medium-r-normal--20*10646*'

Xterm remplit déjà les glyphes manquants pour vous en utilisant d'autres polices lorsque vous spécifiez une police antialiasée en utilisant -fa . (Utilisez -fs pour spécifier la taille du point). Remarque: Antialiased est la façon dont Xterm fait référence aux polices vectorielles comme TrueType, OpenType et Type 1.
Alors que Xterm et GNOME-terminal utilisent les deux Freetype pour rendre les polices antialiasées, contrairement à GNOME-terminal, Xterm applique les limites des cellules de caractère et ne laisse pas les glyphes se chevaucher. Au lieu de cela, les glyphes trop larges sont tronqués. Que cela soit meilleur ou non, c'est une question de goût.

Notez que xterm par défaut utilise la couleur de police spécifiée par l'utilisateur plutôt que les couleurs intégrées à une police. Encore une fois, c'est une question de goût, mais il convient de noter que la plupart des polices à emoji de nos jours ne sont conçues que de couleur, donc des polices de couleur unique pour certaines gammes peuvent être obsolètes ou manquer des glyphes.
Si vous souhaitez voir quelles polices sont chargées lorsque vous exécutez FontTable, définissez la variable d'environnement XFT_DEBUG sur 3 avant d'exécuter XTerm.
XFT_DEBUG=3 xterm -fa DroidSansMono -fs 24
Si vous souhaitez forcer XTerm à utiliser uniquement les polices que vous avez demandées, vous pouvez le faire en définissant la ressource limitFontsets x sur 0.
xterm -fa DroidSansMono -xrm "XTerm*vt100.limitFontsets: 0"
Notez que XTerm tentera de détecter automatiquement si votre police est également disponible dans une version en double (pour CJK). S'il ne le trouve pas, vous pouvez spécifier une police "DoubleSize" séparée à l'aide -fd .
xterm -fs 24 -fa DroidSansMono -fd DroidSansFallback -xrm "XTerm*vt100.limitFontsets: 0"
Notez que si vous n'avez pas d'installation de police particulière, même si vous utilisez LimitFonTetsSets: 0, vous serez affiché une police de substitut. Encore une fois, vous pouvez utiliser xft_debug pour savoir ce qui se passe.
XFT_DEBUG=3 xterm -fs 24 -fa DroidSansMono -fd DroidSansFallback -xrm "XTerm*vt100.limitFontsets: 0"


