CLUEDatasetSearch
1.0.0
Ensemble de données NLP chinois et anglais. Vous pouvez cliquer pour rechercher.
Vous pouvez contribuer votre alimentation en téléchargeant des informations sur l'ensemble de données. Après avoir téléchargé cinq ensembles de données ou plus et les avoir examinés, l'étudiant peut être utilisé comme contributeur de projet et les afficher.
Clueai Toolkit: Trois minutes et trois lignes de code pour terminer le développement de la PNL (zéro exemple d'apprentissage)
S'il y a un problème avec l'ensemble de données, veuillez soumettre un problème.
Tous les ensembles de données proviennent d'Internet et ne sont organisés que pour une extraction facile. S'il y a une contrefaçon ou d'autres problèmes, veuillez nous contacter à temps pour les supprimer.
| IDENTIFIANT | titre | Date de mise à jour | Fournisseur d'ensemble de données | licence | illustrer | Mots clés | catégorie | Adresse papier | Remarque |
|---|---|---|---|---|---|---|---|---|---|
| 1 | CCKS2017 Chinois Electronic Case Naming Entity Identification | Mai 2017 | Beijing Jimuyun Health Technology Co., Ltd. | Les données proviennent des données réelles des enregistrements médicaux électroniques de la plate-forme de l'hôpital Cloud, avec un total de 800 éléments (enregistrement de visite unique d'un patient) et ont été traités par désensibilisation. | Dossier médical électronique | Reconnaissance d'entité nommée | Chinois | ||
| 2 | CCKS2018 Chinois Electronic Case Naming Entity Identification | 2018 | Yidu Cloud (Beijing) Technology Co., Ltd. | La tâche d'évaluation de la reconnaissance électronique des entités de dénomination des enregistrements médicaux de CCKS2018 fournit 600 textes de dossiers médicaux électroniques marqués, ce qui nécessite un total de cinq entités, notamment des pièces anatomiques, des symptômes indépendants, des descriptions de symptômes, une chirurgie et des médicaments. | Dossier médical électronique | Reconnaissance d'entité nommée | Chinois | ||
| 3 | MSRA Nommé des données d'identification des entités ensemble au Microsoft Asia Research Institute | MSRA | Les données proviennent de MSRA, le formulaire d'étiquetage est BIO, et il y a 46 365 entrées au total | MSRA | Reconnaissance d'entité nommée | Chinois | |||
| 4 | Ensemble d'annotation d'identification de l'identification du Corpus quotidien 1998. | Janvier 1998 | Les gens de tous les jours | La source de données est quotidienne des gens en 1998, et le formulaire d'étiquetage est BIO, avec un total de 23 061 entrées. | 98 personnes quotidiennes | Reconnaissance d'entité nommée | Chinois | ||
| 5 | Boson | Données | La source de données est boson, le formulaire d'étiquetage est BMEO, et il y a 2 000 entrées au total | Boson | Reconnaissance d'entité nommée | Chinois | |||
| 6 | Indice de grain fin | 2020 | INDICE | L'ensemble de données Cluener2020 est basé sur l'ensemble de données de classification de texte Thuctc de l'Université Tsinghua, qui sélectionne certaines données pour l'annotation d'entité de dénomination à grain fin. Les données originales proviennent de SINA News RSS. Les données contiennent 10 catégories d'étiquettes, l'ensemble de formation a un total de 10 748 corpus, et l'ensemble de vérification a un total de 1 343 corpus. | À grain fin; Cucule | Reconnaissance d'entité nommée | Chinois | ||
| 7 | Conll-2003 | 2003 | CNTS - Groupe de technologies linguistiques | Les données proviennent de la tâche CONLL-2003, qui annote quatre catégories, notamment PER, LOC, ORG et MISC | Conll-2003 | Reconnaissance d'entité nommée | papier | Anglais | |
| 8 | Reconnaissance de l'entité de Weibo | 2015 | https://github.com/hltcoe/golden-horse | EMNLP-2015 | Reconnaissance d'entité nommée | ||||
| 9 | Sighan Bakeoff 2005 | 2005 | MSR / PKU | Bakeoff-2005 | Reconnaissance d'entité nommée |
| IDENTIFIANT | titre | Date de mise à jour | Fournisseur d'ensemble de données | licence | illustrer | Mots clés | catégorie | Adresse papier | Remarque |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Newsqa | 2019/9/13 | Institut de recherche Microsoft | Le but de l'ensemble de données de Maluuba Newsqa est d'aider les communautés à la recherche à construire des algorithmes qui peuvent répondre aux questions qui nécessitent des compétences de compréhension et de raisonnement au niveau de l'homme. Il contient plus de 12 000 articles de presse et 120 000 réponses, avec une moyenne de 616 mots par article et 2 à 3 réponses par question. | Anglais | QA | papier | ||
| 2 | Équipe | Stanford | L'ensemble de données de questions et réponses de Stanford (Squad) est un ensemble de données de compréhension en lecture composé de questions soulevées sur un ensemble d'articles sur Wikipedia, où la réponse à chaque question est un paragraphe de texte, qui peut provenir du paragraphe de lecture correspondant, ou la question peut être sans réponse. | Anglais | QA | papier | |||
| 3 | Simples | Système de questions et réponses simples à grande échelle basés sur les réseaux de stockage, l'ensemble de données fournit un ensemble de données de questions et réponses multi-tâches avec des réponses de 100k à des questions simples. | Anglais | QA | papier | ||||
| 4 | Wikiqa | 2016/7/14 | Institut de recherche Microsoft | Afin de refléter les besoins d'informations réelles des utilisateurs ordinaires, Wikiqa utilise les journaux de requête Bing comme source du problème. Chaque question est liée à une page Wikipedia qui peut avoir des réponses. Étant donné que la section récapitulative de la page Wikipedia fournit des informations de base et souvent les plus importantes sur ce sujet, les phrases de cette section sont utilisées comme réponses candidates. Avec l'aide du crowdsourcing, l'ensemble de données comprend 3047 questions et 29258 phrases, dont 1473 phrases sont marquées comme des phrases de réponse pour la question correspondante. | Anglais | QA | papier | ||
| 5 | CMEDQA | 2019/2/25 | Zhang Sheng | Les données du Forum médical en ligne contient 54 000 questions et les réponses environ 100 000 réponses. | Chinois | QA | papier | ||
| 6 | cmedqa2 | 2019/1/9 | Zhang Sheng | La version étendue de CMEDQA contient environ 100 000 questions médicales et correspondant à environ 200 000 réponses. | Chinois | QA | papier | ||
| 7 | webmedqa | 2019/3/10 | Il Junqing | Un ensemble de données de questions et réponses médicales contenant 60 000 questions et 310 000 réponses, et contient les catégories de questions. | Chinois | QA | papier | ||
| 8 | Xqa | 2019/7/29 | Université Tsinghua | Cet article construit principalement un ensemble de données de questions et réponses ouvertes inter-langues pour une question et une réponse ouvertes. L'ensemble de données (ensemble de formation, ensemble de tests) comprend principalement neuf langues et plus de 90 000 questions et réponses. | Multilingue | QA | papier | ||
| 9 | Amazonqa | 2019/9/29 | Amazone | L'Université Carnegie Mellon a proposé une tâche de modèle d'AQ basée sur des commentaires en réponse aux points de douleur des réponses répétées aux questions sur la plate-forme Amazon, c'est-à-dire en utilisant les questions et réponses précédentes pour répondre à un certain produit, le système QA résumera automatiquement une réponse aux clients. | Anglais | QA | papier | ||
| 9 | Amazonqa | 2019/9/29 | Amazone | L'Université Carnegie Mellon a proposé une tâche de modèle d'AQ basée sur des commentaires en réponse aux points de douleur des réponses répétées aux questions sur la plate-forme Amazon, c'est-à-dire en utilisant les questions et réponses précédentes pour répondre à un certain produit, le système QA résumera automatiquement une réponse aux clients. | Anglais | QA | papier |
| IDENTIFIANT | titre | Date de mise à jour | Fournisseur d'ensemble de données | licence | illustrer | Mots clés | catégorie | Adresse papier | Remarque |
|---|---|---|---|---|---|---|---|---|---|
| 1 | NLPCC2013 | 2013 | Ccf | Weibo Corpus, marqué de 7 émotions: comme, le dégoût, le bonheur, la tristesse, la colère, la surprise, la peur. Taille: 14 000 postes de Weibo, 45 431 phrases | NLPCC2013, émotion | Analyse des sentiments | papier | ||
| 2 | NLPCC2014 Tâche1 | 2014 | Ccf | Weibo Corpus, marqué de 7 émotions: comme, le dégoût, le bonheur, la tristesse, la colère, la surprise, la peur. Taille: 20 000 postes de Weibo | NLPCC2014, émotion | Analyse des sentiments | |||
| 3 | NLPCC2014 Tâche2 | 2014 | Ccf | Corpus Weibo marqué avec un positif et négatif | NLPCC2014, Sentiment | Analyse des sentiments | |||
| 4 | Weibo Emotion Corpus | 2016 | Université polytechnique de Hong Kong | Weibo Corpus, marqué de 7 émotions: comme, le dégoût, le bonheur, la tristesse, la colère, la surprise, la peur. Taille: plus de 40 000 postes de Weibo | Weibo Emotion Corpus | Analyse des sentiments | Construction du corpus d'émotion basée sur la sélection des étiquettes naturelles bruyantes | ||
| 5 | [Rencps] (Fuji Ren peut être contacté ([email protected]) pour un accord de licence.) | 2009 | Fuji Ren | Le corpus de blog annoté a marqué l'émotion et le sentiment au niveau du document, au niveau des paragraphes et au niveau de la phrase. Il contient 1500 blogs, 11 000 paragraphes et 35000 phrases. | Rencps, émotion, sentiment | Analyse des sentiments | Construction d'un blog Emotion Corpus for Chinese Emotional Expression Analysis | ||
| 6 | weibo_senti_100k | Inconnu | Inconnu | Marquez le Sina Weibo avec émotion, et il y a environ 50 000 commentaires positifs et négatifs chacun | Weibo Senti, Sentiment | Analyse des sentiments | |||
| 7 | BDCI2018-AUTOMOBILE L'industrie des utilisateurs et la reconnaissance émotionnelle | 2018 | Ccf | Les commentaires sur les voitures du Forum automobile marquent les thèmes de la poésie de la voiture: puissance, prix, intérieur, configuration, sécurité, apparence, manipulation, consommation de carburant, espace et confort. Chaque sujet est marqué d'étiquettes émotionnelles et les émotions sont divisées en 3 catégories, les nombres 0, 1 et -1 représentant respectivement neutre, positif et négatif. | Attributs Analyse des sentiments Analyse des sentiments du thème | Analyse des sentiments | |||
| 8 | AI Challenger les commentaires des utilisateurs à grain fin Analyse du sentiment | 2O18 | Meituan | Revues de restauration, 6 attributs de premier niveau, 20 attributs de deuxième niveau, chaque attribut est marqué positif, négatif, neutre et non mentionné. | Analyse des sentiments d'attribut | Analyse des sentiments | |||
| 9 | BDCI2019 Information financière négative et détermination du sujet | 2019 | Banque centrale | Financial Field News, chaque exemple étiquette la liste des entités ainsi que la liste des entités négatives. La tâche consiste à déterminer si un échantillon est négatif et l'entité négative correspondante. | Analyse du sentiment des entités | Analyse des sentiments | |||
| 10 | Coupe de la Zhijiang Cup Revue et concours de fouille d'opinion | 2019 | Laboratoire de zhijiang | La tâche d'explorer les opinions des avis de marque est d'extraire les caractéristiques des attributs de produits et les opinions des consommateurs à partir des revues de produits, et de confirmer leur polarité émotionnelle et leurs types d'attributs. Pour une certaine caractéristique d'attribut d'un produit, il existe une série de mots d'opinion qui le décrivent, qui représentent les vues des consommateurs sur la fonction d'attribut. Chaque ensemble de {caractéristiques d'attribut de produit, opinion du consommateur} a une polarité émotionnelle correspondante (négative, neutre, positif), représentant la satisfaction du consommateur à l'égard de cet attribut. De plus, plusieurs fonctionnalités d'attribut peuvent être classées en un certain type d'attribut, telles que l'apparence, la boîte et d'autres fonctionnalités d'attribut peuvent être classées dans le type d'attribut de packaging. Les équipes participantes soumettront éventuellement les informations de prédiction extraites des données de test, y compris quatre champs: mot caractéristique d'attribut, mot d'opinion, polarité d'opinion et type d'attribut. | Analyse des sentiments d'attribut | Analyse des sentiments | |||
| 11 | Concours d'algorithme du campus SOHU 2019 | 2019 | Sohu | Compte tenu de plusieurs articles, l'objectif est de juger de l'entité centrale de l'article et de son attitude émotionnelle envers l'entité centrale. Chaque article identifie jusqu'à trois entités principales et détermine les tendances émotionnelles de l'article vers les principales entités ci-dessus (positive, neutre et négative). Entité: les personnes, les objets, les régions, les institutions, les groupes, les entreprises, les industries, certains événements spécifiques, etc. sont fixes et peuvent être utilisées comme mot d'entité pour le sujet de l'article. Entité principale: le mot d'entité qui décrit ou agit principalement comme le rôle principal de l'article. | Analyse du sentiment des entités | Analyse des sentiments |
| IDENTIFIANT | titre | Date de mise à jour | Fournisseur d'ensemble de données | licence | illustrer | Mots clés | catégorie | Adresse papier | Remarque |
|---|---|---|---|---|---|---|---|---|---|
| 1 | [2018 "Daguan Cup" Text Intelligent Processing Challenge] (https://www.pkbigdata.com/common/cmpt/ "Daguan Cup" Text Intelligent Processing Challenge_shiti et data.html) | Juillet 2018 | Données optimistes | L'ensemble de données provient de données optimistes et est une longue tâche de classification de texte. Il comprend principalement quatre champs: id, article, word_seg et classe. Les données contient 19 catégories, totalisant 102 275 échantillons. | Texte long; désensibilisation | Classification de texte | Chinois | ||
| 2 | Catégorie des nouvelles chinoises (texte) d'aujourd'hui | Mai 2018 | Les titres d'aujourd'hui | L'ensemble de données provient de Toutiao aujourd'hui et est une courte tâche de classification de texte. Les données contient 15 catégories, totalisant 382 688 échantillons. | texte court; nouvelles | Classification de texte | Chinois | ||
| 3 | Thucnews Classification de texte chinois | 2016 | Université Tsinghua | Thucnews est généré sur la base du filtrage et du filtrage historiques des données du canal d'abonnement SINA News RSS entre 2005 et 2011, et se trouve dans le format de texte brut UTF-8. Sur la base du système original de classification des nouvelles SINA, nous avons réintégré et divisé 14 catégories de classification des candidats: finance, loterie, immobilier, stocks, maison, éducation, technologie, société, mode, affaires courantes, sports, panneaux de zodiaque, jeux et divertissement, avec un total de 740 000 documents de nouvelles (2,19 gb) | Documentation; Nouvelles | Classification de texte | Chinois | ||
| 4 | Classification de texte chinois de l'Université Fudan | Groupe de traitement du langage naturel, Département d'information informatique et de technologie, Université Fudan, Centre international de données internationales | L'ensemble de données est de l'Université Fudan et est une courte tâche de classification du texte. Les données contient 20 catégories, avec un total de 9 804 documents. | Documentation; Nouvelles | Classification de texte | Chinois | |||
| 5 | Titre des nouvelles Classification du texte court | Décembre 2019 | Chenfengshf | Partage de domaine public CC0 | L'ensemble de données est dérivé de la plate-forme Kesci et est une courte tâche de classification de texte pour le champ de titre d'information. La plupart du contenu est un titre de texte court (longueur <50), les données contiennent 15 catégories, un total de 38w échantillons | Texte court; titre d'actualités | Classification de texte | Chinois | |
| 6 | Challe d'apprentissage de la machine de la Coupe Zhihu Kanshan 2017 2017 | Juin 2017 | Société de l'intelligence artificielle chinoise; Zhihu | L'ensemble de données provient de Zhihu, qui est des données annotées pour la relation de liaison entre les balises de question et de sujet. Chaque question a 1 balises ou plus, avec un total de 1 999 étiquettes, contenant un total de 3 millions de questions. | Question; texte court | Classification de texte | Chinois | ||
| 7 | Coupe Zhijiang 2019 - Concours d'exploitation d'opinion d'examen du commerce électronique | Août 2019 | Laboratoire de zhijiang | La tâche d'explorer les opinions des avis de marque est d'extraire les caractéristiques des attributs de produits et les opinions des consommateurs à partir des revues de produits, et de confirmer leur polarité émotionnelle et leurs types d'attributs. Pour une certaine caractéristique d'attribut d'un produit, il existe une série de mots d'opinion qui le décrivent, qui représentent les vues des consommateurs sur la fonction d'attribut. Chaque groupe de {caractéristiques d'attribut de produit, opinion des consommateurs} a une polarité émotionnelle correspondante (négative, neutre, positif), qui représente le degré de satisfaction des consommateurs avec cet attribut. | Commentaires; texte court | Classification de texte | Chinois | ||
| 8 | Classification du texte long de Iflytek | iflytek | Cet ensemble de données comporte plus de 17 000 données de long texte étiquetées sur les descriptions d'applications de l'application, y compris divers sujets d'application liés à la vie quotidienne, avec un total de 119 catégories | Texte long | Classification de texte | Chinois | |||
| 9 | Données de classification des nouvelles sur l'ensemble du réseau (Sogouca) | 16 août 2012 | Sogou | Ces données proviennent des données d'actualités de 18 chaînes, notamment la domestique, l'international, les sports, le social, le divertissement, etc. de juin à juillet 2012 2012. | nouvelles | Classification de texte | Chinois | ||
| 10 | Données sur les nouvelles de Sohu (Sogoucs) | Août 2012 | Sogou | La source de données est Sohu News de 18 chaînes, notamment la nationale, l'international, les sports, le social, le divertissement, etc. de juin à juillet 2012. | nouvelles | Classification de texte | Chinois | ||
| 11 | Corpus de classification des nouvelles de l'Université des sciences et de la technologie | Novembre 2017 | Institut d'automatisation Liu Yu, Centre complet de l'Académie chinoise des sciences | Impossible de télécharger pour le moment, j'ai contacté l'auteur, en attendant des commentaires | nouvelles | ||||
| 12 | Chnseticorp_htl_all | Mars 2018 | https://github.com/sophonplus/chinesenlpcorpus | Plus de 7000 données sur les révisions d'hôtel, plus de 5000 avis positifs, plus de 2000 avis négatifs | |||||
| 13 | waimai_10k | Mars 2018 | https://github.com/sophonplus/chinesenlpcorpus | Les avis des utilisateurs collectés par une certaine plate-forme à retenir sont 4 000 positifs et environ 8 000 négatifs. | |||||
| 14 | en ligne_shopping_10_cats | Mars 2018 | https://github.com/sophonplus/chinesenlpcorpus | Il y a 10 catégories, avec un total de plus de 60 000 commentaires, et environ 30 000 commentaires positifs et négatifs, y compris les livres, les tablettes, les téléphones portables, les fruits, le shampooing, le chauffe-eau, le Mengniu, les vêtements, les ordinateurs, les hôtels | |||||
| 15 | weibo_senti_100k | Mars 2018 | https://github.com/sophonplus/chinesenlpcorpus | Plus de 100 000 pièces, marquées d'émotion sur Sina Weibo, et environ 50 000 commentaires positifs et négatifs sont chacun | |||||
| 16 | Simplifyweibo_4_moods | Mars 2018 | https://github.com/sophonplus/chinesenlpcorpus | Plus de 360 000 pièces, marquées d'émotions sur Sina Weibo, contient 4 types d'émotions, dont environ 200 000 morceaux de joie, environ 50 000 morceaux de colère, de dégoût et de dépression. | |||||
| 17 | dmsc_v2 | Mars 2018 | https://github.com/sophonplus/chinesenlpcorpus | 28 films, plus de 700 000 utilisateurs, plus de 2 millions de données de notation / commentaires | |||||
| 18 | yf_dianping | Mars 2018 | https://github.com/sophonplus/chinesenlpcorpus | 240 000 restaurants, 540 000 utilisateurs, 4,4 millions de commentaires / données de notation | |||||
| 19 | yf_amazon | Mars 2018 | https://github.com/sophonplus/chinesenlpcorpus | 520 000 articles, plus de 1 100 catégories, 1,42 million d'utilisateurs, 7,2 millions de commentaires / données de notation |
| IDENTIFIANT | titre | Date de mise à jour | Fournisseur d'ensemble de données | licence | illustrer | Mots clés | catégorie | Adresse papier | Remarque |
|---|---|---|---|---|---|---|---|---|---|
| 1 | LCQMC | 2018/6/6 | Centre de recherche informatique intelligent de l'Institut de technologie (Shenzhen) Harbin Institute of Technology) | Creative Commons Attribution 4.0 Licence internationale | Cet ensemble de données contient 260 068 paires de questions chinoises de plusieurs champs. Les paires de phrases avec la même intention d'enquête sont marquées comme 1, sinon elles sont 0; et ils sont segmentés en ensemble de formation: 238 766 paires, ensemble de validation: 8802 paires, ensemble de tests: 12 500 paires. | Correspondance de questions à grande échelle; correspondance d'intention | Correspondance du texte court; correspondance de questions | papier | |
| 2 | Le corpus BQ | 2018/9/4 | Centre de recherche informatique intelligent de l'Institut de technologie de Harbin (Shenzhen); Webank | Il y a 120 000 paires de phrases dans cet ensemble de données, du journal des services de conseil de la banque pendant un an; Les paires de phrases contiennent différentes intentions, marquées d'un rapport d'échantillons positifs et négatifs 1: 1. | Questions de service bancaire; correspondance d'intention | Correspondance du texte court; Détection de cohérence des questions | papier | ||
| 3 | AFQMC ANT Financial Semantic similitude | 2018/4/25 | Fourmi financière | Fournir 100 000 paires de données étiquetées (mise à jour par lots, mise à jour) en tant que données de formation, y compris les paires synonymes et différentes paires | Questions financières | Correspondance du texte court; correspondance de questions | |||
| 4 | La troisième compétition de la "Coupe magique magique" de Paipaidai | 2018/6/10 | Paipaidai Smart Finance Research Institute | Le fichier Train.csv contient 3 colonnes, à savoir l'étiquette (étiquette, ce qui signifie si la question 1 et la question 2 signifient la même, 1 signifie la même et 0 signifie la différence), le nombre de questions 1 (Q1) et le nombre de questions 2 (Q2). Tous les numéros de problème qui apparaissent dans ce fichier sont apparus dans Question.csv | Produits financiers | Correspondance du texte court; correspondance de questions | |||
| 5 | CAIL2019 Concours de correspondance de cas similaire | 2019/6 | Université Tsinghua; Réseau de documents de jugement en Chine | Pour chaque données, les triplets (A, B, C) sont utilisés pour représenter les données, où A, B, C correspondent tous à un certain document. La similitude entre les données de document A et B est toujours supérieure à la similitude entre A et B, c'est-à-dire SIM (A, B)> SIM (A, C) | Documents juridiques; cas similaires | Correspondant à texte long | |||
| 6 | CCKS 2018 Webank Intelligent Customer Service Question Matching Concours | 2018/4/5 | Centre de recherche informatique intelligent de l'Institut de technologie de Harbin (Shenzhen); Webank | Questions de service bancaire; correspondance d'intention | Correspondance du texte court; correspondance de questions | ||||
| 7 | Chinesextualinférence | 2018/12/15 | Liu Huanyong, Institut de recherche logicielle, Academy des sciences chinoises | Projet chinois d'inférence de texte, y compris la traduction et la construction de 880 000 ensembles de données chinois contenant du texte contenant du texte, et la construction d'un modèle de jugement contenant du texte basé sur l'apprentissage en profondeur | NLI chinois | Inférence du texte chinois; inclusion de texte | |||
| 8 | NLPCC-DBQA | 2016/2017/2018 | Nlpcc | Lice de question - la marque de la réponse, et si cette réponse est l'une des réponses à la question, 1 signifie oui, 0 signifie non | Dbqa | Match de questions-réponses | |||
| 9 | Modèle de calcul pour la corrélation entre les projets "Exigences techniques" et "réalisations techniques" | 201/8/32 | Ccf | Les exigences techniques et les réalisations techniques sous forme de texte donné, ainsi que l'étiquette de corrélation entre les exigences et les résultats; La corrélation entre les exigences techniques et les réalisations techniques est divisée en quatre niveaux: forte corrélation, forte corrélation, faible corrélation et aucune corrélation | Texte long; Les exigences correspondent aux résultats | Correspondant à texte long | |||
| 10 | CNSD / CLUE-CMNLI | 2019/12 | Zengjunjun | Ensemble de données chinois en matière d'inférence en matière de langue naturelle, ces données et l'ensemble de données anglais original sont générés par la traduction et une partie de la correction manuelle, ce qui peut atténuer le problème des ensembles de données d'inférence du langage naturel chinois insuffisant et de la similitude sémantique dans une certaine mesure. | NLI chinois | Inférence chinoise en matière de langue naturelle | papier | ||
| 11 | CMEDQA V1.0 | 2017/4/5 | Xunyao xunyi.com et l'École des systèmes d'information et de la gestion de la technologie nationale de la technologie de la défense | L'ensemble de données est la question et les réponses posées sur le site Web de Xunyi Xunpharma. L'ensemble de données a été traité de manière anonyme et fournit 50 000 questions et 94 134 réponses dans l'ensemble de formation, avec un nombre moyen de caractères par question et des réponses étant respectivement de 120 et 212; L'ensemble de vérification compte 2 000 questions et 3 774 réponses, avec un nombre moyen de caractères par question et des réponses étant respectivement de 117 et 212; L'ensemble de tests compte 2 000 questions et 3 835 réponses, avec un nombre moyen de caractères par question et réponse étant respectivement de 119 et 211; L'ensemble de données compte 54 000 questions et 101 743 réponses, avec un nombre moyen de caractères par question et réponse étant respectivement de 119 et 212; | Match des questions et réponses médicales | Match de questions-réponses | papier | ||
| 12 | cmedqa2 | 2018/11/8 | Xunyao xunyi.com et l'École des systèmes d'information et de la gestion de la technologie nationale de la technologie de la défense | La source de cet ensemble de données est les questions et réponses posées sur le site Web de Xunyi Xunpharma. L'ensemble de données a été traité de manière anonyme et fournit une collection de 100 000 questions et 188 490 réponses dans l'ensemble de formation, avec un nombre moyen de caractères par question et des réponses étant respectivement de 48 et 101; L'ensemble de vérification compte 4 000 questions et 7 527 réponses, avec un nombre moyen de caractères par question et réponse étant respectivement de 49 et 101; L'ensemble de tests compte 4 000 questions et 7 552 réponses, avec un nombre moyen de caractères par question et réponse étant respectivement de 49 et 100; Le nombre total de caractères par question et réponse étant de 108 000 questions et 203 569 réponses, avec un nombre moyen de caractères par question et réponse étant respectivement de 49 et 101; | Match des questions et réponses médicales | Match de questions-réponses | papier | ||
| 13 | Les plus chemises | 2017/9/21 | Tang Shancheng, Bai Yunyue, Ma Fuyu. Université des sciences et technologie xi'an | Cet ensemble de données fournit 12747 paires d'ensembles de données similaires chinois. Après l'ensemble de données, les auteurs donnent leurs scores de similitude et le corpus est composé de phrases courtes. | Correspondance de similitude de phrase courte | Correspondance de similitude | |||
| 14 | Ensemble de données du concours de mesure de similitude des problèmes médicaux organisé par la China Health Information Processing Conference | 2018 | CHIP 2018-la 4e Conférence chinoise de traitement de l'information sur la santé (CHIP) | L'objectif principal de cette tâche d'évaluation est de correspondre à l'intention des phrases de questions sur la base du vrai corpus de consultation en santé des patients chinois. Compte tenu de deux déclarations, il est nécessaire de déterminer si les intentions des deux sont identiques ou similaires. Tous les corpus proviennent de véritables questions de patients sur Internet et ont été dépistés et des étiquettes de correspondance d'intention artificielle. L'ensemble de données a été désensibilisé et le problème est marqué par l'ensemble de formation d'indication numérique contient environ 20 000 données marquées (désensibilisées, y compris les marques de ponctuation), et l'ensemble de test contient environ 10 000 données sans étiquette (désensibilisées, y compris les marques de ponctuation> symboles). | Correspondance de similitude pour les problèmes médicaux | Correspondance de similitude | |||
| 15 | COS960: un ensemble de données de similitude de mots chinois de 960 paires de mots | 2019/6/6 | Université Tsinghua | L'ensemble de données contient 960 paires de mots, et chaque paire est mesurée par 15 locuteurs natifs par des scores de similitude. Les 960 paires de mots sont divisées en trois groupes selon l'étiquette, dont 480 paires de noms, 240 paires de verbes et 240 paires d'adjectifs. | Similitude entre les mots | Synonymes | papier | ||
| 16 | Oppo Mobile Search Tri Trile-Titretle Match DataSet Matching Datas. (https://pan.baidu.com/s/1hg2hubsn3geuu4gubbhczw mot de passe 7p3n) | 2018/11/6 | Oppo | Cet ensemble de données provient du scénario de recherche en temps réel de la recherche de téléphones mobiles OPPO. Ce scénario renvoie la requête en temps réel lorsque l'utilisateur entre en permanence. Cet ensemble de données a été simplifié en conséquence sur cette base, fournissant une correspondance sémantique de requête, c'est-à-dire le problème de la prédiction CTR. | Question Titre correspondant, prédiction CTR | Correspondance de similitude | |||
| 17 | Évaluation des résultats de recherche sur le Web (SOGOUE) | 2012 | Sogou | Contrat de licence de données de laboratoire SOGOU | Cet ensemble de données contient des termes de requête, des URL connexes et des données de recherche pour les catégories de requête. Le format est le suivant: Termes de requête] URL Trelated TQuery Catégorie où les URL sont garanties d'exister dans le corpus Internet correspondant; "1" dans la catégorie des requêtes représente la requête de navigation; "2" représente la requête d'information. | Évaluation automatique des performances du moteur de recherche avec l'analyse des données de clics | Type de requête Prédiction de correspondance |
| IDENTIFIANT | titre | Date de mise à jour | Fournisseur d'ensemble de données | licence | illustrer | Mots clés | catégorie | Adresse papier | Remarque |
|---|---|---|---|---|---|---|---|---|---|
| 1 | LCST | 2015/8/6 | Qingcai Chen | L'ensemble de données provient de Sina Weibo et contient environ deux millions de textes courts chinois réels. Chaque données comprend deux champs, abstraits et texte annotés par l'auteur. Il y a 10 666 données marquées manuellement la corrélation entre le texte court et le résumé, et les corrélations sont augmentées à leur tour de 1 à 5. | Résumé de texte unique; texte court; Pertinence du texte | Résumé du texte | papier | ||
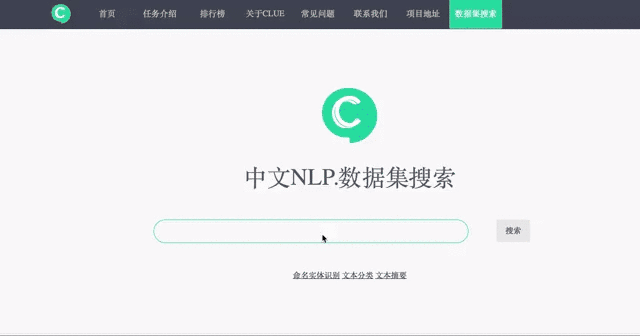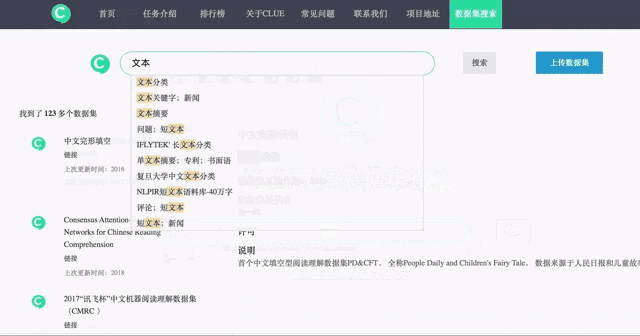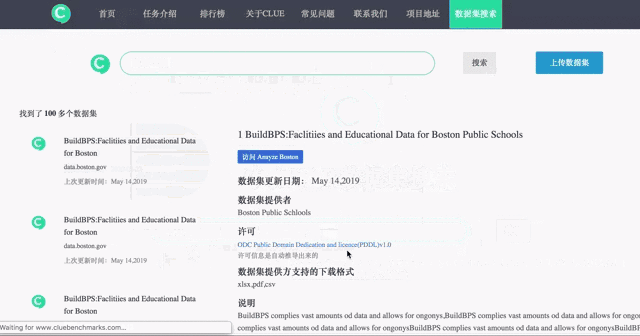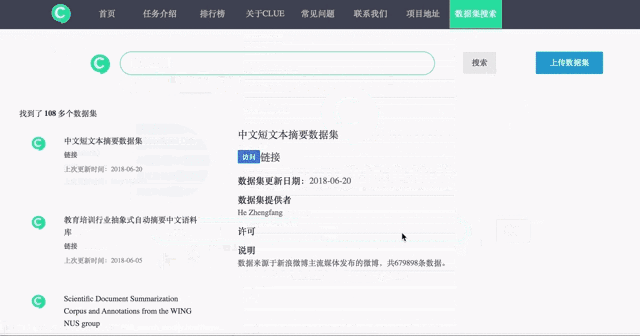
| 2 | Ensemble de données de résumé de texte court chinois | 2018/6/20 | Il zhengfang | Les données proviennent de Weibo publiée par Sina Weibo Mainstream Media, avec un total de 679 898 éléments de données. | Résumé de texte unique; texte court | Résumé du texte | |||
| 3 | Industrie de l'éducation et de la formation Résumé Automatique Résumé Corpus chinois | 2018/6/5 | anonyme | Le corpus recueille des articles historiques à partir de médias verticaux traditionnels dans l'industrie de l'éducation et de la formation, avec environ 24 500 éléments de données, chaque élément de données comprenant deux domaines annotés par l'auteur et le corps. | Résumé de texte unique; éducation et formation | Résumé du texte | |||
| 4 | NLPCC2017 Tâche3 | 2017/11/8 | Organisateur NLPCC2017 | L'ensemble de données est dérivé du domaine des actualités et est des données de tâche fournies par NLPCC 2017 et peut être utilisée pour un résumé à texte unique. | Résumé de texte unique; nouvelles | Résumé du texte | |||
| 5 | Coupe Shence 2018 | 2018/10/11 | Organisateur de concours DC | Les données proviennent du texte d'actualités et sont fournies par l'organisateur de la compétition DC. Il simule les scénarios commerciaux et vise à extraire les mots de base des textes d'actualités. Le résultat final est d'améliorer l'effet des recommandations et des portraits des utilisateurs. | Mots-clés texte; nouvelles | Résumé du texte | |||
| 6 | Compétition internationale de l'apprentissage automatique de la Coupe des octets 2018 | 2018/12/4 | Bytedance | Les données proviennent des articles TopBuzz et Open Copyright de ByTedance. L'ensemble de formation comprend environ 1,3 million d'informations en texte, 1 000 articles dans l'ensemble de vérification et 800 articles dans l'ensemble de tests. Les données pour chaque ensemble de tests et ensemble de validation sont étiquetées manuellement avec plusieurs titres possibles comme alternative de réponse via l'édition manuelle. | Résumé de texte unique; vidéo; nouvelles | Résumé du texte | Anglais | ||
| 7 | RÉDACTION | 2018/6/1 | Grusky | Les données ont été obtenues à partir de métadonnées de recherche et sociales de 1998 à 2017 et ont utilisé une combinaison de stratégies abstraites qui combinent l'extraction et l'abstraction, y compris 1,3 million d'articles et résumés écrits par l'auteur et le rédacteur en chef dans 38 services éditoriaux de publication majeure. | Résumé de texte unique; métadonnées sociales; recherche | Résumé du texte | papier | Anglais | |
| 8 | [Duc / tac] (https://duc.nist.gov/ https://tac.nist.gov//) | 2014/9/9 | Nist | Le nom complet est la conférence des conférences / analyse de texte de la compréhension des documents. L'ensemble de données est dérivé des lignes d'information et des textes Web dans le corpus utilisé dans la compétition annuelle de la population de base de base de KBP (TAC de Knowledge Base). | Résumé de texte / texte multi-texte; nouvelles | Résumé du texte | Anglais | ||
| 9 | CNN / Daily Mail | 2017/7/31 | Standford | GNU V3 | L'ensemble de données provient de CNN et Dailymail sur les téléphones mobiles environ un million de données d'actualités en tant que corpus de compréhension de la lecture des machines. | Résumé multi-texte; texte long; nouvelles | Résumé du texte | papier | Anglais |
| 10 | Amazon Snap Review | 2013/3/1 | Standford | Les données proviennent des avis d'achat d'Amazon au site Web, et vous pouvez obtenir des données dans chaque catégorie principale (telles que la nourriture, les films, etc.), ou vous pouvez obtenir toutes les données à la fois. | Résumé multi-texte; Avis d'achat | Résumé du texte | Anglais | ||
| 11 | Gigaword | 2003/1/28 | David Graff, Christopher Cieri | L'ensemble de données comprend environ 950 000 articles d'information, qui sont résumés par le titre de l'article, et appartiennent à l'ensemble de données de résumé de phrases. | Résumé de texte unique; nouvelles | Résumé du texte | Anglais | ||
| 12 | RA-MDS | 2017/9/11 | Piji li | Le nom complet est le résumé multi-documents conscient du lecteur. L'ensemble de données est dérivé des articles de presse et est collecté, marqué et examiné par des experts. 45 sujets sont couverts, chacun avec 10 documents d'actualités et 4 résumé du modèle, chaque document d'actualité contient une moyenne de 27 phrases et une moyenne de 25 mots par phrase. | Résumé multi-texte; nouvelles; étiquetage manuel | Résumé du texte | papier | Anglais | |
| 13 | Sommeur | 2003/5/21 | La Miters Corporation et l'Université d'Édimbourg | Les données comprennent 183 documents marqués par la collection de calcul et de langue (CMP-LG), et les documents sont tirés des articles publiés par la conférence ACL. | Résumé multi-texte; texte long | Résumé du texte | Anglais | ||
| 14 | Wikihow | 2018/10/18 | Mahnaz Koupaee | Chaque données est un article, chaque article se compose de plusieurs paragraphes, chaque paragraphe commence par une phrase qui la résume. En fusionnant les paragraphes pour former des articles et des contours de paragraphes pour former des résumés, la version finale de l'ensemble de données contient plus de 200 000 paires de séquences longues. | Résumé multi-texte; texte long | Résumé du texte | papier | Anglais | |
| 15 | Multi-neuf | 2019/12/4 | Alex Fabbri | Les données proviennent d'articles d'entrée de plus de 1500 sites Web différents et de résumé professionnel de 56 216 de ces articles obtenus sur le site Web Newser.com. | Résumé du texte multi-texte | Résumé du texte | papier | Anglais | |
| 16 | Résuménomaires des médicaments | 2018/8/17 | D.potapov | L'ensemble de données est utilisé pour l'évaluation dynamique du résumé vidéo et contient des annotations pour 160 vidéos, y compris 60 ensembles de validation, 100 ensembles de tests et 10 catégories d'événements dans l'ensemble de tests. | Résumé de texte unique; commentaires vidéo | Résumé du texte | papier | Anglais | |
| 17 | Bigpatent | 2019/7/27 | Sharma | L'ensemble de données comprend 1,3 million de dossiers de documents de brevet américains et des résumés de résumés écrits humains qui contiennent des structures de discours plus riches et des entités plus couramment utilisées. | Résumé de texte unique; brevet; écrit | Résumé du texte | papier | Anglais | |
| 18 | [NYT] (https://catalog.ldc.upenn.edu/LDC2008T19) | 2008/10/17 | Evan Sandhaus | Le nom complet est le New York Times, l'ensemble de données contient 150 articles commerciaux du New York Times et capture tous les articles sur le site Web du New York Times de novembre 2009 à janvier 2010. | Résumé de texte unique; article commercial | Résumé du texte | Anglais | ||
| 19 | L'Aquaint Corpus of English News Text | 2002/9/26 | David Graff | L'ensemble de données se compose de données de texte de presse anglaises de l'agence de presse Xinhua (République populaire de Chine), du New York Times News Service et d'Associated Press World News Service, et contient environ 375 millions de mots. Frais de jeu de données. | Résumé de texte unique; nouvelles | Résumé du texte | Chinois et anglais | ||
| 20 | Ensemble de données de rapports de cas juridiques | 2012/10/19 | Filippo Galgani | L'ensemble de données provient des affaires juridiques australiennes de la Cour fédérale d'Australie (FCA) de 2006 à 2009 et contient environ 4 000 affaires juridiques et leur résumé. | Résumé de texte unique; affaire juridique | Résumé du texte | Anglais | ||
| vingt-et-un | 17 délais | 2015/5/29 | GB Tran | Les données sont du contenu extrait des pages Web d'articles de presse, y compris les nouvelles de quatre pays: l'Égypte, la Libye, le Yémen et la Syrie. | Résumé de texte unique; nouvelles | Résumé du texte | papier | Multilingue | |
| vingt-deux | PTS Corpus | 2018/10/9 | Fei Sun | Le nom complet est le corpus de résumé de titre de produit, les données affichent le résumé des noms de produits dans les applications de commerce électronique pour les appareils mobiles | Résumé de texte unique; texte court | Résumé du texte | papier | ||
| vingt-trois | Ensembles de données de résumé scientifique | 2019/10/26 | Santosh Gupta | L'ensemble de données a été tiré de Semantic Scholar Corpus et Arxiv. Titre / paire abstrait de Semantic Scholar Corpus, filtrant tous les articles dans le domaine de la biomédicale et contient 5,8 millions de données. Données d'Arxiv, contenant des paires de titres / abstraites de chaque article de 1991 au 5 juillet 2019. L'ensemble de données contient 10k de données financières, 26k de biologie, 417k de mathématiques, 1,57 million de physique et 221k de CS. | Résumé de texte unique; papier | Résumé du texte | Anglais | ||
| vingt-quatre | Corpus de résumé des documents scientifiques et annotations du groupe Wing NUS | 2019/3/19 | Jaidka | L'ensemble de données comprend des articles de recherche sur la linguistique informatique de la LCA et le traitement du langage naturel, ainsi que leurs articles cités respectifs et trois résumés de sortie: un résumé de l'article d'un auteur traditionnel (résumé), un résumé communautaire (une collection de «citations» de déclaration de citation) et un résumé humain écrit par un annotateur formé, et l'ensemble de formation contient 40 articles et des articles cités. | Résumé de texte unique; papier | Résumé du texte | papier | Anglais |
| IDENTIFIANT | titre | Date de mise à jour | Fournisseur d'ensemble de données | licence | illustrer | Mots clés | catégorie | Adresse papier | Remarque |
|---|---|---|---|---|---|---|---|---|---|
| 1 | WMT2017 | 2017/2/1 | Atelier EMNLP 2017 sur la traduction machine | Les données proviennent principalement des deux institutions Europarl Corpus et du Corpus de l'ONU, et s'accompagne d'articles réexpertés de la tâche du Corpus de commentaires de nouvelles en 2017. Il s'agit d'un corpus de traduction fourni par la conférence EMNLP, en tant que référence pour de nombreux effets papier à détecter | Benchmark, WMT2017 | Matériaux de traduction chinois-anglais | papier | ||
| 2 | WMT2018 | 2018/11/1 | Atelier EMNLP 2018 sur la traduction machine | 数据主要来源于Europarl corpus和UN corpus两个机构, 附带2018年从News Commentary corpus 任务中重新抽取的文章。 这是由EMNLP会议提供的翻译语料, 作为很多论文效果的benchmark来检测 | Benchmark, WMT2018 | 中英翻译语料 | papier | ||
| 3 | WMT2019 | 2019/1/31 | EMNLP 2019 Workshop on Machine Translation | 数据主要来源于Europarl corpus和UN corpus两个机构, 以及附加了news-commentary corpus and the ParaCrawl corpus中来得数据 | Benchmark, WMT2019 | 中英翻译语料 | papier | ||
| 4 | UM-Corpus:A Large English-Chinese Parallel Corpus | 2014/5/26 | Department of Computer and Information Science, University of Macau, Macau | 由澳门大学发布的中英文对照的高质量翻译语料 | UM-Corpus;English; Chinese;large | 中英翻译语料 | papier | ||
| 5 | [Ai challenger translation 2017](https://pan.baidu.com/s/1E5gD5QnZvNxT3ZLtxe_boA 提取码: stjf) | 2017/8/14 | 创新工场、搜狗和今日头条联合发起的AI科技竞赛 | 规模最大的口语领域英中双语对照数据集。 提供了超过1000万的英中对照的句子对作为数据集合。 所有双语句对经过人工检查, 数据集从规模、相关度、质量上都有保障。 训练集:10,000,000 句验证集(同声传译):934 句验证集(文本翻译):8000 句 | AI challenger 2017 | 中英翻译语料 | |||
| 6 | MultiUN | 2010 | Department of Linguistics and Philology Uppsala University, Uppsala/Sweden | 该数据集由德国人工智能研究中心提供, 除此数据集外,该网站还提供了很多的别的语言之间的翻译对照语料供下载 | MultiUN | 中英翻译语料 | MultiUN: A Multilingual corpus from United Nation Documents, Andreas Eisele and Yu Chen, LREC 2010 | ||
| 7 | NIST 2002 Open Machine Translation (OpenMT) Evaluation | 2010/5/14 | NIST Multimodal Information Group | LDC User Agreement for Non-Members | 数据来源于Xinhua 新闻服务包含70个新闻故事, 以及来自于Zaobao新闻服务的30个新闻故事,共100个从两个新闻集中选择出来的故事的长度都再212到707个中文字符之间,Xinhua部分共有有25247个字符, Zaobao有39256个字符 | NIST | 中英翻译语料 | papier | 该系列有多年的数据, 该数据使用需要付费 |
| 8 | The Multitarget TED Talks Task (MTTT) | 2018 | Kevin Duh, JUH | 该数据集包含基于TED演讲的多种语言的平行语料,包含中英文等共计20种语言 | Gâter | 中英翻译语料 | The Multitarget TED Talks Task | ||
| 9 | ASPEC Chinese-Japanese | 2019 | Workshop on Asian Translation | 该数据集主要研究亚洲区域的语言,如中文和日语之间, 日语和英文之间的翻译任务翻译语料主要来自语科技论文(论文摘要;发明描述;专利等等) | Asian scientific patent Japanese | 中日翻译语料 | http://lotus.kuee.kyoto-u.ac.jp/WAT/ | ||
| 10 | casia2015 | 2015 | research group in Institute of Automation , Chinese Academy of Sciences | 语料库包含从网络自动收集的大约一百万个句子对 | casia CWMT 2015 | 中英翻译语料 | |||
| 11 | casict2011 | 2011 | research group in Institute of Computing Technology , Chinese Academy of Sciences | 语料库包含2个部分,每个部分包含从网络自动收集的大约1百万(总计2百万)个句子对。 句子级别的对齐精度约为90%。 | casict CWMT 2011 | 中英翻译语料 | |||
| 12 | casict2015 | 2015 | research group in Institute of Computing Technology , Chinese Academy of Sciences | 语料库包含大约200万个句子对,包括从网络(60%), 电影字幕(20%)和英语/汉语词库(20%)收集的句子。 句子水平对齐精度高于99%。 | casict CWMT 2015 | 中英翻译语料 | |||
| 13 | datum2015 | 2015 | Datum Data Co., Ltd. | 语料库包含一百万对句子,涵盖不同类型, 例如用于语言教育的教科书,双语书籍, 技术文档,双语新闻,政府白皮书, 政府文档,网络上的双语资源等。 请注意,数据中文部分的某些部分是按词段划分的。 | datum CWMT 2015 | 中英翻译语料 | |||
| 14 | datum2017 | 2017 | Datum Data Co., Ltd. | 语料库包含20个文件,涵盖不同类型,例如新闻,对话,法律文件,小说等。 每个文件有50,000个句子。 整个语料库包含一百万个句子。 前10个文件(Book1-Book10)的中文词均已分段。 | datum CWMT 2017 | 中英翻译语料 | |||
| 15 | neu2017 | 2017 | NLP lab of Northeastern University, China | 语料库包含从网络自动收集的200万个句子对,包括新闻,技术文档等。 句子级别的对齐精度约为90%。 | neu CWMT 2017 | 中英翻译语料 | |||
| 16 | 翻译语料(translation2019zh) | 2019 | 徐亮 | 可以用于训练中英文翻译系统,从中文翻译到英文,或从英文翻译到中文; 由于有上百万的中文句子,可以只抽取中文的句子,做为通用中文语料,训练词向量或做为预训练的语料。英文任务也可以类似操作; |
| IDENTIFIANT | titre | 更新日期 | 数据集提供者 | licence | illustrer | Mots clés | catégorie | 论文地址 | Remarque |
|---|---|---|---|---|---|---|---|---|---|
| 1 | NLPIR微博关注关系语料库100万条 | 2017/12/2 | 北京理工大学网络搜索挖掘与安全实验室张华平博士 | NLPIR微博关注关系语料库说明1.NLPIR微博关注关系语料库由北京理工大学网络搜索挖掘与安全实验室张华平博士,通过公开采集与抽取从新浪微博、腾讯微博中获得。为了推进微博计算的研究,现通过自然语言处理与信息检索共享平台(127.0.0.1/wordpress)予以公开共享其中的1000万条数据(目前已有数据接近10亿,已经剔除了大量的冗余数据); 2.本语料库在公开过程中,已经最大限度地采用技术手段屏蔽了用户真实姓名和url,如果涉及到的用户需要全面保护个人隐私的,可以Email给张华平博士[email protected]予以删除,对给您造成的困扰表示抱歉,并希望谅解; 3.只适用于科研教学用途,不得作为商用;引用本语料库,恭请在软件或者论文等成果特定位置表明出处为:NLPIR微博语料库,出处为自然语言处理与信息检索共享平台(http://www.nlpir.org/)。 4.字段说明: person_id 人物的id guanzhu_id 所关注人的id |
| IDENTIFIANT | titre | 更新日期 | 数据集提供者 | licence | illustrer | Mots clés | catégorie | 论文地址 | Remarque |
|---|---|---|---|---|---|---|---|---|---|
| 1 | NLPIR微博内容语料库-23万条 | 2017年12月 | 北京理工大学网络搜索挖掘与安全实验室张华平博士 | NLPIR微博内容语料库说明1.NLPIR微博内容语料库由北京理工大学网络搜索挖掘与安全实验室张华平博士,通过公开采集与抽取从新浪微博、腾讯微博中获得。为了推进微博计算的研究,现通过自然语言处理与信息检索共享平台(127.0.0.1/wordpress)予以公开共享其中的23万条数据(目前已有数据接近1000万,已经剔除了大量的冗余数据)。 2.本语料库在公开过程中,已经最大限度地采用技术手段屏蔽了用户真实姓名和url,如果涉及到的用户需要全面保护个人隐私的,可以Email给张华平博士[email protected]予以删除,对给您造成的困扰表示抱歉,并希望谅解; 3.只适用于科研教学用途,不得作为商用;引用本语料库,恭请在软件或者论文等成果特定位置表明出处为:NLPIR微博语料库,出处为自然语言处理与信息检索共享平台(http://www.nlpir.org/)。 4.字段说明: id 文章编号article 正文discuss 评论数目insertTime 正文插入时间origin 来源person_id 所属人物的id time 正文发布时间transmit 转发 | |||||
| 2 | 500万微博语料 | 2018年1月 | 北京理工大学网络搜索挖掘与安全实验室张华平博士 | 【500万微博语料】北理工搜索挖掘实验室主任@ICTCLAS张华平博士提供500万微博语料供大家使用,文件为sql文件,只能导入mysql数据库,内含建表语句,共500万数据。语料只适用于科研教学用途,不得作为商用;引用本语料库,请在软件或者论文等成果特定位置表明出处。 【看起来这份数据比上面那一份要杂糅一些,没有做过处理】 | |||||
| 3 | NLPIR新闻语料库-2400万字 | 2017年7月 | www.NLPIR.org | NLPIR新闻语料库说明1.解压缩后数据量为48MB,大约2400万字的新闻; 2.采集的新闻时间跨度为2009年10月12日至2009年12月14日。 3.文件名为新闻的时间;每个文件包括多个新闻正文内容(已经去除了新闻的垃圾信息); 4.新闻本身内容的版权属于原作者或者新闻机构; 5.整理后的语料库版权属于www.NLPIR.org; 6.可供新闻分析、自然语言处理、搜索等应用提供测试数据场景; 如需更大规模的语料库,可以联系NLPIR.org管理员。 | |||||
| 4 | NLPIR微博关注关系语料库100万条 | 2017年12月 | 北京理工大学网络搜索挖掘与安全实验室张华平博士 | NLPIR微博关注关系语料库说明1.NLPIR微博关注关系语料库由北京理工大学网络搜索挖掘与安全实验室张华平博士,通过公开采集与抽取从新浪微博、腾讯微博中获得。为了推进微博计算的研究,现通过自然语言处理与信息检索共享平台(127.0.0.1/wordpress)予以公开共享其中的1000万条数据(目前已有数据接近10亿,已经剔除了大量的冗余数据); 2.本语料库在公开过程中,已经最大限度地采用技术手段屏蔽了用户真实姓名和url,如果涉及到的用户需要全面保护个人隐私的,可以Email给张华平博士[email protected]予以删除,对给您造成的困扰表示抱歉,并希望谅解; 3.只适用于科研教学用途,不得作为商用;引用本语料库,恭请在软件或者论文等成果特定位置表明出处为:NLPIR微博语料库,出处为自然语言处理与信息检索共享平台(http://www.nlpir.org/)。 4.字段说明: person_id 人物的id guanzhu_id 所关注人的id | |||||
| 5 | NLPIR微博博主语料库100万条 | 2017年9月 | 北京理工大学网络搜索挖掘与安全实验室张华平博士 | NLPIR微博博主语料库说明1.NLPIR微博博主语料库由北京理工大学网络搜索挖掘与安全实验室张华平博士,通过公开采集与抽取从新浪微博、腾讯微博中获得。为了推进微博计算的研究,现通过自然语言处理与信息检索共享平台(127.0.0.1/wordpress)予以公开共享其中的100万条数据(目前已有数据接近1亿,已经剔除了大量的冗余与机器粉丝) 2.本语料库在公开过程中,已经最大限度地采用技术手段屏蔽了用户真实姓名和url,如果涉及到的用户需要全面保护个人隐私的,可以Email给张华平博士[email protected]予以删除,对给您造成的困扰表示抱歉,并希望谅解; 3.只适用于科研教学用途,不得作为商用;引用本语料库,恭请在软件或者论文等成果特定位置表明出处为:NLPIR微博语料库,出处为自然语言处理与信息检索共享平台(http://www.nlpir.org/)。 4.字段说明: id 内部id sex 性别address 家庭住址fansNum 粉丝数目summary 个人摘要wbNum 微博数量gzNum 关注数量blog 博客地址edu 教育情况work 工作情况renZh 是否认证brithday 生日; | |||||
| 6 | NLPIR短文本语料库-40万字 | 2017年8月 | 北京理工大学网络搜索挖掘与安全实验室(SMS@BIT) | NLPIR短文本语料库说明1.解压缩后数据量为48万字,大约8704篇短文本内容; 2.整理后的语料库版权属于www.NLPIR.org; 3.可供短文本自然语言处理、搜索、舆情分析等应用提供测试数据场景; | |||||
| 7 | 维基百科语料库 | Wikipedia | 维基百科会定期打包发布语料库 | ||||||
| 8 | 古诗词数据库 | 2020 | github主爬虫,http://shici.store | ||||||
| 9 | 保险行业语料库 | 2017 | 该语料库包含从网站Insurance Library 收集的问题和答案。 据我们所知,这是保险领域首个开放的QA语料库: 该语料库的内容由现实世界的用户提出,高质量的答案由具有深度领域知识的专业人士提供。 所以这是一个具有真正价值的语料,而不是玩具。 在上述论文中,语料库用于答复选择任务。 另一方面,这种语料库的其他用法也是可能的。 例如,通过阅读理解答案,观察学习等自主学习,使系统能够最终拿出自己的看不见的问题的答案。 数据集分为两个部分“问答语料”和“问答对语料”。问答语料是从原始英文数据翻译过来,未经其他处理的。问答对语料是基于问答语料,又做了分词和去标去停,添加label。所以,"问答对语料"可以直接对接机器学习任务。如果对于数据格式不满意或者对分词效果不满意,可以直接对"问答语料"使用其他方法进行处理,获得可以用于训练模型的数据。 | ||||||
| 10 | 汉语拆字字典 | 1905年7月 | 本倉庫含開放詞典網用以提供字旁和部件查詢的拆字字典數據庫,有便利使用者查難打漢字等用途。目前數據庫收錄17,803不同漢字的拆法,分為繁體字(chaizi-ft.txt)和簡體字(chaizi-jt.txt)兩個版本。 拆字法有別於固有的筆順字庫。拆字著重於儘量把每個字拆成兩個以上的組成部件,而不是拆成手寫字時所使用的筆畫。 | ||||||
| 11 | 新闻预料 | 2016 | 徐亮 | 可以做为【通用中文语料】,训练【词向量】或做为【预训练】的语料; 也可以用于训练【标题生成】模型,或训练【关键词生成】模型(选关键词内容不同于标题的数据); 亦可以通过新闻渠道区分出新闻的类型。 | |||||
| 12 | 百科类问答json版(baike2018qa) | 2018 | 徐亮 | 可以做为通用中文语料,训练词向量或做为预训练的语料;也可以用于构建百科类问答;其中类别信息比较有用,可以用于做监督训练,从而构建更好句子表示的模型、句子相似性任务等。 | |||||
| 13 | 社区问答json版(webtext2019zh) :大规模高质量数据集 | 2019 | 徐亮 | 1)构建百科类问答:输入一个问题,构建检索系统得到一个回复或生产一个回复;或根据相关关键词从,社区问答库中筛选出你相关的领域数据2)训练话题预测模型:输入一个问题(和或描述),预测属于话题。 3)训练社区问答(cQA)系统:针对一问多答的场景,输入一个问题,找到最相关的问题,在这个基础上基于不同答案回复的质量、 问题与答案的相关性,找到最好的答案。 4)做为通用中文语料,做大模型预训练的语料或训练词向量。其中类别信息也比较有用,可以用于做监督训练,从而构建更好句子表示的模型、句子相似性任务等。 5)结合点赞数量这一额外信息,预测回复的受欢迎程度或训练答案评分系统。 | |||||
| 14 | .维基百科json版(wiki2019zh) | 2019 | 徐亮 | 可以做为通用中文语料,做预训练的语料或构建词向量,也可以用于构建知识问答。【不同于wiki原始释放的数据集,这个处理过了】 |
| IDENTIFIANT | titre | 更新日期 | 数据集提供者 | licence | illustrer | Mots clés | catégorie | 论文地址 | Remarque |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 百度WebQA | 2016 | Baidu | 来自于百度知道;格式为一个问题多篇意思基本一致的文章,分为人为标注以及浏览器检索 | 阅读理解、百度知道真实问题 | 中文阅读理解 | papier | ||
| 2 | DuReader 1.0 | 2018/3/1 | Baidu | Apache2.0 | 本次竞赛数据集来自搜索引擎真实应用场景,其中的问题为百度搜索用户的真实问题,每个问题对应5个候选文档文本及人工整理的优质答案。 | 阅读理解、百度搜索真实问题 | 中文阅读理解 | papier | |
| 3 | SogouQA | 2018 | Sogou | CIPS-SOGOU问答比赛数据;来自于搜狗搜索引擎真实用户提交的查询请求;含有事实类与非事实类数据 | 阅读理解、搜狗搜索引擎真实问题 | 中文阅读理解 | |||
| 4 | 中文法律阅读理解数据集CJRC | 2019/8/17 | 哈工大讯飞联合实验室(HFL) | 数据集包含约10,000篇文档,主要涉及民事一审判决书和刑事一审判决书。通过抽取裁判文书的事实描述内容,针对事实描述内容标注问题,最终形成约50,000个问答对 | 阅读理解、中文法律领域 | 中文阅读理解 | papier | ||
| 5 | 2019“讯飞杯”中文机器阅读理解数据集(CMRC ) | Octobre 2019 | 哈工大讯飞联合实验室(HFL) | CC-BY-SA-4.0 | 本次阅读理解的任务是句子级填空型阅读理解。 根据给定的一个叙事篇章以及若干个从篇章中抽取出的句子,参赛者需要建立模型将候选句子精准的填回原篇章中,使之成为完整的一篇文章。 | 句子级填空型阅读理解 | 中文阅读理解 | 赛事官网:https://hfl-rc.github.io/cmrc2019/ | |
| 6 | 2018“讯飞杯”中文机器阅读理解数据集(CMRC ) | 2018/10/19 | 哈工大讯飞联合实验室(HFL) | CC-BY-SA-4.0 | CMRC 2018数据集包含了约20,000个在维基百科文本上人工标注的问题。同时,我们还标注了一个挑战集,其中包含了需要多句推理才能够正确解答的问题,更富有挑战性 | 阅读理解、基于篇章片段抽取 | 中文阅读理解 | papier | 赛事官网:https://hfl-rc.github.io/cmrc2018/ |
| 7 | 2017“讯飞杯”中文机器阅读理解数据集(CMRC ) | 2017/10/14 | 哈工大讯飞联合实验室(HFL) | CC-BY-SA-4.0 | 首个中文填空型阅读理解数据集PD&CFT | 填空型阅读理解 | 中文阅读理解 | papier | 赛事官网 |
| 8 | 莱斯杯:全国第二届“军事智能机器阅读”挑战赛 | 2019/9/3 | 中电莱斯信息系统有限公司 | 面向军事应用场景的大规模中文阅读理解数据集,围绕多文档机器阅读理解进行竞赛,涉及理解、推理等复杂技术。 | 多文档机器阅读理解 | 中文阅读理解 | 赛事官网 | ||
| 9 | ReCO | 2020 | Sogou | 来源于搜狗的浏览器用户输入;有多选和直接答案 | 阅读理解、搜狗搜索 | 中文阅读理解 | papier | ||
| 10 | DuReader-checklist | 2021/3 | Baidu | Apache-2.0 | 建立了细粒度的、多维度的评测数据集,从词汇理解、短语理解、语义角色理解、逻辑推理等多个维度检测模型的不足之处,从而推动阅读理解评测进入“精细化“时代 | 细粒度阅读理解 | 中文阅读理解 | 赛事官网 | |
| 11 | DuReader-Robust | 2020/8 | Baidu | Apache-2.0 | 从过敏感性,过稳定性以及泛化性多个维度构建了测试阅读理解鲁棒性的数据 | 百度搜索、鲁棒性阅读理解 | 中文阅读理解 | papier | 赛事官网 |
| 12 | DuReader-YesNo | 2020/8 | Baidu | Apache-2.0 | DuReader yesno是一个以观点极性判断为目标任务的数据集,可以弥补抽取类数据集评测指标的缺陷,从而更好地评价模型对观点极性的理解能力。 | 观点型阅读理解 | 中文阅读理解 | 赛事官网 | |
| 13 | DuReader2.0 | 2021 | Baidu | Apache-2.0 | DuReader2.0是全新的大规模中文阅读理解数据,来源于用户真实输入,真实场景 | 阅读理解 | 中文阅读理解 | papier | 赛事官网 |
| 14 | CAIL2020 | 2020 | 哈工大讯飞联合实验室(HFL) | 中文司法阅读理解任务,今年我们将提出升级版,不仅文书种类由民事、刑事扩展为民事、刑事、行政,问题类型也由单步预测扩展为多步推理,难度有所升级。 | 法律阅读理解 | 中文阅读理解 | 赛事官网 | ||
| 15 | CAIL2021 | 2021 | 哈工大讯飞联合实验室(HFL) | 中文法律阅读理解比赛引入多片段回答的问题类型,即部分问题需要抽取文章中的多个片段组合成最终答案。希望多片段问题类型的引入,能够扩大中文机器阅读理解的场景适用性。本次比赛依旧保留单片段、是否类和拒答类的问题类型。 | 法律阅读理解 | 中文阅读理解 | 赛事官网 | ||
| 16 | CoQA | 2018/9 | 斯坦福大学 | CC BY-SA 4.0、Apache等 | CoQA是面向建立对话式问答系统的大型数据集,挑战的目标是衡量机器对文本的理解能力,以及机器面向对话中出现的彼此相关的问题的回答能力的高低 | 对话问答 | 英文阅读理解 | papier | Site officiel |
| 17 | SQuAD2.0 | 2018/1/11 | 斯坦福大学 | 行业内公认的机器阅读理解领域的顶级水平测试;它构建了一个包含十万个问题的大规模机器阅读理解数据集,选取超过500 篇的维基百科文章。数据集中每一个阅读理解问题的答案是来自给定的阅读文章的一小段文本—— 以及,现在在SQuAD 2.0 中还要判断这个问题是否能够根据当前的阅读文本作答 | 问答、包含未知答案 | 英文阅读理解 | papier | ||
| 18 | SQuAD1.0 | 2016 | 斯坦福大学 | 斯坦福大学于2016年推出的阅读理解数据集,给定一篇文章和相应问题,需要算法给出问题的答案。此数据集所有文章选自维基百科,一共有107,785问题,以及配套的536 篇文章 | 问答、基于篇章片段抽取 | 英文阅读理解 | papier | ||
| 19 | MCTest | 2013 | Microsoft | 100,000个必应Bing问题和人工生成的答案。从那时起,相继发布了1,000,000个问题数据集,自然语言生成数据集,段落排名数据集,关键词提取数据集,爬网数据集和会话搜索。 | 问答、搜索 | 英文阅读理解 | papier | ||
| 20 | CNN/Dailymail | 2015 | DeepMind | Apache-2.0 | 填空型大规模英文机器理解数据集,答案是原文中的某一个词。 CNN数据集包含美国有线电视新闻网的新闻文章和相关问题。大约有90k文章和380k问题。 Dailymail数据集包含每日新闻的文章和相关问题。大约有197k文章和879k问题。 | 问答对、填空型阅读理解 | 英文阅读理解 | papier | |
| vingt-et-un | COURSE | 2017 | 卡耐基梅隆大学 | / / | 数据集为中国中学生英语阅读理解题目,给定一篇文章和5 道4 选1 的题目,包括了28000+ passages 和100,000 问题。 | 选择题形式 | 英文阅读理解 | papier | 下载需邮件申请 |
| vingt-deux | HEAD-QA | 2019 | aghie | MIT | 一个面向复杂推理的医疗保健、多选问答数据集。提供英语、西班牙语两种形式的数据 | 医疗领域、选择题形式 | 英文阅读理解西班牙语阅读理解 | papier | |
| vingt-trois | Consensus Attention-based Neural Networks for Chinese Reading Comprehension | 2018 | 哈工大讯飞联合实验室 | / / | 中文完形填空型阅读理解 | 填空型阅读理解 | 中文阅读理解 | papier | |
| vingt-quatre | WikiQA | 2015 | Microsoft | / / | WikiQA语料库是一个新的公开的问题和句子对集,收集并注释用于开放域问答研究 | 片段抽取阅读理解 | 英文阅读理解 | papier | |
| 25 | Children's Book Test (CBT) | 2016 | / / | 测试语言模型如何在儿童书籍中捕捉意义。与标准语言建模基准不同,它将预测句法功能词的任务与预测语义内容更丰富的低频词的任务区分开来 | 填空型阅读理解 | 英文阅读理解 | papier | ||
| 26 | NewsQA | 2017 | Maluuba Research | / / | 一个具有挑战性的机器理解数据集,包含超过100000个人工生成的问答对,根据CNN的10000多篇新闻文章提供问题和答案,答案由相应文章的文本跨度组成。 | 片段抽取阅读理解 | 英文阅读理解 | papier | |
| 27 | Frames dataset | 2017 | Microsoft | / / | 介绍了一个由1369个人类对话组成的框架数据集,平均每个对话15轮。开发这个数据集是为了研究记忆在目标导向对话系统中的作用。 | 阅读理解、对话 | 英文阅读理解 | papier | |
| 28 | Quasar | 2017 | 卡内基梅隆大学 | BSD-2-Clause | 提出了两个大规模数据集。Quasar-S数据集由37000个完形填空式查询组成,这些查询是根据流行网站Stack overflow 上的软件实体标记的定义构造的。网站上的帖子和评论是回答完形填空问题的背景语料库。Quasar-T数据集包含43000个开放域琐事问题及其从各种互联网来源获得的答案。 | 片段抽取阅读理解 | 英文阅读理解 | papier | |
| 29 | MS MARCO | 2018 | Microsoft | / / | 微软基于搜索引擎BING 构建的大规模英文阅读理解数据集,包含10万个问题和20万篇不重复的文档。MARCO 数据集中的问题全部来自于BING 的搜索日志,根据用户在BING 中输入的真实问题模拟搜索引擎中的真实应用场景,是该领域最有应用价值的数据集之一。 | 多文档 | 英文阅读理解 | papier | |
| 30 | 中文完形填空 | 2016 | 崔一鸣 | 首个中文填空型阅读理解数据集PD&CFT, 全称People Daily and Children's Fairy Tale, 数据来源于人民日报和儿童故事。 | 填空型阅读理解 | 中文完形填空 | papier | ||
| 31 | NLPCC ICCPOL2016 | 2016.12.2 | NLPCC主办方 | 基于文档中的句子人工合成14659个问题,包括14K中文篇章。 | 问答对阅读理解 | 中文阅读理解 |
感谢以下同学的贡献(排名不分先后)
郑少棉、李明磊、李露、叶琛、薛司悦、章锦川、李小昌、李俊毅
Vous pouvez contribuer votre alimentation en téléchargeant des informations sur l'ensemble de données. Après avoir téléchargé cinq ensembles de données ou plus et les avoir examinés, l'étudiant peut être utilisé comme contributeur de projet et les afficher.
Share your data set with community or make a contribution today! Just send email to chineseGLUE#163.com,
or join QQ group: 836811304


