conversational agent langchain
Basic Updates
Il s'agit d'un repos pour un agent conversationnel, qui permet des documents intégrés, de les rechercher à l'aide de la recherche sémantique, à QA en fonction des documents et de faire du traitement des documents avec des modèles de langues importants.
À l'heure actuelle, je retravaille à Langgraph, donc toutes les versions sur Main ne fonctionneront pas avec tous les fournisseurs. Je mettrai à jour les fournisseurs dans les prochaines semaines. Veuillez utiliser les versions pour obtenir une version de travail.
Si vous souhaitez utiliser un backend Aleph Alpha, je recommanderais mon autre backend: https://github.com/mfmezger/aleph-alpha-rag.
Pour exécuter le système complet avec Docker, utilisez cette commande:
git clone https://github.com/mfmezger/conversational-agent-langchain.git
cd conversational-agent-langchainCréez un fichier .env à partir du Template .env et définissez la touche API QDRANT. Pour les tests, définissez-le pour tester. Qdrant_api_key = "test"
Puis démarrez le système avec
docker compose up -dEnsuite, allez sur http://127.0.0.1:8001/docs ou http://127.0.0.1:8001/redoc pour voir la documentation de l'API.
Frontend: LocalHost: 8501 QDRANT Dash Toard: LocalHost: 6333 / Tableau de bord
Ce projet est un agent conversationnel qui utilise des modèles Aleph Alpha et Openai en grande langue pour générer des réponses aux requêtes utilisateur. L'agent comprend également une base de données vectorielle et une API REST construite avec FastAPI.
Caractéristiques
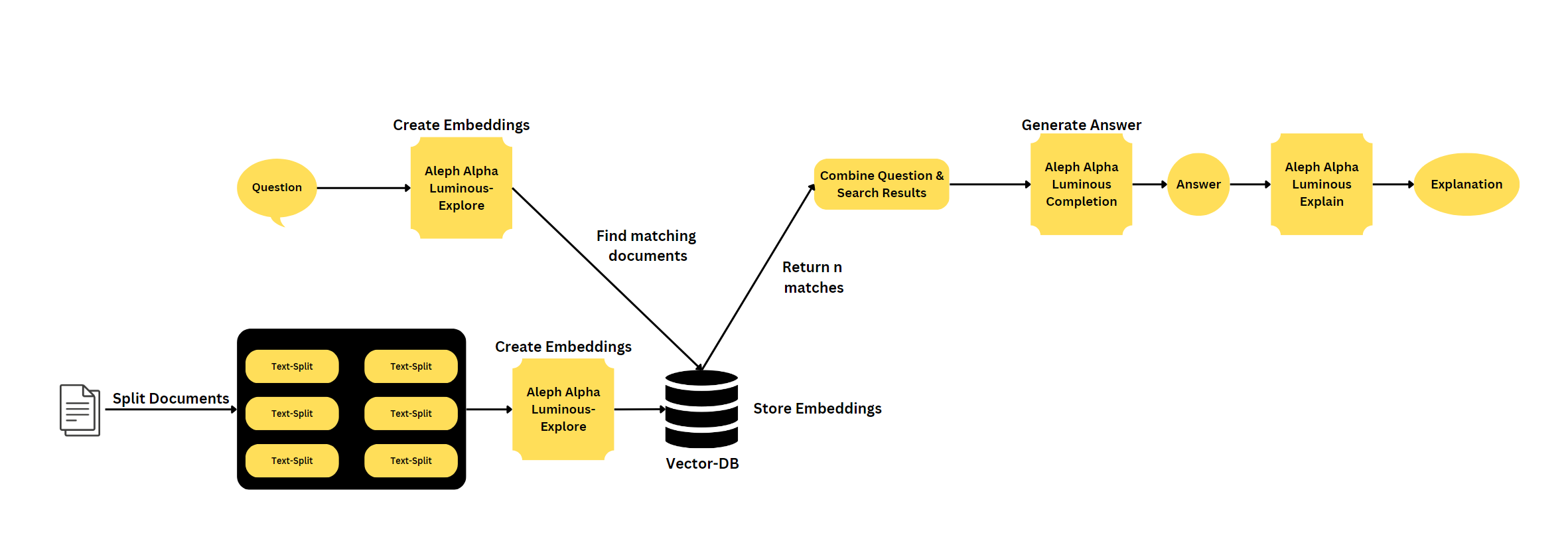
La recherche sémantique est une technique de recherche avancée qui vise à comprendre le sens et le contexte de la requête d'un utilisateur, plutôt que de correspondre aux mots clés. Il implique le traitement du langage naturel (NLP) et les algorithmes d'apprentissage automatique pour analyser et interpréter l'intention des utilisateurs, les synonymes, les relations entre les mots et la structure du contenu. En considérant ces facteurs, la recherche sémantique améliore la précision et la pertinence des résultats de recherche, offrant une expérience utilisateur plus intuitive et personnalisée.
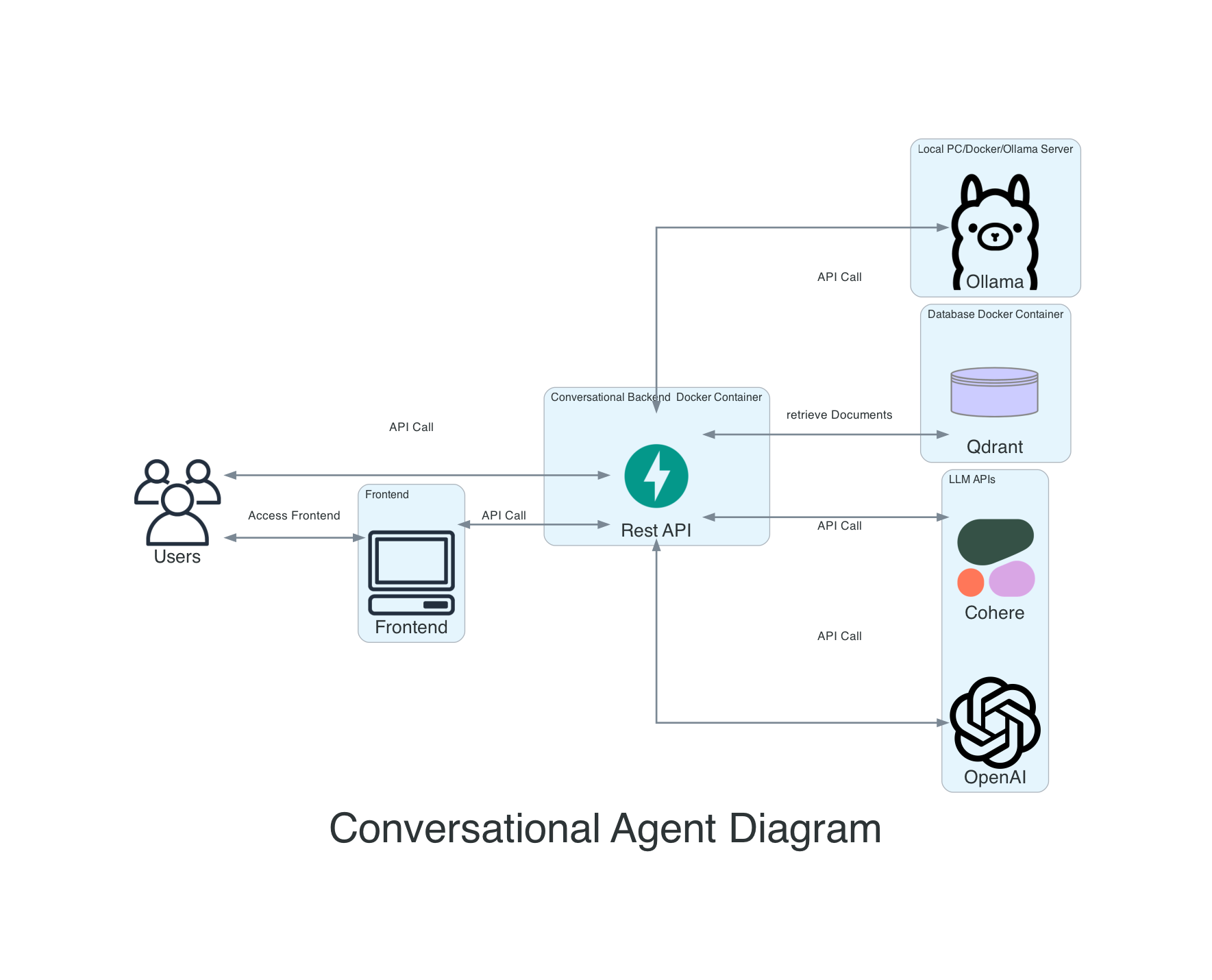
Langchain est une bibliothèque pour le traitement du langage naturel et l'apprentissage automatique. Fastapi est un cadre Web moderne et rapide (haute performance) pour la création d'API avec Python 3.7+ basé sur des conseils de type Python standard. Une Vectordatabase est une base de données qui stocke les vecteurs, qui peuvent être utilisés pour des recherches de similitude et d'autres tâches d'apprentissage automatique.
Deux façons de gérer vos clés API sont disponibles, l'approche la plus simple consiste à envoyer le jeton API dans la demande en tant que jeton. Une autre possibilité consiste à créer un fichier .env et à y ajouter le jeton API. Si vous utilisez Openai à partir d'Azure ou OpenAI directement, vous devez définir les paramètres corrects dans le fichier .env.
Sur Linux ou Mac, vous devez ajuster votre fichier / etc / hosts pour inclure la ligne suivante:
127.0.0.1 qdrantInstallez d'abord les dépendances Python:
Vous devez installer le seigle si vous souhaitez l'utiliser pour synchroniser le fichier required.lock. Installation de seigle.
rye sync
# or if you do not want to use rye
pip install -r requirements.lockDémarrez le système complet avec:
docker compose up -dPour exécuter la base de données QDRANT locale, il suffit d'exécuter:
docker compose up qdrantPour exécuter le backend, utilisez cette commande dans le répertoire racine:
poetry run uvicorn agent.api:app --reloadPour exécuter les tests, vous pouvez utiliser cette commande:
poetry run coverage run -m pytest -o log_cli=true -vvv testsPour exécuter le frontend, utilisez cette commande dans le répertoire racine:
poetry run streamlit run gui.py --theme.base= " dark "Mypy Rag - Explicit-Package-Bases
Le tableau de bord Qdrant est disponible sur http://127.0.0.1:6333/dashboard. Là, vous devez entrer la clé API.
Pour utiliser l'API QDRANT, vous devez définir les paramètres corrects dans le fichier .env. QDRANT_API_KEY est la clé API de l'API QDRANT. Et vous devez le modifier dans le fichier QDrant.yaml dans le dossier Configuration.
Si vous souhaitez ingérer une grande quantité de données, je vous recommande d'utiliser les scripts situés dans l'agent / l'ingestion.
Pour tester l'API, je recommanderais Bruno. Les demandes de l'API sont Store dans le dossier ConvengentBruno.


