manatee
1.0.0
| titre | emoji | couleur | colort | SDK | sdk_version | app_file | épinglé | licence | short_description |
|---|---|---|---|---|---|---|---|---|---|
Manatee (LM): analyse de marché basée sur les architectures de modèle de langue | ? | bleu | rouge | gradio | 4.22.0 | app.py | vrai | apache-2.0 | Analyse du marché basée sur les architectures de modèle de langue |
Ce projet se concentre sur l'utilisation de LLM pour analyser les données de séries chronologiques à des fins de prévision, sur la base du document "Chronos: Learning the Language of Time Series" de l'Amazon Web Services et des technologies d'optimisation de la chaîne d'approvisionnement d'Amazon. Le projet Manatee est conçu pour récupérer, calculer et tracer des données historiques pour les titres financiers, en tirant parti des API d'ALPACA et de la puissance des polaires et en trace pour la manipulation et la visualisation des données. Avec des fonctionnalités telles que le calcul de l'indice de résistance à la moyenne et relative (RSI), cet outil aide également à analyser les performances passées des actions et des actifs cryptographiques.
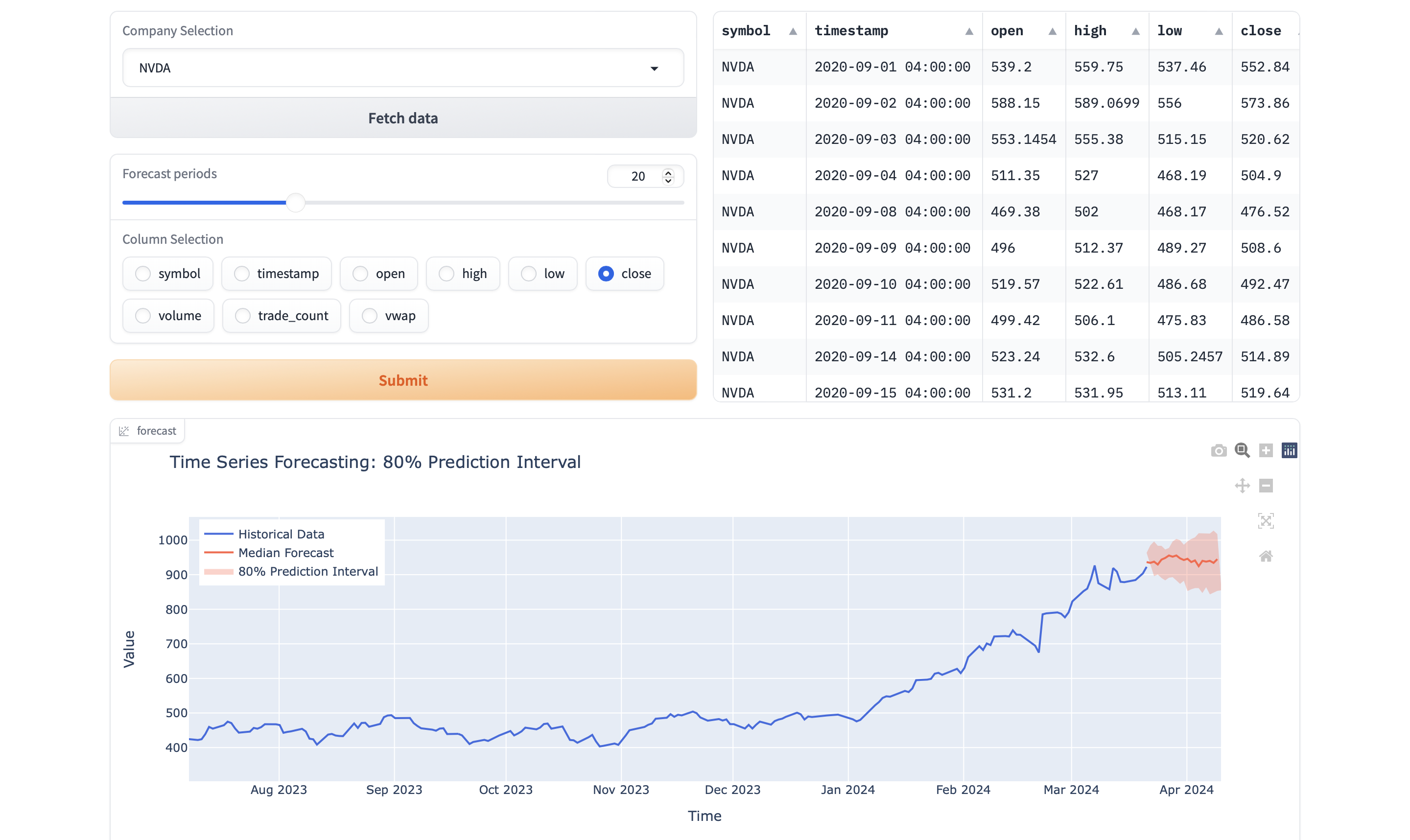
De la source:
Dans ce travail, nous prenons du recul et demandons: quelles sont les différences fondamentales entre un modèle linguistique qui prédit le token suivant et un modèle de prévision des séries chronologiques qui prédit les valeurs suivantes? Malgré la distinction apparente - les jetons d'un dictionnaire fini par rapport aux valeurs d'un domaine illimité et généralement continu - les deux s'efforcent fondamentalement de modéliser la structure séquentielle des données pour prédire les modèles futurs. Les bons modèles de langue ne devraient-ils pas «travailler» sur les séries chronologiques? Cette question naïve nous incite à remettre en question la nécessité de modifications spécifiques aux séries chronologiques, et à répondre à cela nous a conduit à développer Chronos, un cadre de modélisation de la langue à minimalement adapté pour les prévisions de séries chronologiques. Chronos Tokenise les séries chronologiques en bacs discrets grâce à une échelle simple et à une quantification des valeurs réelles. De cette façon, nous pouvons nous entraîner des modèles de langue standard sur cette «série de séries chronologiques», sans modification de l'architecture du modèle. Remarquablement, cette approche simple se révèle efficace et efficiente, soulignant le potentiel des architectures de modèle de langue pour résoudre un large éventail de problèmes de séries chronologiques avec des modifications minimales. [...]
json : une bibliothèque Python intégrée pour l'analyse des données JSON. Pas besoin d'installation.
datetime & time : Bibliothèques Python intégrées pour le traitement de la date et de l'heure. Utilisé ici pour définir des délais pour la récupération des données. Aucune installation requise.
plotly (comme px ): fournit une interface facile à utiliser à tracer, qui est utilisée pour créer des tracés interactifs. Installer via PIP:
pip3 install plotly polars (en tant que pl ): une bibliothèque Fast DataFrames idéale pour les données de séries chronologiques financières. Installer à l'aide de PIP:
pip3 install polars alpaca-py : une bibliothèque Python pour l'API Alpaca. Il donne accès aux données historiques des actions / crypto et des opérations de trading. Installer à l'aide de PIP:
pip3 install alpaca-trade-apiPour installer toutes les dépendances, vous pouvez utiliser la commande suivante:
pip3 install plotly polars alpaca-py transformers gradio spacesRemarque: Assurez-vous que Python soit installé sur votre système avant de procéder à l'installation de ces bibliothèques.
Gestion des clés de l'API : Pour des raisons de sécurité, évitez le codage en dur de vos touches API dans le script. Envisagez d'utiliser des variables d'environnement ou un service de coffre-fort sécurisé.
Confidentialité des données : lors de la gestion des données financières, il est crucial de se conformer aux réglementations de protection des données (telles que le RGPD, CCPA). Assurez-vous d'avoir le droit d'utiliser et de partager les données obtenues via cet outil.
Gestion des erreurs : le script comprend la gestion des erreurs de base, mais pour une utilisation en production, envisagez d'implémenter des blocs d'essai plus complets pour gérer les erreurs de réseau, les exceptions de limite API et les incohérences de données.
Considérations de traçage : cet outil utilise parce que la visualisation, qui est très polyvalente mais peut être à forte intensité de ressources pour les grands ensembles de données. Pour analyser de grands ensembles de données, pensez à créer des parcelles avec moins de points de données ou à agréger les données avant de tracer.
Gestion des ressources : Lorsque vous traitez de grands ensembles de données ou de nombreuses demandes d'API, surveillez l'utilisation de votre système et de votre API pour éviter la surcharge.
Contrôle de la version : mettez régulièrement à jour vos dépendances. Les API financières et les bibliothèques de traitement des données évoluent et les tenir à jour peut améliorer la sécurité, l'efficacité et l'accessibilité des nouvelles fonctionnalités.
Si vous utilisez ce code dans votre recherche, veuillez utiliser l'entrée Bibtex suivante.
@misc { louisbrulenaudet2023 ,
author = { Louis Brulé Naudet } ,
title = { MANATEE(lm) : Market Analysis based on language model architectures } ,
howpublished = { url{https://huggingface.co/spaces/louisbrulenaudet/manatee} } ,
year = { 2024 }
}
Si vous avez des commentaires, veuillez contacter à [email protected].


