stylegan2 pytorch
1.8.11
Implementación simple de Pytorch de StyleGan2 basada en https://arxiv.org/abs/1912.04958 que puede estar completamente entrenado desde la línea de comandos, no se necesita codificación.
A continuación hay algunas flores que no existen.
Tampoco estas manos
Ni estas ciudades
Ni estas celebridades (entrenadas por @Yoniker)
Necesitará una máquina con una GPU y CUDA instaladas. Luego Pip instale el paquete como este
$ pip install stylegan2_pytorchSi está utilizando una máquina de Windows, los siguientes comandos funcionan.
$ conda install pytorch torchvision -c python
$ pip install stylegan2_pytorch$ stylegan2_pytorch --data /path/to/images Eso es todo. Las imágenes de muestra se guardarán en results/default y los modelos se guardarán periódicamente en models/default .
Puede especificar el nombre de su proyecto con
$ stylegan2_pytorch --data /path/to/images --name my-project-nameTambién puede especificar la ubicación donde los resultados intermedios y los puntos de control del modelo deben almacenarse con
$ stylegan2_pytorch --data /path/to/images --name my-project-name --results_dir /path/to/results/dir --models_dir /path/to/models/dir Puede aumentar la capacidad de la red (que por defecto es 16 ) para mejorar los resultados de la generación, a costa de más memoria.
$ stylegan2_pytorch --data /path/to/images --network-capacity 256 Por defecto, si la capacitación se corta, se reanudará automáticamente desde el último archivo de control. Si desea reiniciar con una nueva configuración, simplemente agregue una new bandera
$ stylegan2_pytorch --new --data /path/to/images --name my-project-name --image-size 512 --batch-size 1 --gradient-accumulate-every 16 --network-capacity 10Una vez que haya terminado de entrenamiento, puede generar imágenes desde su último punto de control como SO.
$ stylegan2_pytorch --generateGenerar un video de una interpolación a través de dos puntos aleatorios en el espacio latente.
$ stylegan2_pytorch --generate-interpolation --interpolation-num-steps 100Para guardar cada marco individual de la interpolación
$ stylegan2_pytorch --generate-interpolation --save-framesSi un punto de control anterior contenía un mejor generador (que a menudo sucede a medida que los generadores comienzan a degradarse hacia el final del entrenamiento), puede cargar desde un punto de control anterior con otra bandera
$ stylegan2_pytorch --generate --load-from {checkpoint number} Una técnica utilizada tanto en Stylegan como en Biggan está truncando los valores latentes para que sus valores caigan cerca de la media. Cuanto menor sea el valor de truncamiento, mejoras aparecerán a costa de la variedad de muestras. Puede controlar esto con el --trunc-psi , donde los valores generalmente caen entre 0.5 y 1 . Se establece en 0.75 como predeterminado
$ stylegan2_pytorch --generate --trunc-psi 0.5Si tiene una máquina con múltiples GPU, el repositorio ofrece una forma de utilizarlas todas para el entrenamiento. Con múltiples GPU, cada lote se dividirá uniformemente entre las GPU disponibles. Por ejemplo, para 2 GPU, con un tamaño por lotes de 32, cada GPU verá 16 muestras.
Simplemente tiene que agregar una bandera --multi-gpus , todo lo demás se cuida. Si desea restringir a GPU específicas, puede usar la variable de entorno CUDA_VISIBLE_DEVICES para controlar qué dispositivos se pueden usar. (Ej. CUDA_VISIBLE_DEVICES=0,2,3 Solo dispositivos 0, 2, 3 están disponibles)
$ stylegan2_pytorch --data ./data --multi-gpus --batch-size 32 --gradient-accumulate-every 1En el pasado, Gans necesitaba muchos datos para aprender a generar bien. El modelo Faces tomó 70k imágenes de alta calidad de Flickr, como ejemplo.
Sin embargo, en el mes de mayo de 2020, los investigadores de todo el mundo convergieron independientemente en una técnica simple para reducir ese número a tan solo 1-2k . Esa simple idea era aumentar diferenciablemente todas las imágenes, generadas o reales, entrando en el discriminador durante el entrenamiento.
Si se aumentara con una probabilidad lo suficientemente baja, los aumentos no se 'filtrarán' a las generaciones.
En la configuración de datos bajos, puede usar la función con un indicador simple.
# find a suitable probability between 0. -> 0.7 at maximum
$ stylegan2_pytorch --data ./data --aug-prob 0.25 Por defecto, los aumentos utilizados son translation y cutout . Si desea agregar color , puede hacerlo con el argumento --aug-types .
# make sure there are no spaces between items!
$ stylegan2_pytorch --data ./data --aug-prob 0.25 --aug-types [translation,cutout,color]Puede personalizarlo a cualquier combinación de los tres que le gustaría. El código de aumento diferenciable se copió y se modificó ligeramente desde aquí.
Durante el mayor tiempo posible hasta que el juego adversario entre las dos redes neuronales se desmorone (llamamos a esto divergencia). Por defecto, el número de pasos de entrenamiento se establece en 150000 para 128x128 imágenes, pero ciertamente querrá que este número sea mayor si el GaN no diverge al final de la capacitación, o si está entrenando a una resolución más alta.
$ stylegan2_pytorch --data ./data --image-size 512 --num-train-steps 1000000Este marco también le permite agregar una forma eficiente de autoatención a las capas designadas del discriminador (y la capa simétrica del generador), que mejorará en gran medida los resultados. ¡Cuanta más atención pueda pagar, mejor!
# add self attention after the output of layer 1
$ stylegan2_pytorch - - data . / data - - attn - layers 1 # add self attention after the output of layers 1 and 2
# do not put a space after the comma in the list!
$ stylegan2_pytorch - - data . / data - - attn - layers [ 1 , 2 ]Entrenamiento en imágenes transparentes
$ stylegan2_pytorch --data ./transparent/images/path --transparentCuanta más memoria GPU tenga, más grande y mejor será la generación de imágenes. Nvidia recomendó tener hasta 16 GB para capacitar imágenes 1024x1024. Si tiene menos que eso, hay un par de configuraciones con la que puede jugar para que el modelo se ajuste.
$ stylegan2_pytorch --data /path/to/data
--batch-size 3
--gradient-accumulate-every 5
--network-capacity 16 Tamaño del lote: puede disminuir el batch-size a 1, pero debe aumentar el gradient-accumulate-every en consecuencia para que el mini lote que ve la red no es demasiado pequeño. Esto puede ser confuso para un laico, por lo que pensaré en cómo automatizaría la elección de gradient-accumulate-every en el futuro.
Capacidad de red: puede disminuir la capacidad de la red neuronal para disminuir los requisitos de memoria. Solo tenga en cuenta que se ha demostrado que esto degrada el rendimiento de la generación.
Si nada de esto funciona, puede conformarse con un ganador 'liviano', lo que le permitirá la calidad de compensación para capacitar a mayores resoluciones en un período de tiempo razonable.
A continuación hay algunos pasos que pueden ser útiles para la implementación utilizando los servicios web de Amazon. Para usar esto, tendrá que aprovisionar una instancia de EC2 respaldada por GPU. Un tipo de instancia apropiado sería de una serie P2 o P3. Yo (Iboates) probé un P2.xlarge (la opción más barata) y fue bastante lento, más lento de hecho que usar Google Colab. Los tipos de instancias más potentes pueden ser mejores, pero son más caros. Puedes leer más sobre ellos aquí.
sudo snap install aws-cli --classic
aws configureLuego deberá ingresar sus claves de acceso AWS, que puede recuperar de la consola de administración en la consola de administración de AWS> Perfil> mis credenciales de seguridad> claves de acceso
Luego, ejecute estos comandos, o tal vez póngalos en un script de shell y ejecute eso:
mkdir data
curl -O https://bootstrap.pypa.io/get-pip.py
sudo apt-get install python3-distutils
python3 get-pip.py
pip3 install stylegan2_pytorch
export PATH= $PATH :/home/ubuntu/.local/bin
aws s3 sync s3:// < Your bucket name > ~ /data
cd data
tar -xf ../train.tar.gz Ahora debería poder entrenar simplemente llamando stylegan2_pytorch [args] .
Notas:
screen para que no finalice una vez que cierre la sesión de la sesión SSH. Gracias a GetSeclectic, ¡ahora puede calcular la puntuación FID periódicamente! Nuevamente, se hizo súper simple con un argumento adicional, como se muestra a continuación.
En primer lugar, instale el paquete pytorch_fid
$ pip install pytorch-fidSeguido de
$ stylegan2_pytorch --data ./data --calculate-fid-every 5000 Los resultados de FID se registrarán ./results/{name}/fid_scores.txt
Si desea probar imágenes mediante programación, puede hacerlo con la siguiente clase simple ModelLoader .
import torch
from torchvision . utils import save_image
from stylegan2_pytorch import ModelLoader
loader = ModelLoader (
base_dir = '/path/to/directory' , # path to where you invoked the command line tool
name = 'default' # the project name, defaults to 'default'
)
noise = torch . randn ( 1 , 512 ). cuda () # noise
styles = loader . noise_to_styles ( noise , trunc_psi = 0.7 ) # pass through mapping network
images = loader . styles_to_images ( styles ) # call the generator on intermediate style vectors
save_image ( images , './sample.jpg' ) # save your images, or do whatever you desirePara registrar las pérdidas en un rastreador de experimentos de código abierto (AIM), simplemente necesita pasar una bandera adicional como así.
$ stylegan2_pytorch --data ./data --logLuego, debe asegurarse de que tenga instalado Docker. Siguiendo las instrucciones en AIM, ejecuta lo siguiente en su terminal.
$ aim upLuego abra su navegador a la dirección y debería ver
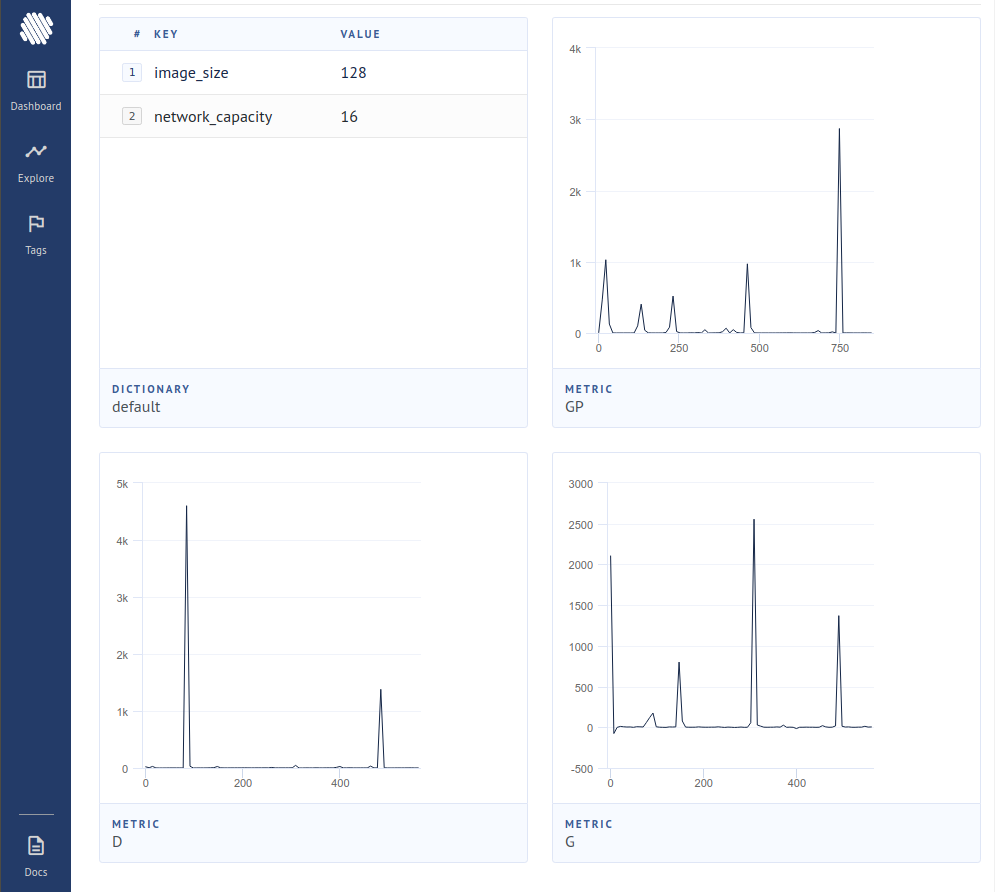
Un nuevo artículo ha producido evidencia de que al simplemente cero las contribuciones de gradiente de las muestras que el discriminador consideran falso, el generador aprende significativamente mejor, lo que alcanza la nueva estado de la técnica.
$ stylegan2_pytorch - - data . / data - - top - k - trainingGamma es un programa de descomposición que disminuye lentamente el TOPK desde el tamaño de lote completo hasta la fracción objetivo del 50% (también hiperparámetro modificable).
$ stylegan2_pytorch - - data . / data - - top - k - training - - generate - top - k - frac 0.5 - - generate - top - k - gamma 0.99 Un artículo reciente informó resultados mejorados si las representaciones intermedias del discriminador se cuantifican el vector. Aunque no he notado ningún cambio dramático, he decidido agregar esto como una característica, por lo que otras mentes pueden investigar. Para usar, debe especificar qué capa (s) le gustaría cuantizar el vector. El tamaño predeterminado del diccionario es 256 y también es sintonizable.
# feature quantize layers 1 and 2, with a dictionary size of 512 each
# do not put a space after the comma in the list!
$ stylegan2_pytorch - - data . / data - - fq - layers [ 1 , 2 ] - - fq - dict - size 512Intenté el aprendizaje contrastante sobre el discriminador (en paso con el entrenamiento de GaN habitual) y posiblemente observé una mejor estabilidad y calidad de los resultados finales. Puede activar esta característica experimental con una bandera simple como se muestra a continuación.
$ stylegan2_pytorch - - data . / data - - cl - regEsto se propuso en el papel relativista de GaN para estabilizar el entrenamiento. He tenido resultados mixtos, pero incluiré la característica para aquellos que desean experimentar con ella.
$ stylegan2_pytorch - - data . / data - - rel - disc - loss Por defecto, la arquitectura de Stylegan estiliza un bloque 4x4 constante, ya que está progresivamente muestreado. Esta es una característica experimental que lo hace, por lo que el bloque 4x4 se aprende del Vector de estilo w en su lugar.
$ stylegan2_pytorch - - data . / data - - no - constUn artículo reciente ha propuesto que una nueva pérdida contrastante entre los logits reales y falsos puede mejorar la calidad sobre otros tipos de pérdidas. (El valor predeterminado en este repositorio es la pérdida de bisagra, y el documento muestra una ligera mejora)
$ stylegan2_pytorch - - data . / data - - dual - contrast - loss Stylegan2 + discriminador de unlo
He obtenido muy buenos resultados con un discriminador unena, pero el cambio arquitectónico fue demasiado grande para encajar como una opción en este repositorio. Si apunta a la perfección, siéntase libre de probarla.
Si desea que le dé el tratamiento real a alguna otra arquitectura GaN (Biggan), no dude en comunicarse con mi correo electrónico. Feliz de escuchar tu tono.
Gracias a Matthew Mann por su inspirador puerto simple para Tensorflow 2.0
@article { Karras2019stylegan2 ,
title = { Analyzing and Improving the Image Quality of {StyleGAN} } ,
author = { Tero Karras and Samuli Laine and Miika Aittala and Janne Hellsten and Jaakko Lehtinen and Timo Aila } ,
journal = { CoRR } ,
volume = { abs/1912.04958 } ,
year = { 2019 } ,
} @misc { zhao2020feature ,
title = { Feature Quantization Improves GAN Training } ,
author = { Yang Zhao and Chunyuan Li and Ping Yu and Jianfeng Gao and Changyou Chen } ,
year = { 2020 }
} @misc { chen2020simple ,
title = { A Simple Framework for Contrastive Learning of Visual Representations } ,
author = { Ting Chen and Simon Kornblith and Mohammad Norouzi and Geoffrey Hinton } ,
year = { 2020 }
} @article {,
title = { Oxford 102 Flowers } ,
author = { Nilsback, M-E. and Zisserman, A., 2008 } ,
abstract = { A 102 category dataset consisting of 102 flower categories, commonly occuring in the United Kingdom. Each class consists of 40 to 258 images. The images have large scale, pose and light variations. }
} @article { afifi201911k ,
title = { 11K Hands: gender recognition and biometric identification using a large dataset of hand images } ,
author = { Afifi, Mahmoud } ,
journal = { Multimedia Tools and Applications }
} @misc { zhang2018selfattention ,
title = { Self-Attention Generative Adversarial Networks } ,
author = { Han Zhang and Ian Goodfellow and Dimitris Metaxas and Augustus Odena } ,
year = { 2018 } ,
eprint = { 1805.08318 } ,
archivePrefix = { arXiv }
} @article { shen2019efficient ,
author = { Zhuoran Shen and
Mingyuan Zhang and
Haiyu Zhao and
Shuai Yi and
Hongsheng Li } ,
title = { Efficient Attention: Attention with Linear Complexities } ,
journal = { CoRR } ,
year = { 2018 } ,
url = { http://arxiv.org/abs/1812.01243 } ,
} @article { zhao2020diffaugment ,
title = { Differentiable Augmentation for Data-Efficient GAN Training } ,
author = { Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song } ,
journal = { arXiv preprint arXiv:2006.10738 } ,
year = { 2020 }
} @misc { zhao2020image ,
title = { Image Augmentations for GAN Training } ,
author = { Zhengli Zhao and Zizhao Zhang and Ting Chen and Sameer Singh and Han Zhang } ,
year = { 2020 } ,
eprint = { 2006.02595 } ,
archivePrefix = { arXiv }
} @misc { karras2020training ,
title = { Training Generative Adversarial Networks with Limited Data } ,
author = { Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila } ,
year = { 2020 } ,
eprint = { 2006.06676 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { jolicoeurmartineau2018relativistic ,
title = { The relativistic discriminator: a key element missing from standard GAN } ,
author = { Alexia Jolicoeur-Martineau } ,
year = { 2018 } ,
eprint = { 1807.00734 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { sinha2020topk ,
title = { Top-k Training of GANs: Improving GAN Performance by Throwing Away Bad Samples } ,
author = { Samarth Sinha and Zhengli Zhao and Anirudh Goyal and Colin Raffel and Augustus Odena } ,
year = { 2020 } ,
eprint = { 2002.06224 } ,
archivePrefix = { arXiv } ,
primaryClass = { stat.ML }
} @misc { yu2021dual ,
title = { Dual Contrastive Loss and Attention for GANs } ,
author = { Ning Yu and Guilin Liu and Aysegul Dundar and Andrew Tao and Bryan Catanzaro and Larry Davis and Mario Fritz } ,
year = { 2021 } ,
eprint = { 2103.16748 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

