AI Data Analysis MultiAgent
1.0.0
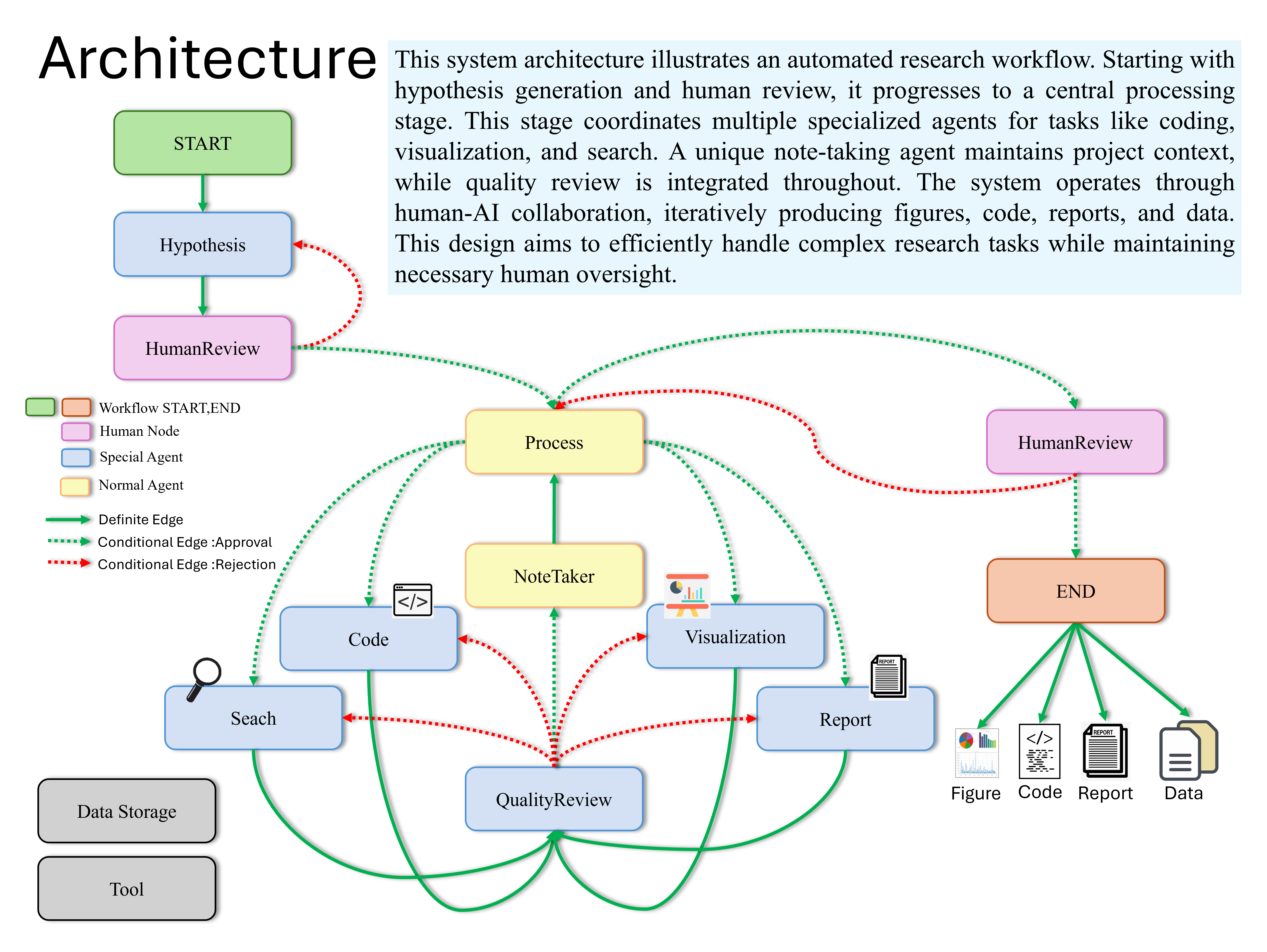
Il s'agit d'un système d'assistant de recherche avancé alimenté par l'IA qui utilise plusieurs agents spécialisés pour aider à des tâches telles que l'analyse des données, la visualisation et la génération de rapports. Le système utilise Langchain, les modèles GPT d'Openai et Langgraph pour gérer les processus de recherche complexes, intégrant diverses architectures d'IA pour des performances optimales.
L'intégration d'un agent de notes dédié distingue ce système des pipelines d'analyse de données traditionnels. En maintenant un enregistrement concis mais complet de l'état du projet, le système peut:
git clone https://github.com/starpig1129/ai-data-analysis-MulitAgent.gitconda create -n data_assistant python=3.10
conda activate data_assistantpip install -r requirements.txt.env Example à .env et remplir toutes les valeurs # Your data storage path(required)
DATA_STORAGE_PATH =./data_storage/
# Anaconda installation path(required)
CONDA_PATH = /home/user/anaconda3
# Conda environment name(required)
CONDA_ENV = envname
# ChromeDriver executable path(required)
CHROMEDRIVER_PATH =./chromedriver-linux64/chromedriver
# Firecrawl API key (optional)
# Note: If this key is missing, query capabilities may be reduced
FIRECRAWL_API_KEY = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
# OpenAI API key (required)
# Warning: This key is essential; the program will not run without it
OPENAI_API_KEY = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
# LangChain API key (optional)
# Used for monitoring the processing
LANGCHAIN_API_KEY = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXDémarrer le cahier Jupyter:
Définissez YourDataname.csv dans Data_Storage
Ouvrez le fichier main.ipynb .
Exécutez toutes les cellules pour initialiser le système et créer le flux de travail.
Dans la dernière cellule, vous pouvez personnaliser la tâche de recherche en modifiant la variable userInput .
Exécutez les dernières cellules pour exécuter le processus de recherche et afficher les résultats.
hypothesis_agent : génère des hypothèses de rechercheprocess_agent : supervise l'ensemble du processus de recherchevisualization_agent : crée des visualisations de donnéescode_agent : écrit le code d'analyse des donnéessearcher_agent : mène des recherches sur la littérature et le Webreport_agent : écrit des rapports de recherchequality_review_agent : effectue des critiques de qualiténote_agent : enregistre le processus de recherche Le système utilise Langgraph pour créer un graphique d'état qui gère l'ensemble du processus de recherche. Le flux de travail comprend les étapes suivantes:
Vous pouvez personnaliser le comportement du système en modifiant la création d'agent et la définition du flux de travail dans main.ipynb .
Les demandes de traction sont les bienvenues. Pour les changements majeurs, veuillez d'abord ouvrir un problème pour discuter de ce que vous souhaitez changer.
Ce projet est autorisé en vertu de la licence MIT - voir le fichier de licence pour plus de détails.
Voici quelques-uns de mes autres projets notables:
SharelMAPI est une API de partage de modèle de langue locale qui utilise FastAPI pour fournir des interfaces, permettant à différents programmes ou appareil de partager le même modèle local, réduisant ainsi la consommation de ressources. Il prend en charge la génération de streaming et diverses méthodes de configuration du modèle.
Un puissant bot de discorde basé sur des modèles multimodaux de grande langue (LLM), conçus pour interagir avec les utilisateurs par le langage naturel. Il combine des capacités d'IA avancées avec des caractéristiques pratiques, offrant une riche expérience pour les communautés de discorde.


