openai token enumeration
1.0.0
Enumeración de tokens estables
import tiktoken
import sys
# Get the encoding for cl100k_base
enc = tiktoken.get_encoding("cl100k_base")
# Specify model (e.g gpt-3.5-turbo, gpt-4)
enc = tiktoken.encoding_for_model("gpt-4")
# Output values to text file
stdoutOrigin=sys.stdout
sys.stdout = open("gpt-4.txt", "w")
# Special tokens list
# https://github.com/openai/tiktoken/blob/ec7c121e385bf1675312c6c33734de6b392890c4/tiktoken_ext/openai_public.py
special_tokens = [100257,100258,100259,100260,100276]
# Compute range of values up-to first special token
# (ie 0-100255) or range(100256)
for i in range(100256):
stdoutOrigin.write(str(enc.decode_tokens_bytes([i]))+"n")
for i in special_tokens:
stdoutOrigin.write(str(enc.decode_tokens_bytes([i]))+"n")
# Close session
stdoutOrigin.close()
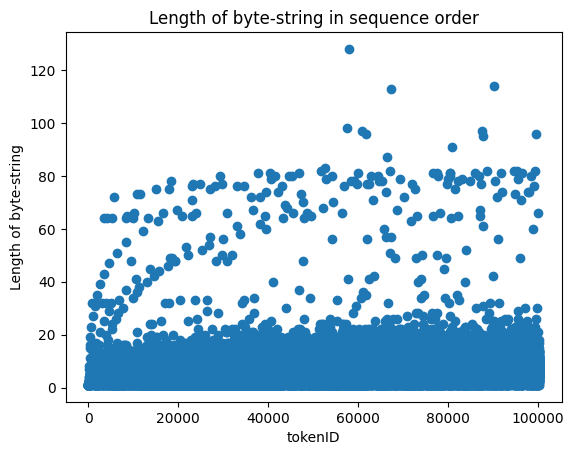
count 100261.000000
mean 6.325869
std 4.105298
min 1.000000
25% 4.000000
50% 6.000000
75% 8.000000
max 128.000000