SSD
More modular!
Ce référentiel implémente SSD (détecteur multibox à tir unique). La mise en œuvre est fortement influencée par les projets ssd.pytorch, pytorch-ssd et maskrcnn-benchmark. Ce référentiel vise à être la base de code pour les recherches basées sur SSD.

Exemple de sortie SSD (VGG_SSD300_VOC0712).
| Pertes | Taux d'apprentissage | Métrique |
|---|---|---|
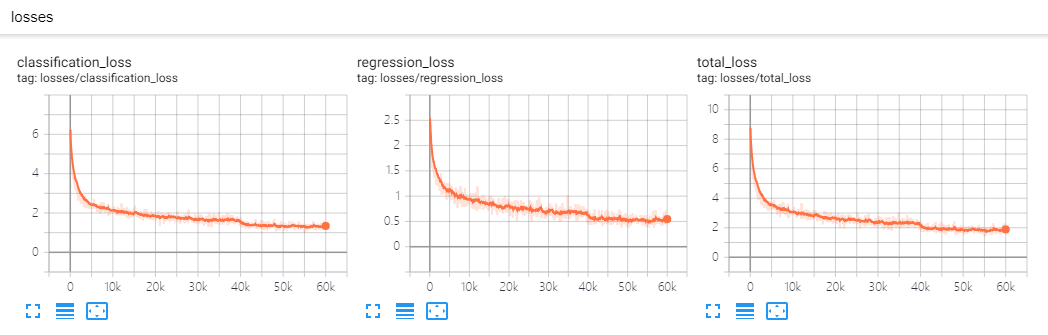 | 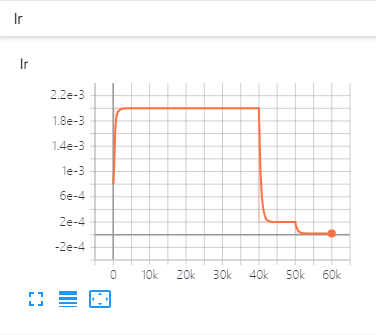 | 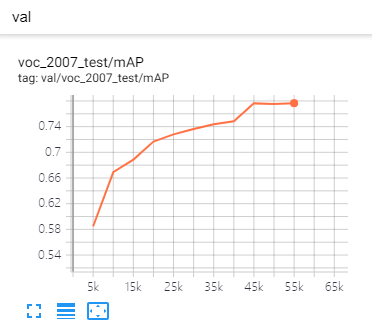 |
DistributedDataParallel , vous pouvez vous entraîner ou tester avec des GPU arbitraires, le schéma de formation changera en conséquence.backbone , Detector , BoxHead , BoxPredictor , etc. Vous pouvez remplacer chaque composant par votre propre code sans modifier la base de code. Par exemple, vous pouvez ajouter EfficientNet en tant qu'épine dorsale, ajouter simplement efficient_net.py (déjà ajouté) et l'enregistrer, spécifique dans le fichier de configuration, c'est fait!CMD de formation.eval_step pour vérifier les performances s'améliorant ou non.git clone https://github.com/lufficc/SSD.git
cd SSD
# Required packages: torch torchvision yacs tqdm opencv-python vizer
pip install -r requirements.txt
# Done! That's ALL! No BUILD! No bothering SETUP!
# It's recommended to install the latest release of torch and torchvision. Pour l'ensemble de données PASCAL VOC, faites la structure du dossier comme ceci:
VOC_ROOT
|__ VOC2007
|_ JPEGImages
|_ Annotations
|_ ImageSets
|_ SegmentationClass
|__ VOC2012
|_ JPEGImages
|_ Annotations
|_ ImageSets
|_ SegmentationClass
|__ ...
Lorsque VOC_ROOT par défaut est un dossier datasets dans le projet actuel, vous pouvez créer des liens symboliques sur datasets ou export VOC_ROOT="/path/to/voc_root" .
Pour l'ensemble de données CoCo, faites la structure du dossier comme ceci:
COCO_ROOT
|__ annotations
|_ instances_valminusminival2014.json
|_ instances_minival2014.json
|_ instances_train2014.json
|_ instances_val2014.json
|_ ...
|__ train2014
|_ <im-1-name>.jpg
|_ ...
|_ <im-N-name>.jpg
|__ val2014
|_ <im-1-name>.jpg
|_ ...
|_ <im-N-name>.jpg
|__ ...
Lorsque COCO_ROOT par défaut est un dossier datasets dans le projet actuel, vous pouvez créer des liens symboliques sur datasets ou export COCO_ROOT="/path/to/coco_root" .
# for example, train SSD300:
python train.py --config-file configs/vgg_ssd300_voc0712.yaml # for example, train SSD300 with 4 GPUs:
export NGPUS=4
python -m torch.distributed.launch --nproc_per_node= $NGPUS train.py --config-file configs/vgg_ssd300_voc0712.yaml SOLVER.WARMUP_FACTOR 0.03333 SOLVER.WARMUP_ITERS 1000Les fichiers de configuration que je fournis supposent que nous exécutons sur un seul GPU. Lors du changement de nombre de GPU, l'hyper-paramètre (LR, Max_iter, ...) changera également selon cet article: SGD à minibatch précis et précis: formation d'imageNet en 1 heure.
# for example, evaluate SSD300:
python test.py --config-file configs/vgg_ssd300_voc0712.yaml # for example, evaluate SSD300 with 4 GPUs:
export NGPUS=4
python -m torch.distributed.launch --nproc_per_node= $NGPUS test.py --config-file configs/vgg_ssd300_voc0712.yamlPrédire l'image dans un dossier est simple:
python demo.py --config-file configs/vgg_ssd300_voc0712.yaml --images_dir demo --ckpt https://github.com/lufficc/SSD/releases/download/1.2/vgg_ssd300_voc0712.pth Ensuite, il téléchargera et mettra en cache vgg_ssd300_voc0712.pth automatiquement et prédit les images avec des boîtes, des scores et des noms d'étiquette enregistrés dans le dossier demo/result par défaut.
Vous verrez une sortie similaire:
(0001/0005) 004101.jpg: objects 01 | load 010ms | inference 033ms | FPS 31
(0002/0005) 003123.jpg: objects 05 | load 009ms | inference 019ms | FPS 53
(0003/0005) 000342.jpg: objects 02 | load 009ms | inference 019ms | FPS 51
(0004/0005) 008591.jpg: objects 02 | load 008ms | inference 020ms | FPS 50
(0005/0005) 000542.jpg: objects 01 | load 011ms | inference 019ms | FPS 53
| Test VOC2007 | COCO TEST-DEV2015 | |
|---|---|---|
| SSD300 * | 77.2 | 25.1 |
| SSD512 * | 79.8 | 28.8 |
| Colonne vertébrale | Taille d'entrée | Box AP | Taille du modèle | Télécharger |
|---|---|---|---|---|
| VGG16 | 300 | 25.2 | 262 Mo | modèle |
| VGG16 | 512 | 29.0 | 275 Mo | modèle |
| Colonne vertébrale | Taille d'entrée | carte | Taille du modèle | Télécharger |
|---|---|---|---|---|
| VGG16 | 300 | 77.7 | 201 Mo | modèle |
| VGG16 | 512 | 80.7 | 207 Mo | modèle |
| Mobilenet v2 | 320 | 68.9 | 25,5 Mo | modèle |
| Mobilenet v3 | 320 | 69.5 | 29,9 Mo | modèle |
| EfficientNet-B3 | 300 | 73.9 | 97.1 Mo | modèle |
Si vous souhaitez ajouter vos composants personnalisés, veuillez consulter Develop_Guide.md pour plus de détails.
Si vous avez des problèmes en cours d'exécution ou en compilant ce code, nous avons compilé une liste de problèmes communs dans le dépannage.md. Si votre problème n'y est pas présent, n'hésitez pas à ouvrir un nouveau problème.
Si vous utilisez ce projet dans votre recherche, veuillez citer ce projet.
@misc{lufficc2018ssd,
author = {Congcong Li},
title = {{High quality, fast, modular reference implementation of SSD in PyTorch}},
year = {2018},
howpublished = {url{https://github.com/lufficc/SSD}}
}


