Generación de moléculas guiadas por texto con modelo de lenguaje de difusión
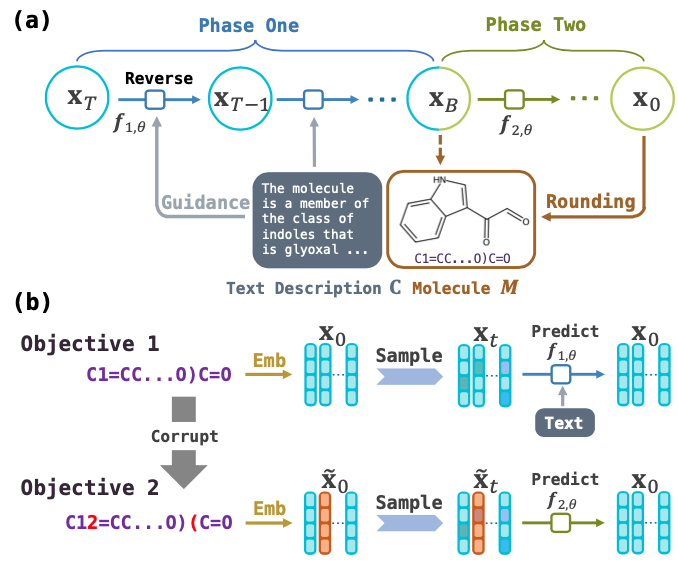
Este es el código para el documento AAAI 2024: generación de moléculas guiadas por texto con modelo de lenguaje de difusión.
Uso
Datos en papel
- Instalar el paquete
cd TGMDLMCODE; pip install -e improved-diffusion/; pip install -e transformers/ . - Descargue Scibert y póngalo en el archivo
scibert .
Capacitación
-
cd improved-diffusion; cd scripts - Codificar entrada de texto
python process_text.py -i train_val_256; python process_text.py -i test - Modelo de tren para la fase uno:
python train.py - Modelo de tren para la fase dos:
python train_correct_withmask.py
¡Los siguientes detalles son importantes para que lo sepas antes de entrenar este modelo solo!
- Para este modelo, siempre necesita más de 100,000 pasos de entrenamiento antes de muestrear para que pueda obtener un resultado normal. El rendimiento converge mucho después de la convergencia de la pérdida.
- La pérdida finalmente converge a alrededor de 0.015 (este valor depende de la cantidad de parámetros capacitables, 0.015 es para el modelo en este código. Dentro del rango razonable, mayor el modelo, menor la pérdida). Es posible que la pérdida en su experimento no converja a 0.015 (por debajo de 0.02) y se atasque a un valor alto relativo (como 0.08), le sugerimos que vuelva a ejecutar el procedimiento de entrenamiento con otra semilla aleatoria. Normalmente, la pérdida debería converger muy rápidamente a menos de 0.03 dentro de 15,000 pasos. Si su pérdida no se comporta así, solo intente otro momento :) (Gracias a @yhanjg que informa este problema)
No tenemos ninguna idea de por qué aparecerá este problema. Observé una vez que la pérdida se quedó con un alto valor, y otro investigador me alcanzó después de ejecutar mi código e informar este problema también. Este problema debe solucionarse después de que la mitad de la tasa de aprendizaje :)
Muestreo
-
python text_sample.py; python post_sample.py El archivo final OURMODEL_OUTPUT.txt es nuestra salida.
Evaluación
Puede evaluar todas las métricas, excepto Text2Mol, runnning ev.py Para Text2mol, vaya a Molt5 para obtener más detalles.
Requisitos
- python3
- Pytorch 2.0
- Transformadores (tenga cuidado de seguir la instalación de ReadMe exactamente).
Citación
Cite nuestro documento si usa el código:
@article{gong2024text,
title={Text-Guided Molecule Generation with Diffusion Language Model},
author={Gong, Haisong and Liu, Qiang and Wu, Shu and Wang, Liang},
volume={38},
url={https://ojs.aaai.org/index.php/AAAI/article/view/27761},
DOI={10.1609/aaai.v38i1.27761},
number={1},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
year={2024},
month={Mar.},
pages={109-117}
}
Reconocer
Este código se basa en https://github.com/xiangli1999/diffusion-lm y https://github.com/blender-nlp/molt5


