
Livre de cuisine TensorFlow Machine Learn
Un livre de publication Packt
Par Nick McClure
==================
Construire:
==================
Table des matières
- CH 1: commencer avec Tensorflow
- CH 2: la manière TensorFlow
- CH 3: régression linéaire
- CH 4: Machines vectorielles de support
- CH 5: Méthodes du voisin le plus proche
- CH 6: Réseaux de neurones
- CH 7: Traitement du langage naturel
- CH 8: Réseaux de neurones convolutionnels
- CH 9: Réseaux de neurones récurrents
- CH 10: Prendre TensorFlow à la production
- CH 11: Plus avec Tensorflow
CH 1: commencer avec Tensorflow
Ce chapitre a l'intention d'introduire les principaux objets et concepts dans TensorFlow. Nous présentons également comment accéder aux données du reste du livre et fournissons des ressources supplémentaires pour en savoir plus sur TensorFlow.
- Aperçu général des algorithmes TF
- Ici, nous introduisons TensorFlow et le contour général de la façon dont la plupart des algorithmes TensorFlow fonctionnent.
- Créer et utiliser des tenseurs
- Comment créer et initialiser les tenseurs dans TensorFlow. Nous décrivons également comment ces opérations apparaissent dans Tensorboard.
- En utilisant des variables et des espaces réservés
- Comment créer et utiliser des variables et des espaces réservés dans TensorFlow. Nous décrivons également comment ces opérations apparaissent dans Tensorboard.
- Travailler avec des matrices
- Comprendre comment TensorFlow peut fonctionner avec les matrices est crucial pour comprendre le fonctionnement des algorithmes.
- Déclaration des opérations
- Comment utiliser diverses opérations mathématiques dans TensorFlow.
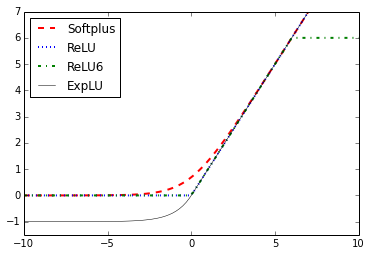
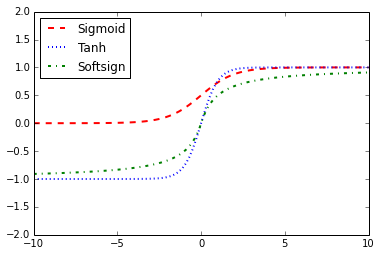
- Implémentation de fonctions d'activation
- Les fonctions d'activation sont des fonctions uniques que TensorFlow a intégrées pour votre utilisation dans les algorithmes.
- Travailler avec des sources de données
- Ici, nous montrons comment accéder à toutes les différentes sources de données requises dans le livre. Il existe également des liens décrivant les sources de données et d'où elles viennent.
- Ressources supplémentaires
- Principalement des ressources et des papiers officiels. Les articles sont des articles TensorFlow ou des ressources d'apprentissage en profondeur.
CH 2: la manière TensorFlow

Après avoir établi les objets et méthodes de base dans TensorFlow, nous voulons maintenant établir les composants qui composent les algorithmes TensorFlow. Nous commençons par introduire des graphiques de calcul, puis nous passons aux fonctions de perte et à la propagation du dos. Nous terminons par la création d'un classificateur simple, puis montrons un exemple d'évaluation des algorithmes de régression et de classification.
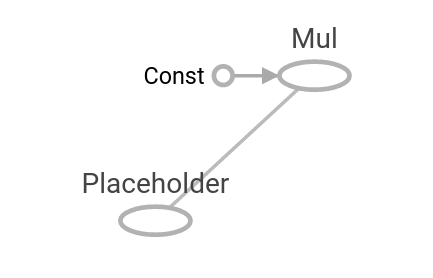
- Une opération comme graphique de calcul
- Nous montrons comment créer une opération sur un graphique de calcul et comment le visualiser à l'aide de Tensorboard.
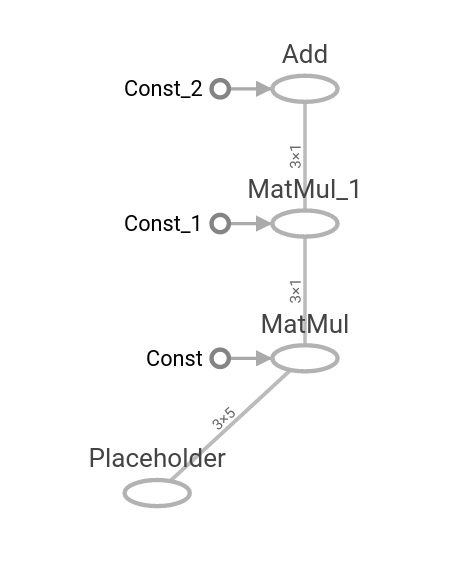
- Superposer des opérations imbriquées
- Nous montrons comment créer plusieurs opérations sur un graphique de calcul et comment les visualiser à l'aide de Tensorboard.
- Travailler avec plusieurs couches
- Ici, nous étendons l'utilisation du graphique de calcul pour créer plusieurs couches et montrer comment ils apparaissent dans Tensorboard.
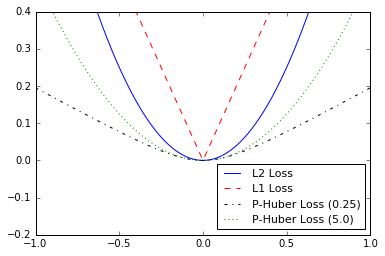
- Implémentation de fonctions de perte
- Afin de former un modèle, nous devons être en mesure d'évaluer à quel point il va bien. Ceci est donné par les fonctions de perte. Nous complotons diverses fonctions de perte et parlons des avantages et des limites de certains.
- Implémentation de la propagation du dos
- Ici, nous montrons comment utiliser les fonctions de perte pour parcourir les données et les erreurs de propagation de dos pour la régression et la classification.
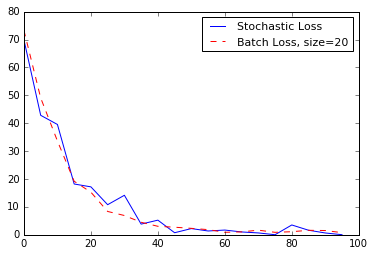
- Travailler avec une formation stochastique et par lots
- TensorFlow facilite l'utilisation de l'entraînement par lots et stochastiques. Nous montrons comment mettre en œuvre les deux et parler des avantages et des limites de chacun.
- Combiner tout ensemble
- Nous combinons maintenant tout ensemble que nous avons appris et créons un classificateur simple.
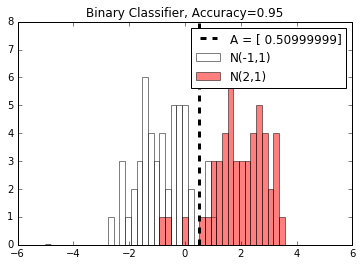
- Évaluation des modèles
- Tout modèle est aussi bon que son évaluation. Ici, nous montrons deux exemples de (1) évaluant un algorithme de régression et (2) un algorithme de classification.
CH 3: régression linéaire
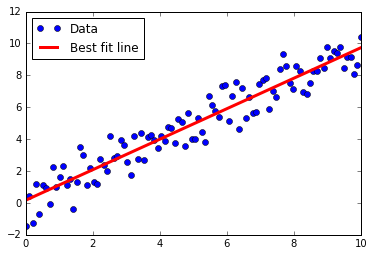
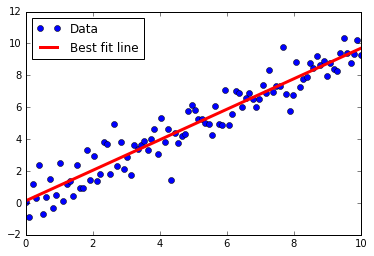
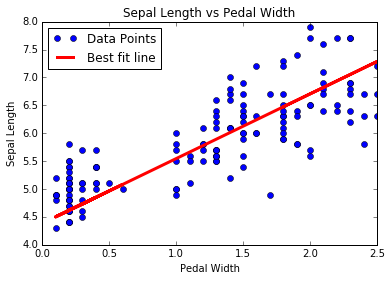
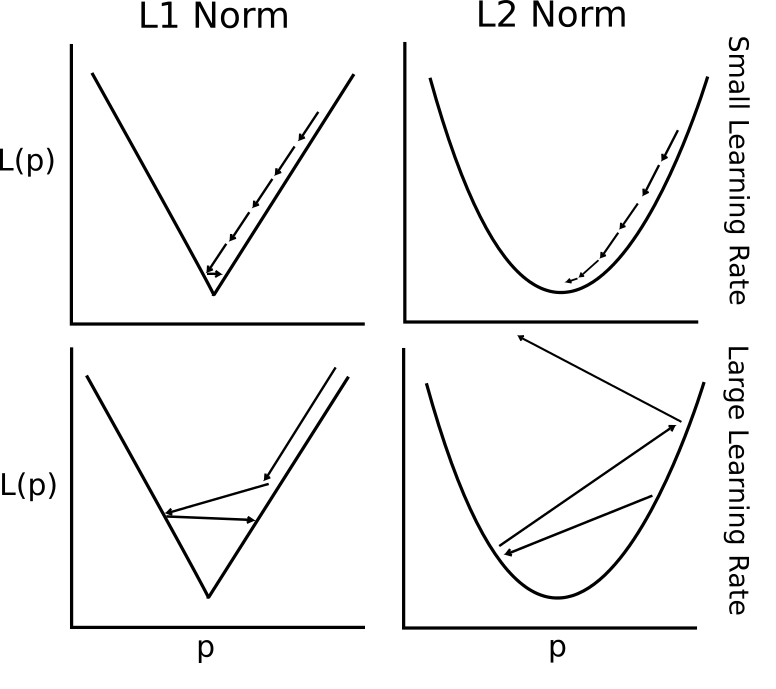
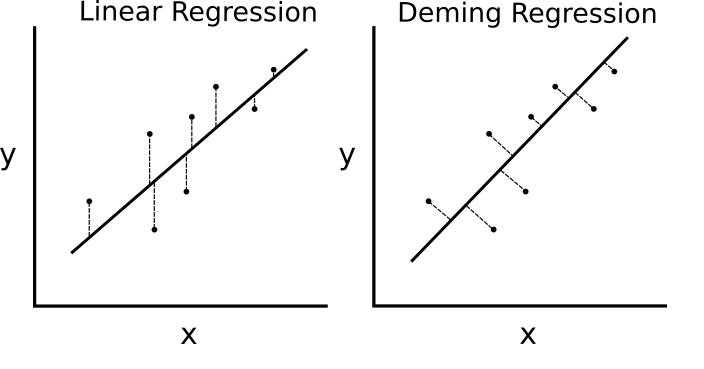
Ici, nous montrons comment implémenter diverses techniques de régression linéaire dans TensorFlow. Les deux premières sections montrent comment faire la résolution de régression linéaire de la matrice standard dans TensorFlow. Les six sections restantes montrent comment implémenter différents types de régression à l'aide de graphiques de calcul dans TensorFlow.
- En utilisant la méthode inverse de la matrice
- Comment résoudre une régression 2D avec une matrice inverse dans TensorFlow.
- Implémentation d'une méthode de décomposition
- Résolution d'une régression linéaire 2D avec décomposition de Cholesky.
- Apprendre la manière TensorFlow de la régression linéaire
- Régression linéaire itérant à travers un graphique de calcul avec une perte de L2.
- Comprendre les fonctions de perte en régression linéaire
- L2 vs L1 Perte de régression linéaire. Nous parlons des avantages et des limites des deux.
- Mise en œuvre de la régression Deming (régression totale)
- Deming (total) régression implémentée dans TensorFlow en modifiant la fonction de perte.
- Mise en œuvre de la régression de Lasso et Ridge
- La régression du lasso et de la crête est des moyens de régulariser les coefficients. Nous les implémentons dans TensorFlow en modifiant les fonctions de perte.
- Implémentation de régression nette élastique
- Le filet élastique est une technique de régularisation qui combine la perte L2 et L1 pour les coefficients. Nous montrons comment implémenter cela dans TensorFlow.
- Implémentation de régression logistique
- Nous implémentons la régression logistique par l'utilisation d'une fonction d'activation dans notre graphique de calcul.
CH 4: Machines vectorielles de support
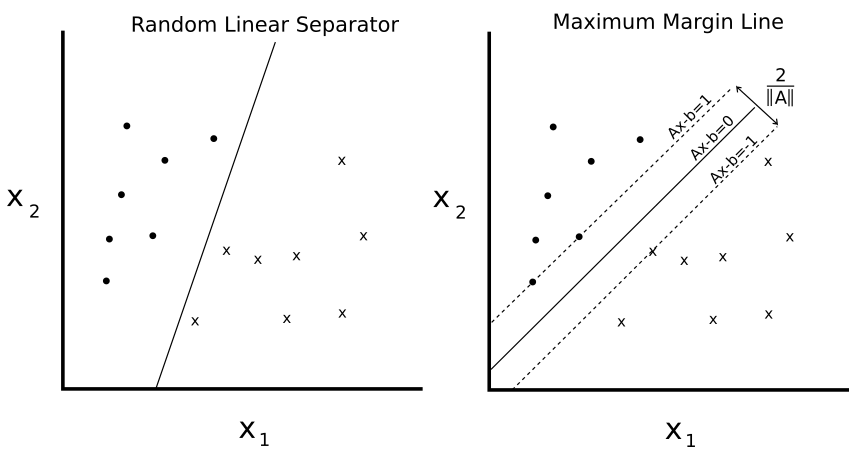
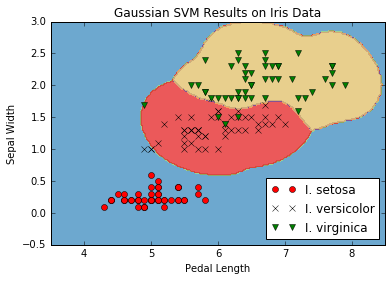
Ce chapitre montre comment implémenter diverses méthodes SVM avec TensorFlow. Nous créons d'abord un SVM linéaire et montrons également comment il peut être utilisé pour la régression. Nous introduisons ensuite les noyaux (noyau gaussien RBF) et montrons comment l'utiliser pour diviser les données non linéaires. Nous terminons avec une implémentation multidimensionnelle de SVM non linéaires pour travailler avec plusieurs classes.
- Introduction
- Nous présentons le concept de SVM et comment nous allons les implémenter dans le cadre TensorFlow.
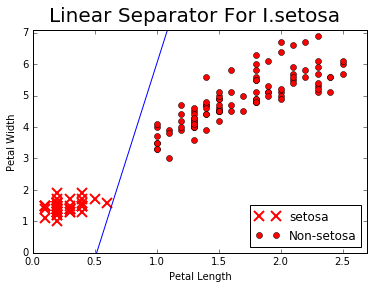
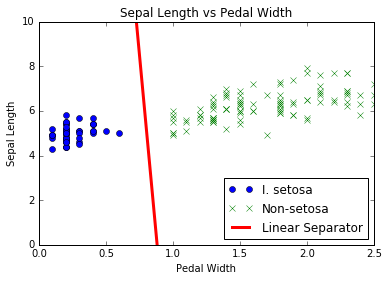
- Travailler avec des SVM linéaires
- Nous créons un SVM linéaire pour séparer I. setOSA basé sur la longueur sépale et la largeur de pédale dans l'ensemble de données de l'iris.
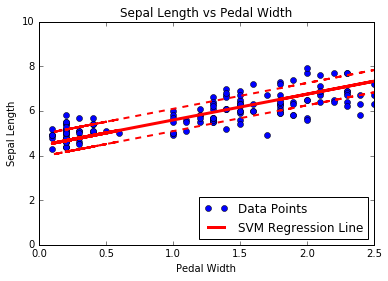
- Réduction à la régression linéaire
- Le cœur des SVMS sépare les classes avec une ligne. Nous changeons légèrement l'algorithme pour effectuer une régression SVM.
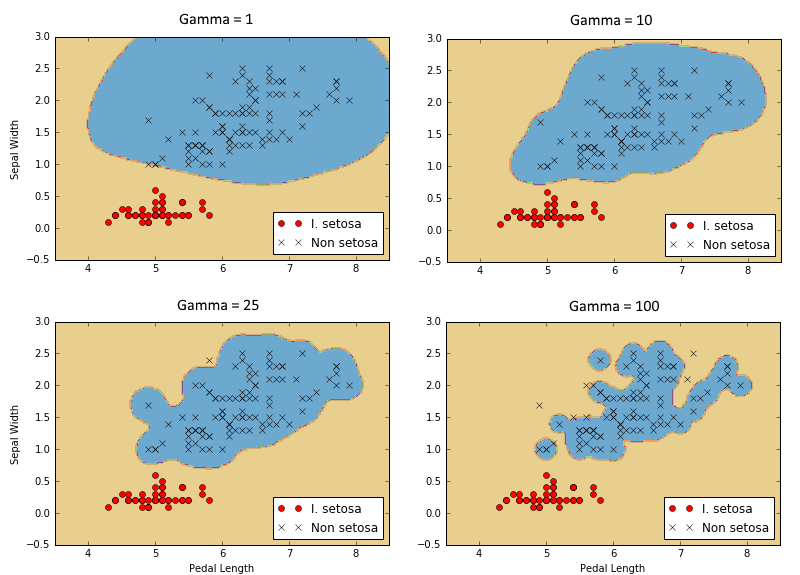
- Travailler avec les grains dans TensorFlow
- Afin d'étendre les SVM dans des données non linéaires, nous expliquons et montrons comment implémenter différents noyaux dans TensorFlow.
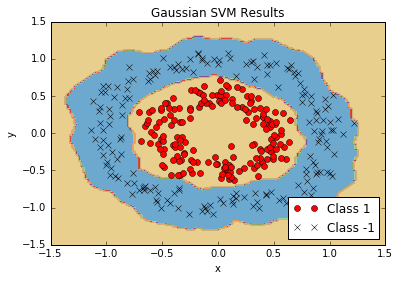
- Implémentation de SVM non linéaires
- Nous utilisons le noyau gaussien (RBF) pour séparer les classes non linéaires.
- Implémentation de SVM multi-classes
- Les SVM sont intrinsèquement des prédicteurs binaires. Nous montrons comment les étendre dans une stratégie en un VS dans TensorFlow.
CH 5: Méthodes du voisin le plus proche
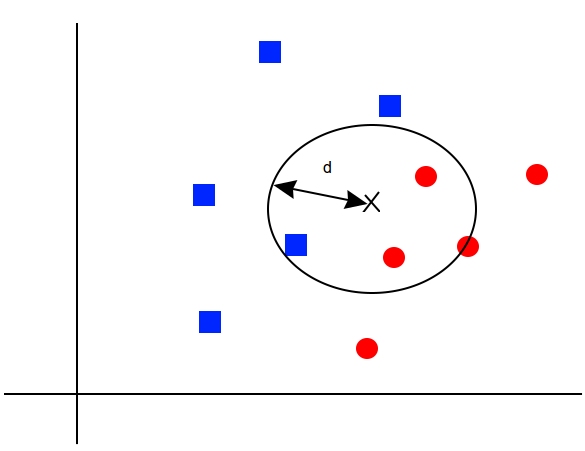
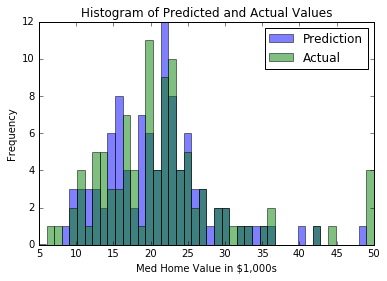



Les méthodes de voisin les plus proches sont un algorithme ML très populaire. Nous montrons comment mettre en œuvre des voisins K-Deaare les plus, des voisins les plus pondérés K-Deare les plus et des voisins K-Dearest avec des fonctions de distance mixte. Dans ce chapitre, nous montrons également comment utiliser la distance de Levenshtein (distance de modification) dans Tensorflow et l'utiliser pour calculer la distance entre les chaînes. Nous terminons ce chapitre en montrant comment utiliser les voisins K-Deaarest pour une prédiction catégorique avec la reconnaissance du chiffre manuscrit MNIST.
- Introduction
- Nous introduisons les concepts et méthodes nécessaires pour effectuer des voisins K-plus les plus nombreux de TensorFlow.
- Travailler avec des voisins les plus proches
- Nous créons un algorithme de voisin le plus proche qui essaie de prédire la valeur du logement (régression).
- Travailler avec des distances de texte
- Afin d'utiliser une fonction de distance sur le texte, nous montrons comment utiliser les distances d'édition dans TensorFlow.
- Informatique Fonctions de distance de mixage
- Ici, nous mettons en œuvre la mise à l'échelle de la fonction de distance par l'écart type de la fonction d'entrée pour les voisins K-plus les plus.
- Utilisation de la correspondance d'adresse
- Nous utilisons une fonction de distance mixte pour faire correspondre les adresses. Nous utilisons la distance numérique pour les codes postaux et la distance de modification de la chaîne pour les noms de rue. Les noms de rue sont autorisés à avoir des fautes de frappe.
- Utiliser des voisins les plus proches pour la reconnaissance d'image
- La collection d'images MNIST Digit est un excellent ensemble de données pour illustrer comment effectuer des voisins K-Deaarest pour une tâche de classification d'image.
CH 6: Réseaux de neurones


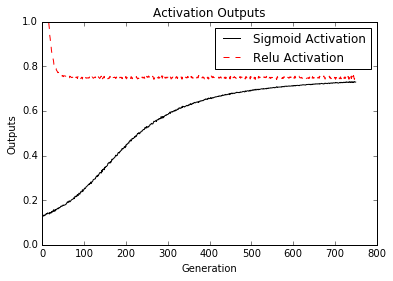

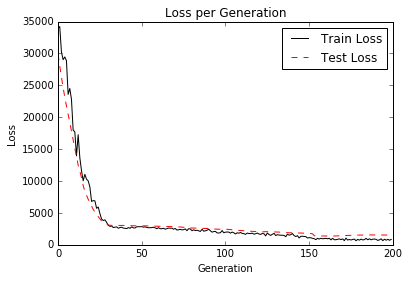
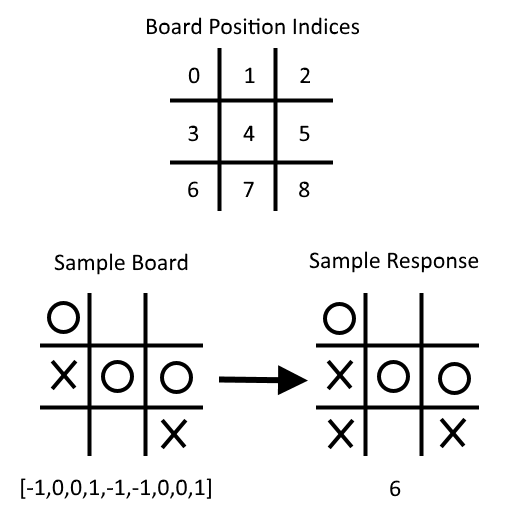
Les réseaux de neurones sont très importants dans l'apprentissage automatique et en popularité en raison des principales percées dans les problèmes antérieurs non résolus. Nous devons commencer par l'introduction de réseaux de neurones «peu profonds», qui sont très puissants et peuvent nous aider à améliorer nos résultats antérieurs d'algorithme de ML. Nous commençons par introduire l'unité NN très basique, la porte opérationnelle. Nous ajoutons progressivement de plus en plus au réseau neuronal et nous terminons par la formation d'un modèle pour jouer au tic-tac-Toe.
- Introduction
- Nous présentons le concept de réseaux de neurones et comment TensorFlow est conçu pour gérer facilement ces algorithmes.
- Mise en œuvre des portes opérationnelles
- Nous mettons en œuvre une porte opérationnelle avec une seule opération. Ensuite, nous montrons comment étendre cela à plusieurs opérations imbriquées.
- Travailler avec les portes et les fonctions d'activation
- Nous devons maintenant introduire des fonctions d'activation sur les portes. Nous montrons comment les différentes fonctions d'activation fonctionnent.
- Implémentation d'un réseau neuronal d'une couche
- Nous avons toutes les pièces pour commencer à implémenter notre premier réseau de neurones. Nous le faisons ici avec la régression sur l'ensemble de données de l'iris.
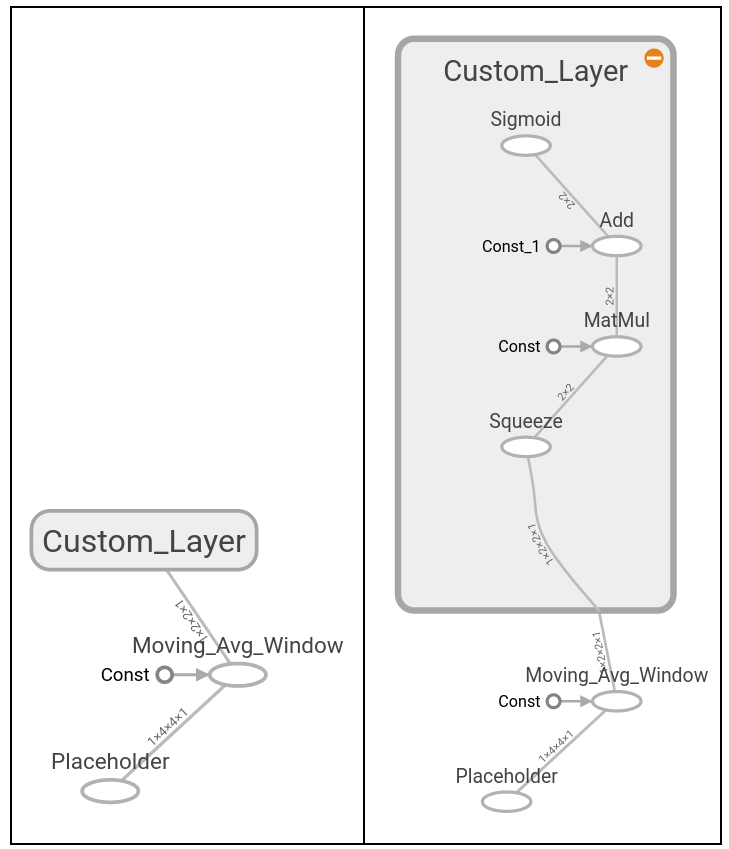
- Implémentation de différentes couches
- Cette section présente la couche de convolution et la couche max-pool. Nous montrons comment les enchaîner ensemble dans un exemple 1D et 2D avec des couches entièrement connectées.
- Utilisation de réseaux de neurones multicouches
- Ici, nous montrons comment fonctionnaliser différentes couches et variables pour un réseau neuronal multicouche plus propre.
- Amélioration des prédictions des modèles linéaires
- Nous montrons comment nous pouvons améliorer la convergence de notre régression logistique antérieure avec un ensemble de couches cachées.
- Apprendre à jouer à Tic-Tac-Toe
- Compte tenu d'un ensemble de cartes TIC-TAC-TOE et de mouvements optimaux correspondants, nous formons un modèle de classification du réseau neuronal pour jouer. À la fin du script, vous pouvez tenter de jouer contre le modèle formé.
CH 7: Traitement du langage naturel

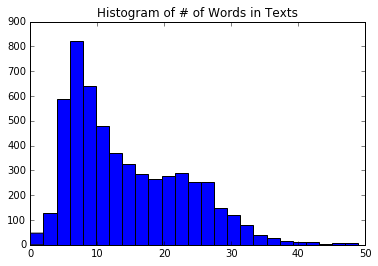
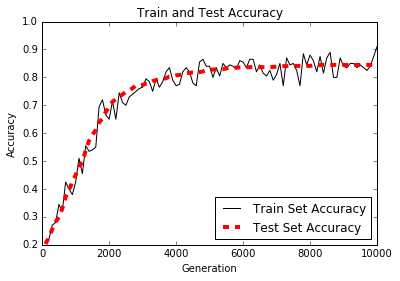
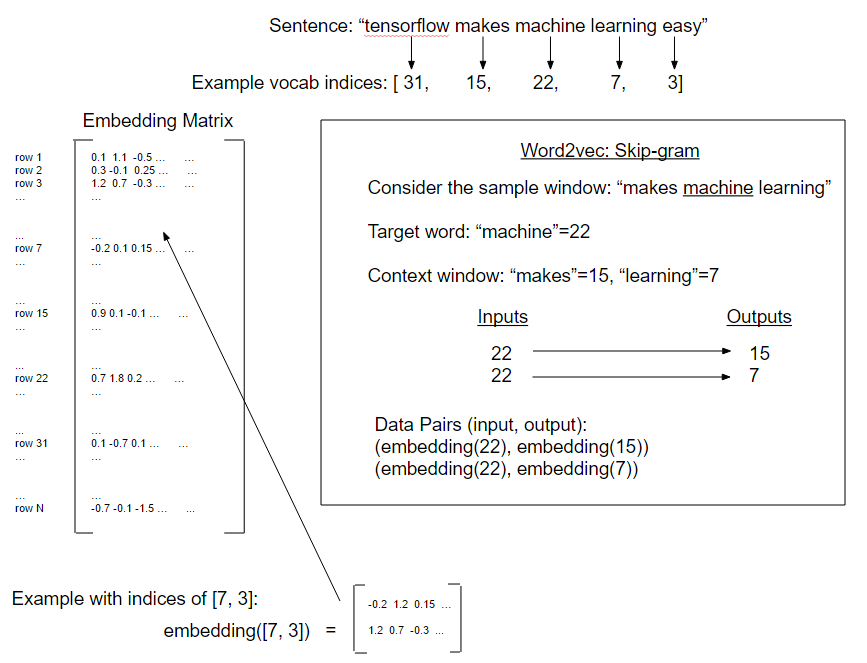

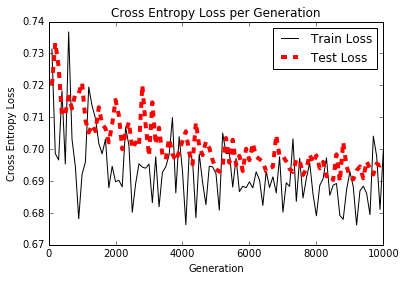
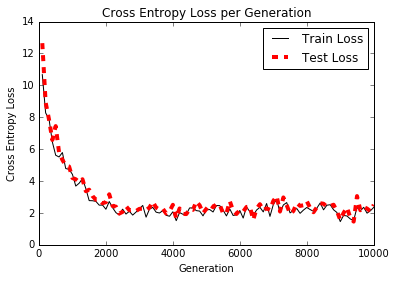
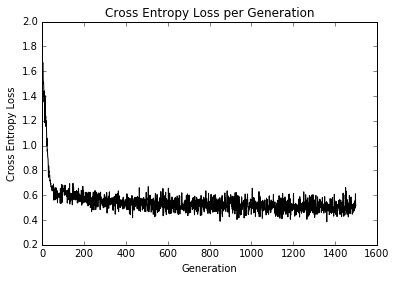
Le traitement du langage naturel (NLP) est un moyen de traiter les informations textuelles dans des résumés, des fonctionnalités ou des modèles numériques. Dans ce chapitre, nous motivons et expliquerons comment gérer au mieux le texte dans TensorFlow. Nous montrons comment implémenter les `` sacs de mots '' classiques et montrer qu'il peut y avoir de meilleures façons d'incorporer du texte en fonction du problème à accomplir. Il existe des intégres de réseau neuronal appelé Word2Vec (CBOW et SKIP-Gram) et DOC2VEC. Nous montrons comment implémenter tous ces éléments dans TensorFlow.
- Introduction
- Nous introduisons des méthodes pour transformer le texte en vecteurs numériques. Nous introduisons également la fonctionnalité TensorFlow «Embedding».
- Travailler avec un sac de mots
- Ici, nous utilisons TensorFlow pour faire un codage à un hot de mots appelés sac de mots. Nous utilisons cette méthode et cette régression logistique pour prédire si un message texte est un spam ou un jambon.
- Implémentation de TF-IDF
- Nous implémentons la fréquence du texte - Fréquence de documents inverses (TFIDF) avec une combinaison de Sci-Kit Learn et TensorFlow. Nous effectuons une régression logistique sur les vecteurs TFIDF pour améliorer nos prévisions de messagerie de texte spam / jambon.
- Travailler avec Skip-Gram
- Notre première implémentation de Word2Vec a appelé "Skip-Gram" sur une base de données de revue de films.
- Travailler avec CBOW
- Ensuite, nous mettons en œuvre une forme de Word2Vec appelée "CBOW" (sac continu de mots) sur une base de données de revue de films. Nous introduisons également la méthode pour enregistrer et charger des incorporations de mots.
- Implémentation d'exemple Word2Vec
- Dans cet exemple, nous utilisons les incorporations de mots cbow enregistrés antérieurs pour améliorer notre régression logistique TF-IDF du sentiment de la revue de film.
- Effectuer une analyse des sentiments avec doc2vec
- Ici, nous introduisons une méthode DOC2VEC (concaténation des intégres DOC et Word) pour améliorer le modèle logistique du sentiment de revue de films.
CH 8: Réseaux de neurones convolutionnels
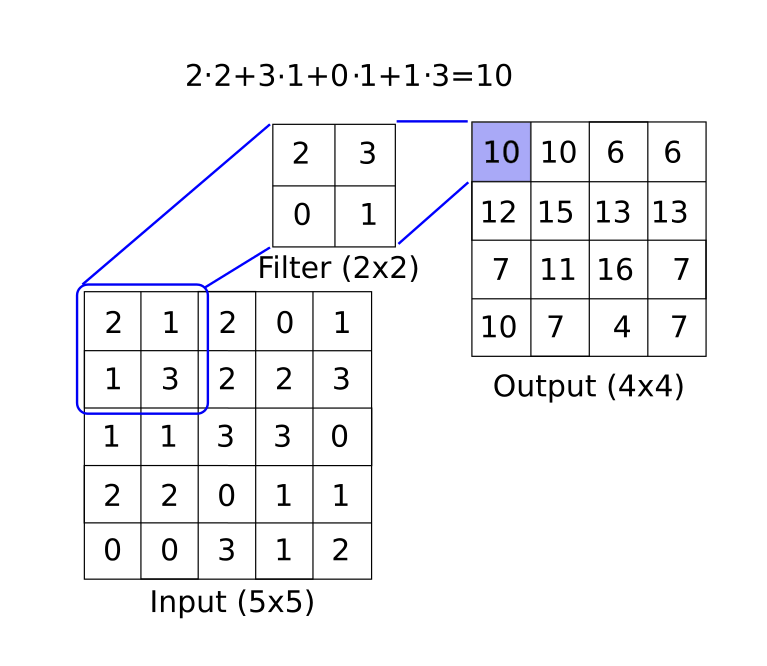




Les réseaux de neurones convolutionnels (CNN) sont des moyens d'amener les réseaux de neurones à gérer les données d'image. CNN dérive leur nom de l'utilisation d'une couche convolutionnelle qui applique un filtre de taille fixe sur une image plus grande, reconnaissant un motif dans n'importe quelle partie de l'image. Il existe de nombreux autres outils qu'ils utilisent (Pooling max, décrocheur, etc ...) que nous montrons comment implémenter avec TensorFlow. Nous montrons également comment recycler une architecture existante et aller plus loin avec CNNS avec Stylenet et Deep Dream.
- Introduction
- Nous introduisons les réseaux de neurones convolutionnels (CNN) et comment nous pouvons les utiliser dans TensorFlow.
- Implémentation d'un CNN simple.
- Ici, nous montrons comment créer une architecture CNN qui fonctionne bien sur la tâche de reconnaissance du chiffre MNIST.
- Implémentation d'un CNN avancé.
- Dans cet exemple, nous montrons comment reproduire une architecture pour la tâche de reconnaissance d'image CIFAR-10.
- Recycler une architecture existante.
- Nous montrons comment télécharger et configurer les données CIFAR-10 pour le didacticiel de recyclage / affinement TensorFlow.
- Utilisation de stylenet / neuralstyle.
- Dans cette recette, nous montrons une implémentation de base de l'utilisation de StyleNet ou du NeuralStyle.
- Implémentation de Dreed Dream.
- Ce script montre une explication ligne par ligne du tutoriel Deepdream de TensorFlow. Tiré de Deepdream sur Tensorflow. Notez que le code ici est converti en Python 3.
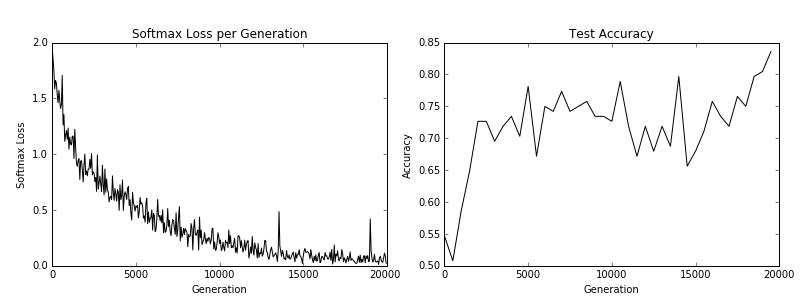
CH 9: Réseaux de neurones récurrents
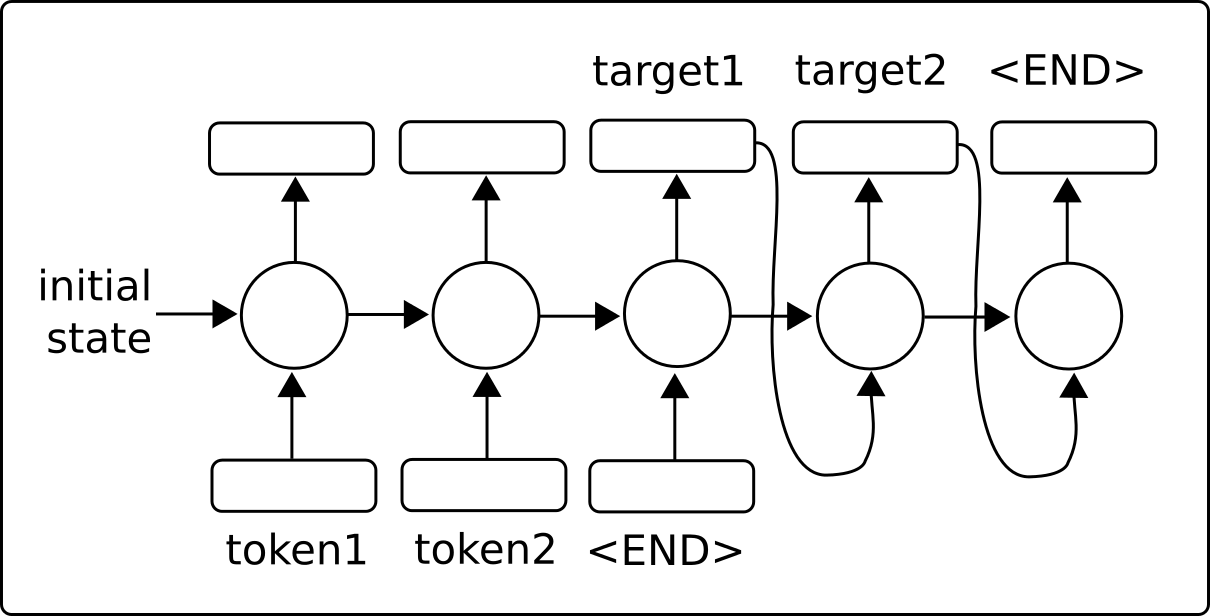
Les réseaux de neurones récurrents (RNN) sont très similaires aux réseaux de neurones réguliers, sauf qu'ils permettent des connexions «récurrentes» ou des boucles qui dépendent des états antérieurs du réseau. Cela permet aux RNN de gérer efficacement les données séquentielles, tandis que d'autres types de réseaux ne le peuvent pas. Nous motivons ensuite l'utilisation des réseaux LSTM (longue mémoire à court terme) comme moyen de résoudre les problèmes RNN réguliers. Ensuite, nous montrons à quel point il est facile d'implémenter ces types RNN dans TensorFlow.
- Introduction
- Nous introduisons des réseaux de neurones récurrents et comment ils sont capables de se nourrir dans une séquence et de prédire soit une cible fixe (catégorielle / numérique) ou une autre séquence (séquence à la séquence).
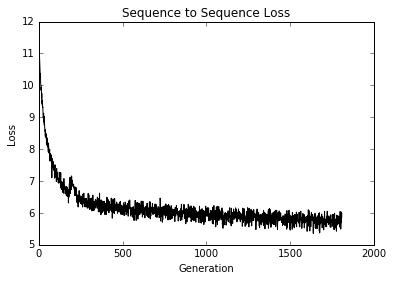
- Implémentation d'un modèle RNN pour la prédiction du spam
- Dans cet exemple, nous créons un modèle RNN pour améliorer nos prédictions de texte SPAM / HAM SMS.
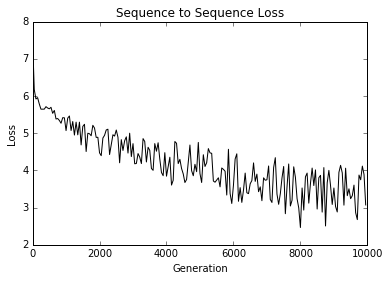
- Implémentation d'un modèle LSTM pour la génération de texte
- Nous montrons comment implémenter un RNN LSTM (long terme à court terme) pour la génération de langage Shakespeare. (Vocabulaire de niveau de mot)
- Empiler plusieurs couches LSTM
- Nous empilons plusieurs couches LSTM pour améliorer notre génération de langage Shakespeare. (Vocabulaire au niveau du caractère)
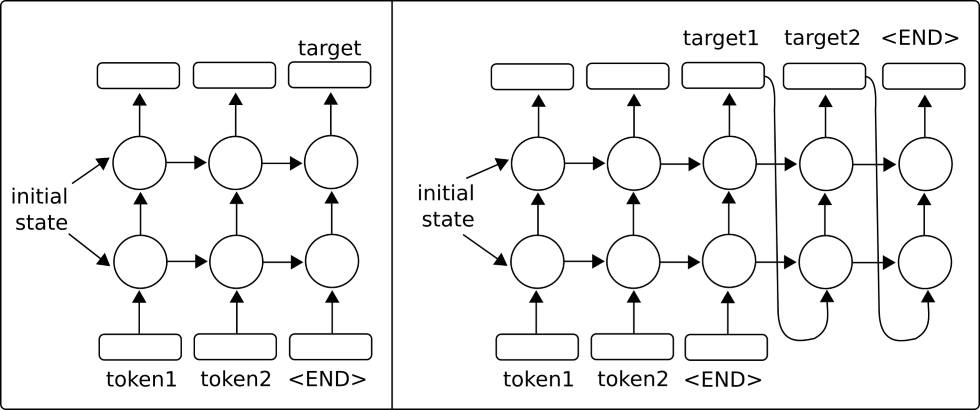
- Création d'un modèle de traduction de séquence à la séquence (SEQ2SEQ)
- Ici, nous utilisons les modèles de séquence à séquence de Tensorflow pour former un modèle de traduction anglaise-allemand.
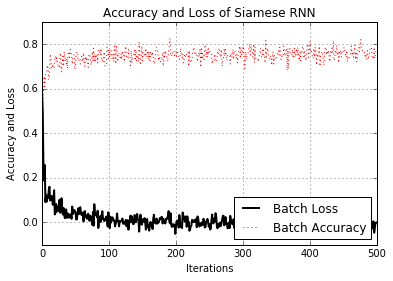
- Former une mesure de similitude siamoise
- Ici, nous mettons en œuvre un RNN siamois pour prédire la similitude des adresses et l'utilisons pour la correspondance d'enregistrements. L'utilisation de RNN pour la correspondance d'enregistrements est très polyvalente, car nous n'avons pas un ensemble fixe de catégories cibles et pouvons utiliser le modèle formé pour prédire les similitudes entre de nouvelles adresses.
CH 10: Prendre TensorFlow à la production

Bien sûr, il y a plus à TensorFlow que la simple création et le montage des modèles d'apprentissage automatique. Une fois que nous avons un modèle que nous voulons utiliser, nous devons le déplacer vers l'utilisation de la production. Ce chapitre fournira des conseils et des exemples d'implémentation de tests unitaires, en utilisant plusieurs processeurs, en utilisant plusieurs machines (TensorFlow distribuée) et se terminer avec un exemple de production complet.
- Implémentation de tests unitaires
- Nous montrons comment implémenter différents types de tests unitaires sur les tenseurs (espaces réservés et variables).
- Utilisation de plusieurs exécuteurs (appareils)
- Comment utiliser une machine avec plusieurs appareils. Par exemple, une machine avec un processeur et un ou plusieurs GPU.
- Parallélisation de Tensorflow
- Comment configurer et utiliser TensorFlow distribué sur plusieurs machines.
- Conseils pour TensorFlow en production
- Divers conseils pour se développer avec TensorFlow
- Un exemple de production de tensorflow
- Nous montrons comment prendre le modèle RNN pour prédire Ham / Spam (du chapitre 9, recette n ° 2) et le mettons dans deux fichiers de niveau de production: formation et évaluation.
CH 11: Plus avec Tensorflow
Pour illustrer à quel point TensorFlow est polyvalent, nous montrerons des exemples supplémentaires dans ce chapitre. Nous commençons par montrer comment utiliser l'outil de journalisation / visualiser Tensorboard. Ensuite, nous illustrons comment effectuer le clustering K-Means, utilisons un algorithme génétique et résolvons un système d'ODE.
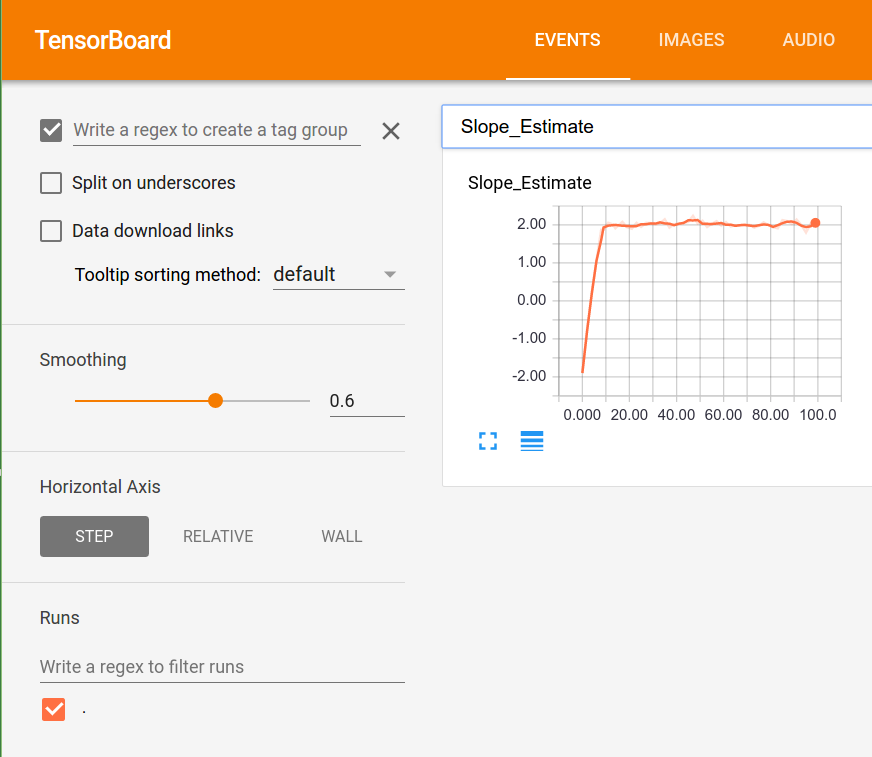
- Visualiser les graphiques de calcul (avec Tensorboard)
- Un exemple d'utilisation d'histogrammes, de résumés scalaires et de création d'images dans Tensorboard.
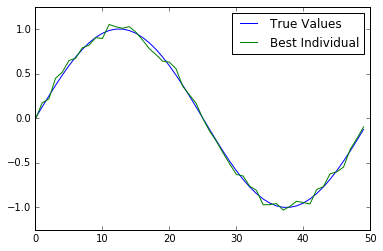
- Travailler avec un algorithme génétique
- Nous créons un algorithme génétique pour optimiser un individu (tableau de 50 nombres) vers la fonction de vérité au sol.
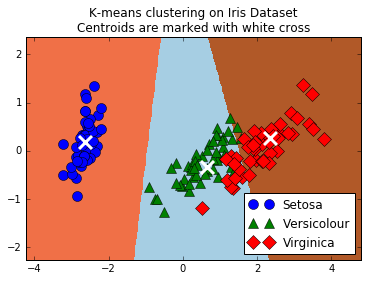
- Clustering à l'aide de k-means
- Comment utiliser TensorFlow pour faire du clustering K-means. Nous utilisons l'ensemble de données de l'iris, le jeu K = 3 et utilisons les k-means pour faire des prédictions.
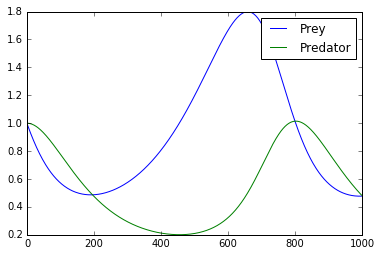
- Résoudre un système d'ODE
- Ici, nous montrons comment utiliser TensorFlow pour résoudre un système d'ODE. Le système de préoccupation est le système Lotka-Volterra Predator-Prey.
- En utilisant une forêt aléatoire
- Nous illustrons comment utiliser les arbres de régression et de classification stimulés par le gradient de Tensorflow.
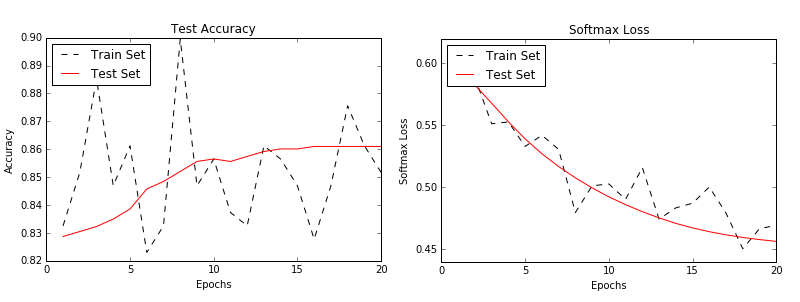
- Utilisation de TensorFlow avec Keras
- Ici, nous montrons comment utiliser le bâtiment de modèle séquentiel Keras pour un réseau neuronal entièrement connecté et un modèle CNN avec des rappels.


